分布式任务调度
在开发项目中,分布式任务调度是必不可少的,如 电商项目中的 订单定时任务,商户的每日清算 等。
Linux crontab轻量定时任务
1
2
3
4
5
| service crond start // 必须保证定时任务是开启的状态
crontab -e // 编辑定时任务
* * * * * echo "timer">/root/test.out
|
crontab表达式规则
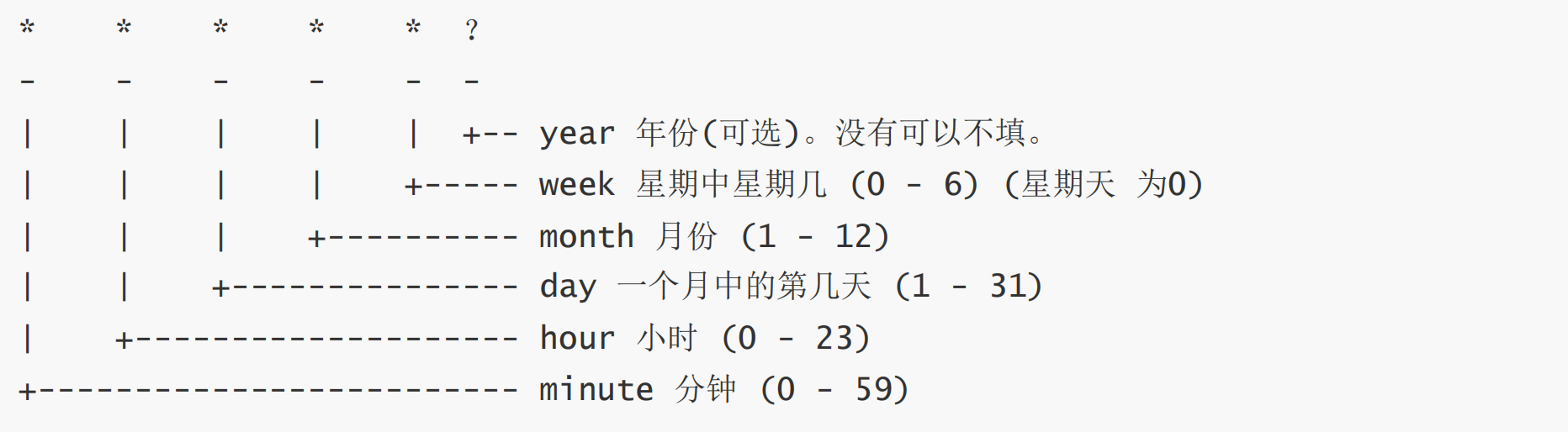
- 在Linux的crontab表达式只能精确到分钟,是没有秒的概念,但是在Java中是能精确到秒的。
crontab弊端
- 一般情况下是单机运行,如果单机挂了,定时任务也会跟着挂掉
- 如果服务器集群的话,定时任务不方便统一管理,需要单独对每台服务器进行定时任务管理
xxl-job实现分布式任务调度
为什么要用分布式任务调度系统?
- 如果在单机上进行定时任务的话,单机挂了,定时任务也会挂掉,如果采用分布式任务调度系统,则master机器挂掉了,系统会让其他机器进行任务调度
- 如:执行商户结算任务时,执行的节点宕机了,调度框架会安排其他节点 继续执行任务
单机定时任务的缺点
- 无法执行单次测试
- 当设置好定时任务后,推送到生产环境后,想立即执行一次是做不到的,必须等到定时器时间 到了之后才会触发该任务。
- 虽然说通过通过其他接口去调用该定时任务方法也可以触发,但是这会增加一些和业务逻辑无关的代码
- 更改执行时间麻烦
- 打包之后 如果想修改时间的话,就必须重新修改代码打包推送生产环境
- 关于异常和重试
- 一旦出现了异常的话并没有一个 补救措施,也没有 重试机制和通知机制。
- 无法暂停任务
- 定时任务执行到一半的时候,发现报错了 或者有其他异常想立即停止是做不到的,虽然可以通过开关状态来判断 该定时任务是否开启,但是这会增加一些和业务逻辑无关的代码
- 无法监控任务
- 无法对定时任务进行监控,查看任务执行情况
- 无法分片执行
- 如果需要对大量的数据进行分析或者对大量的用户进行推送的话,单机执行起来效率很低,无法进行分布式任务调度,让其他机器协同执行
- 存在重复执行的可能性
- 如果使用单机定时任务的话,集群中部署多台节点 可能存在 定时任务被多次执行的情况,并且无法保证每个节点的时间都一致,可能存在执行频率的问题。
目前实现分布式任务调度系统的框架有很多,国内用的较多的是是elasticjob和xxljob。elasticjob依赖于zookeeper进行分布式任务调度,而xxljob依赖于数据库,相对而言 xxljob 更加适用于轻量化项目开发。
xxl-job配置
控制后台服务端
下载xxj-job admin端源码
下面我们提供了2个地址下载,一个是 本地实验的版本,一个是 gitee仓库,根据需要下载。
gitee仓库:https://gitee.com/xuxueli0323/xxl-job?utm_source=alading&utm_campaign=repo
私人地址 2.4.1版本:https://files.javaxing.com/Java%08Demo/xxl-job-master.zip
导入SQL文件
SQL文件路径:xxl-job-master/doc/db/tables_xxl_job.sql
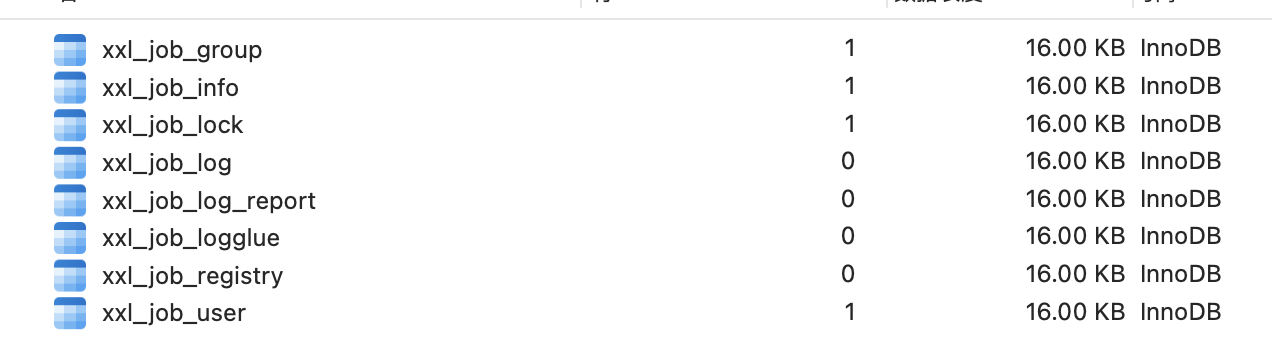
导入成功后看到有一个xxl-job的数据库,里面已经为我们创建好了一些表。
**配置 控制端 数据源 **
下载源码后导入到idea,配置 application.properties 数据源信息
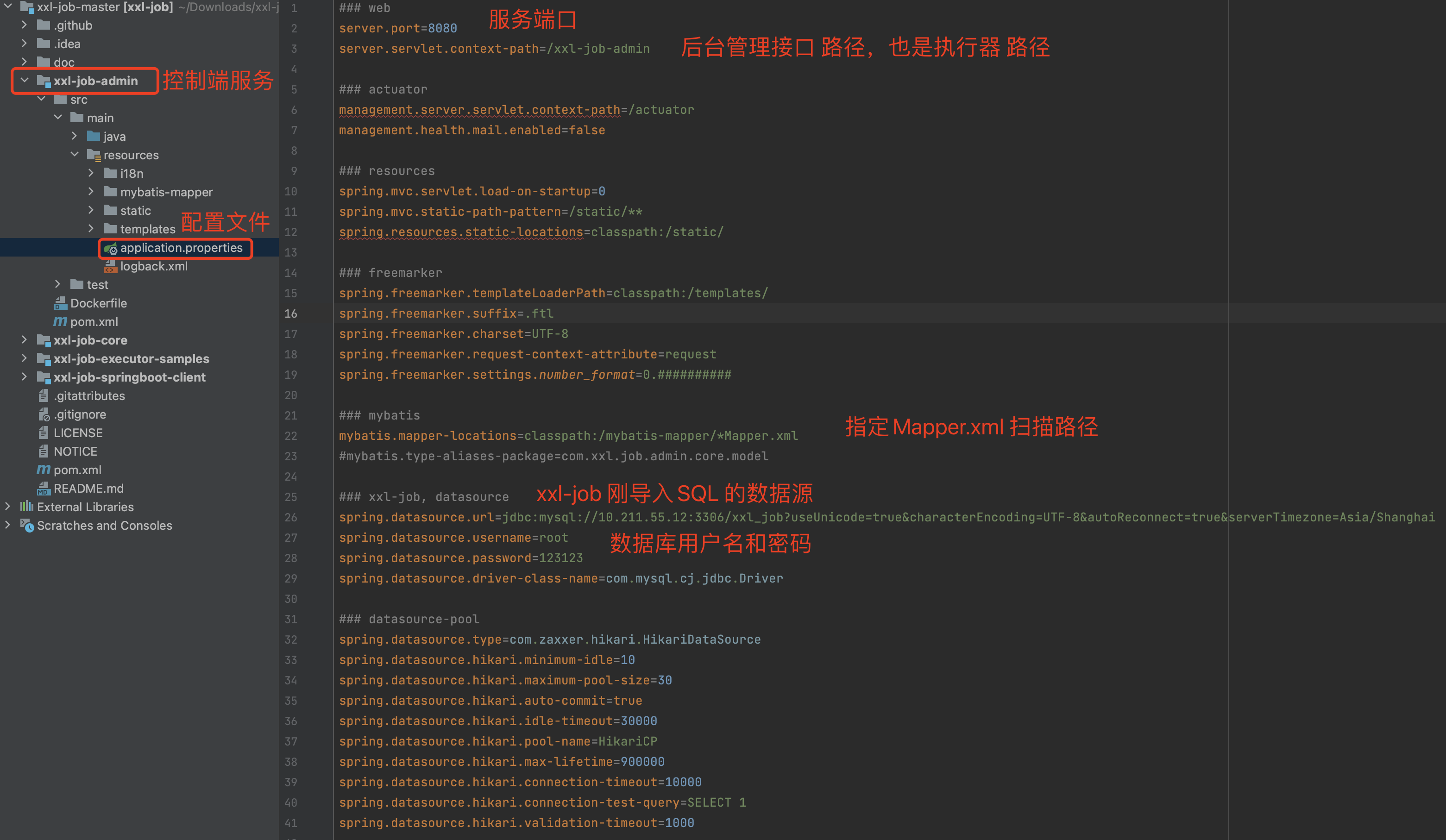
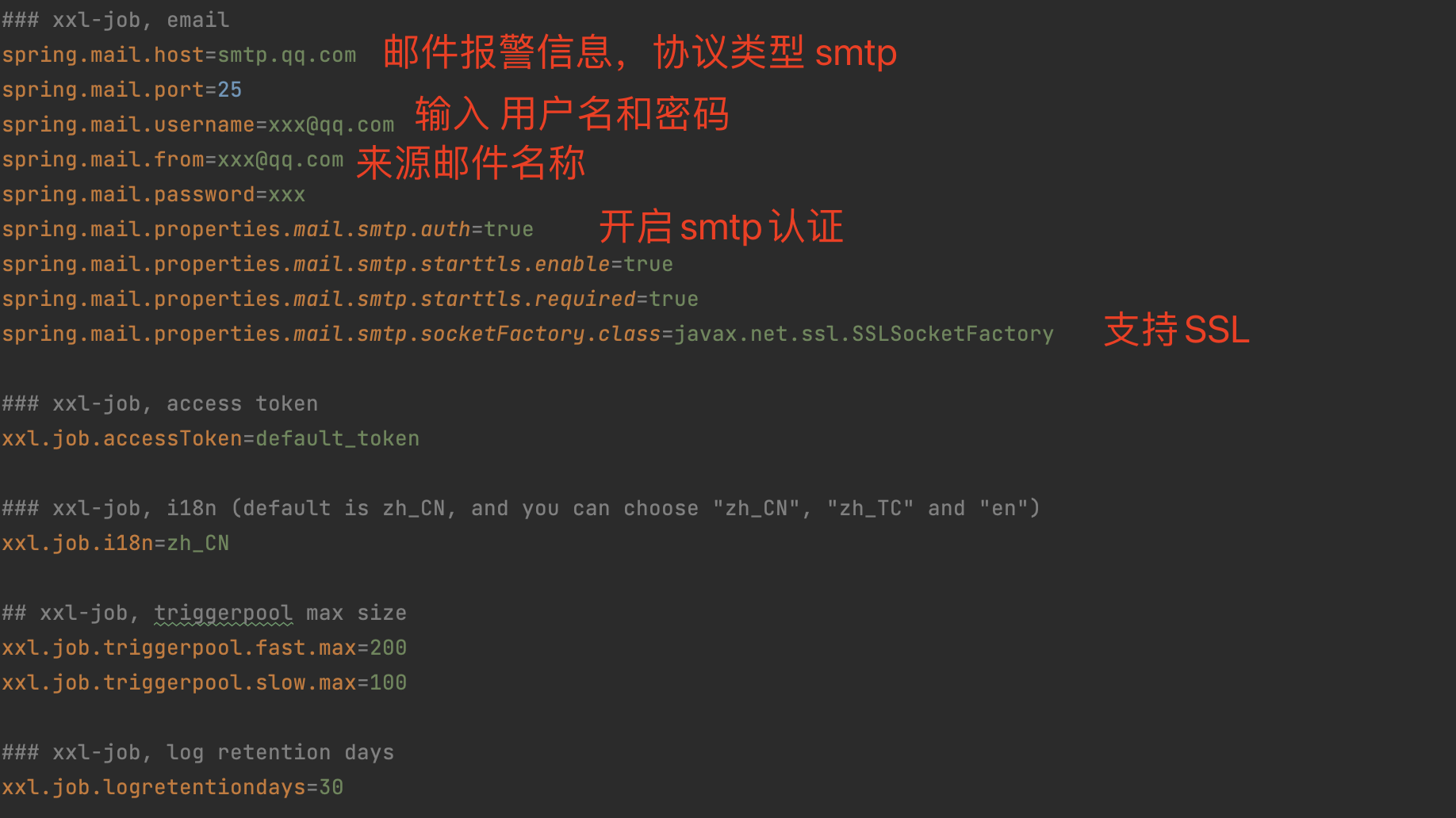
email 邮件告警配置
启动服务
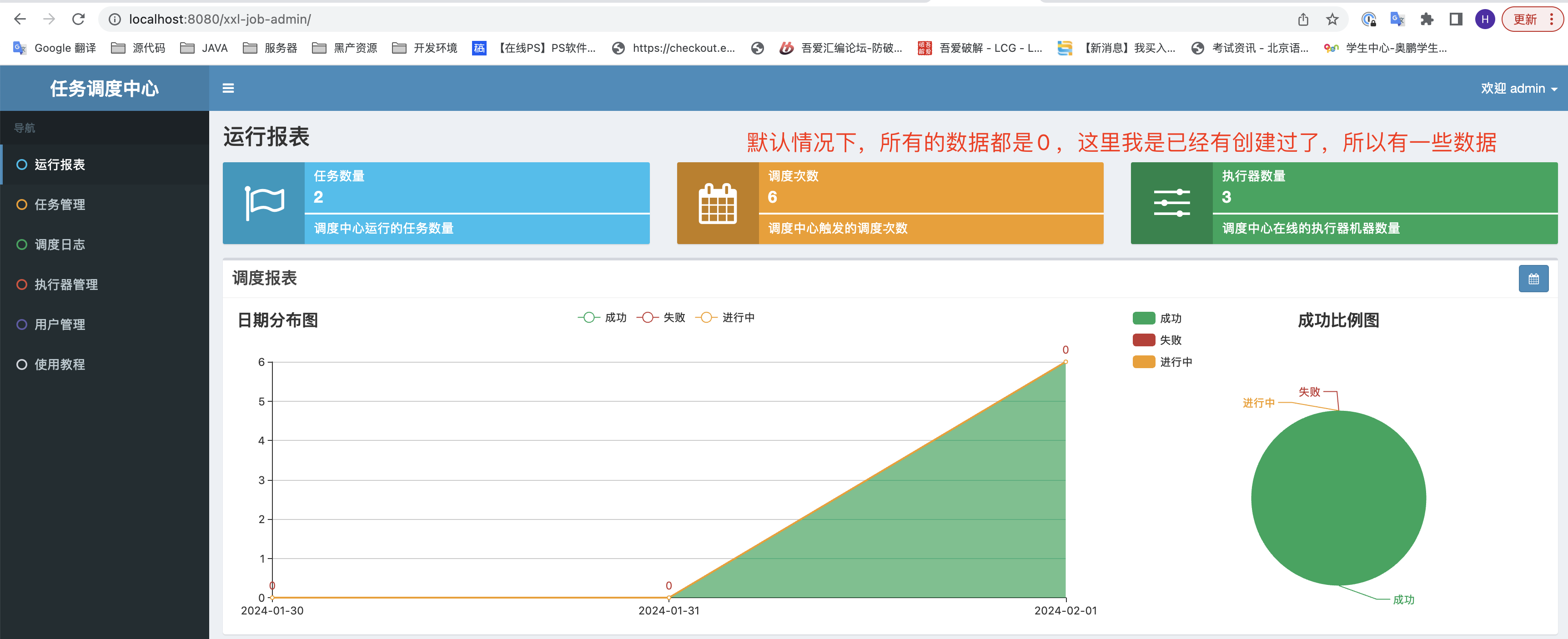
进入xxl-job 后台 http://localhost:8080/xxl-job-admin/
- 服务端口:server.port=8080
- 服务路径:server.servlet.context-path=/xxl-job-admin
创建执行器(集成到springBoot)
项目代码:https://files.javaxing.com/Java%08Demo/xxl-job-springboot-client.zip
流程:
- 创建一个maven工程,引入springBoot依赖
- 引入mysql、mybatis-plus、druid 依赖,完成数据源配置
- 引入 xxj-job依赖和配置文件
创建springBoot工程和数据源
引入依赖
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| <dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>2.6.2</version>
</dependency>
<dependency>
<groupId>com.xuxueli</groupId>
<artifactId>xxl-job-core</artifactId>
<version>2.4.1-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.3.2</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.2.3</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.29</version>
</dependency>
</dependencies>
|
application.yaml
1
2
3
4
5
6
7
8
9
10
11
12
| spring:
datasource:
type: com.alibaba.druid.pool.DruidDataSource
druid:
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: 123123
url: jdbc:mysql://10.211.55.12:3306/user?characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=false&useJDBCCompliantTimezoneShift=true&useLegacyDatetimeCode=false&serverTimezone=GMT%2B8&allowMultiQueries=true&allowPublicKeyRetrieval=true
mybatis-plus:
mapper-locations: classpath:/mapper/*Mapper.xml
|
设置mysql数据源,社会之mybatis-plus扫描mapper路径
配置xxl-job 执行器 config
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
| @Configuration
public class XxlJobConfig {
private Logger logger = LoggerFactory.getLogger(XxlJobConfig.class);
@Value("${xxl.job.admin.addresses}")
private String adminAddresses;
@Value("${xxl.job.accessToken}")
private String accessToken;
@Value("${xxl.job.executor.appname}")
private String appname;
@Value("${xxl.job.executor.address}")
private String address;
@Value("${xxl.job.executor.ip}")
private String ip;
@Value("${xxl.job.executor.port}")
private int port;
@Value("${xxl.job.executor.logpath}")
private String logPath;
@Value("${xxl.job.executor.logretentiondays}")
private int logRetentionDays;
@Bean
public XxlJobSpringExecutor xxlJobExecutor() {
logger.info(">>>>>>>>>>> xxl-job config init.");
XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();
xxlJobSpringExecutor.setAdminAddresses(adminAddresses);
xxlJobSpringExecutor.setAppname(appname);
xxlJobSpringExecutor.setAddress(address);
xxlJobSpringExecutor.setIp(ip);
xxlJobSpringExecutor.setPort(port);
xxlJobSpringExecutor.setAccessToken(accessToken);
xxlJobSpringExecutor.setLogPath(logPath);
xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);
return xxlJobSpringExecutor;
}
}
|
创建任务Handler
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
| @Component
public class SampleXxlJob {
private static Logger logger = LoggerFactory.getLogger(SampleXxlJob.class);
@Autowired
private SysUserService sysUserService;
@XxlJob("demoJobHandler")
public void demoJobHandler() throws Exception {
XxlJobHelper.log("一切执行正常");
}
@XxlJob("shardingJobHandler")
public void shardingJobHandler() throws Exception {
int shardIndex = XxlJobHelper.getShardIndex();
int shardTotal = XxlJobHelper.getShardTotal();
XxlJobHelper.log("分片参数:当前分片序号 = {}, 总分片数 = {}", shardIndex, shardTotal);
List<SysUser> userList = sysUserService.findAllByMod(shardTotal, shardIndex);
XxlJobHelper.log("当前分片分配的数据 {}", userList.toString());
}
}
|
我们一共创建了2个任务,一个简单任务,一个分片广播任务(让多个执行器节点 协同执行)。
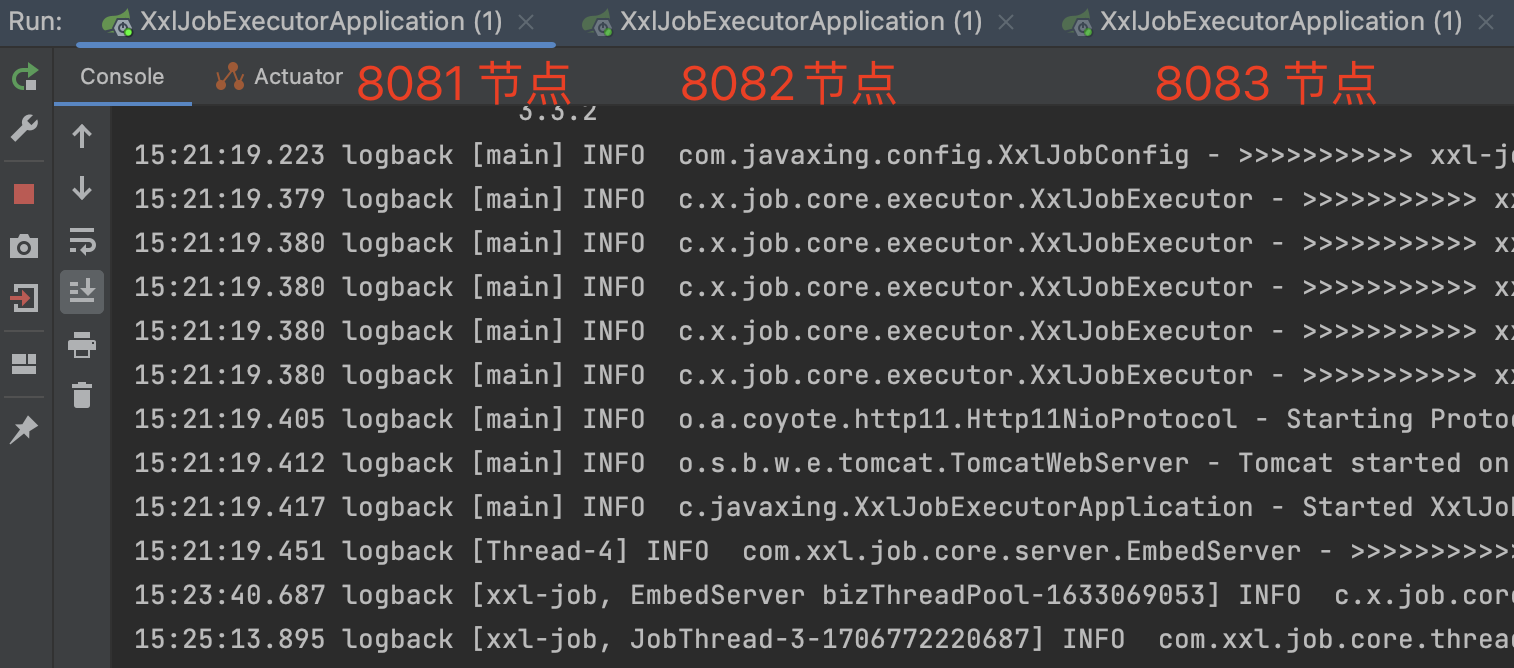
启动执行器客户端
控制面板创建执行器
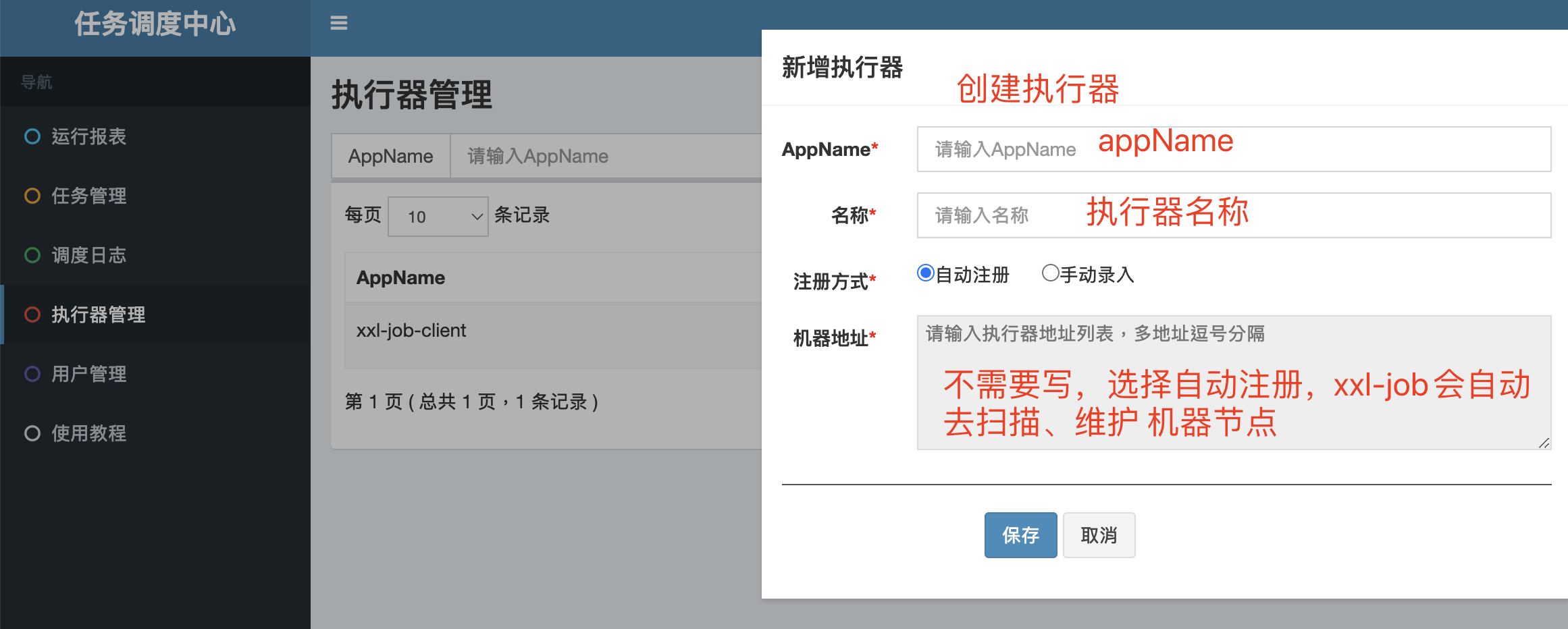
创建执行器的时候,需要写入appName 这个名字 是执行器客户端的appName,可以理解为 集群名称。
执行器的appName 就是 client 客户端的appName
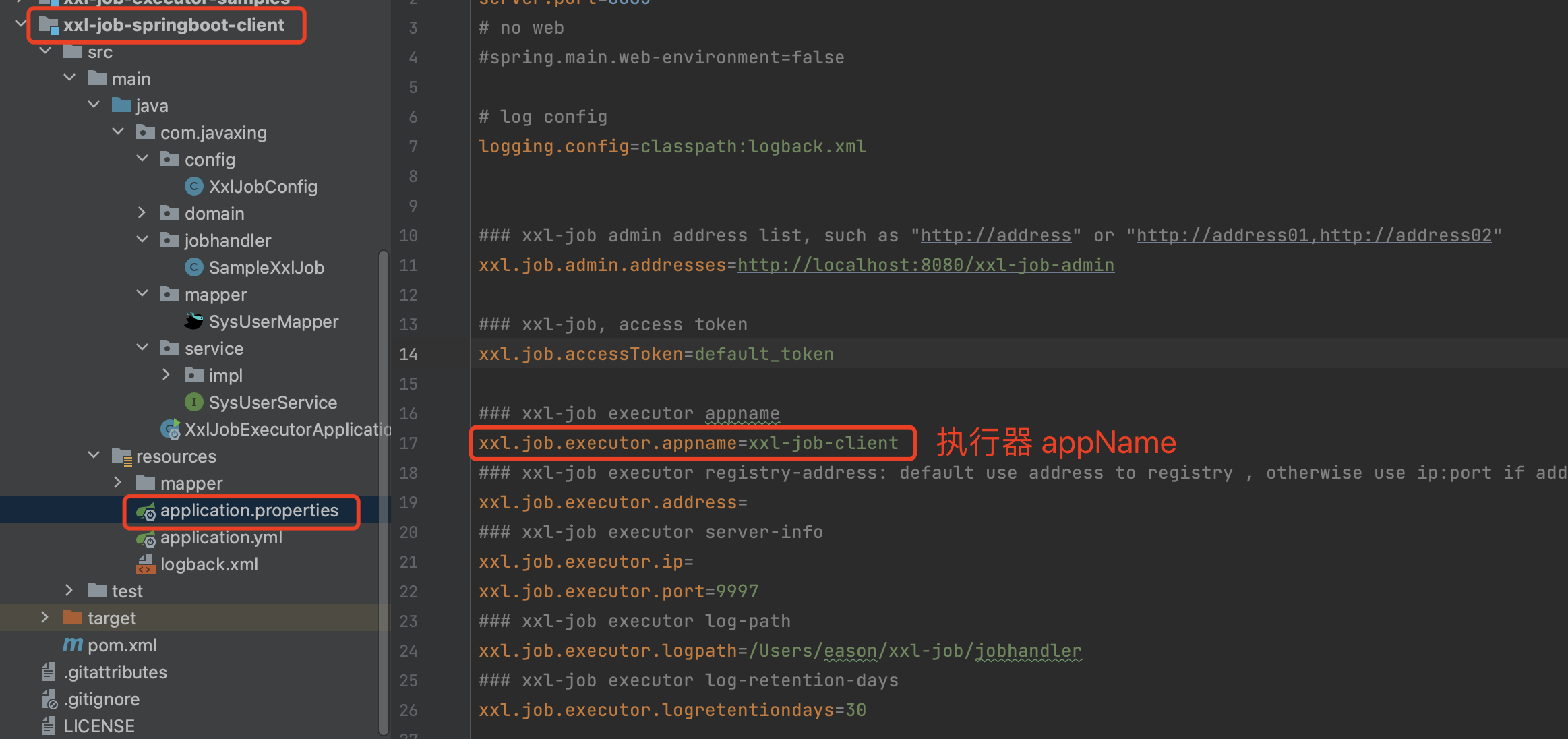
Log retention 日志保存时间,单位是天
执行器创建成功之后,会在一定的时间内发现并维护节点。
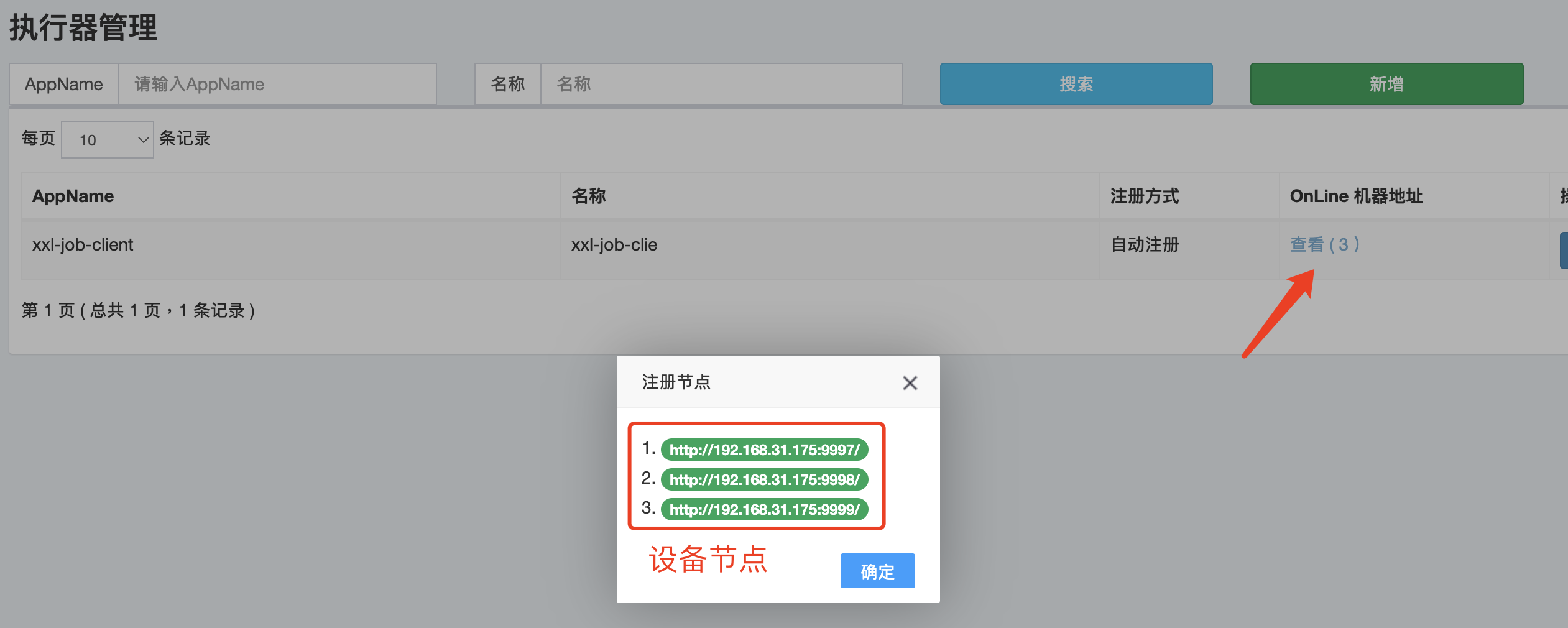
xxl-job任务调度
简单任务
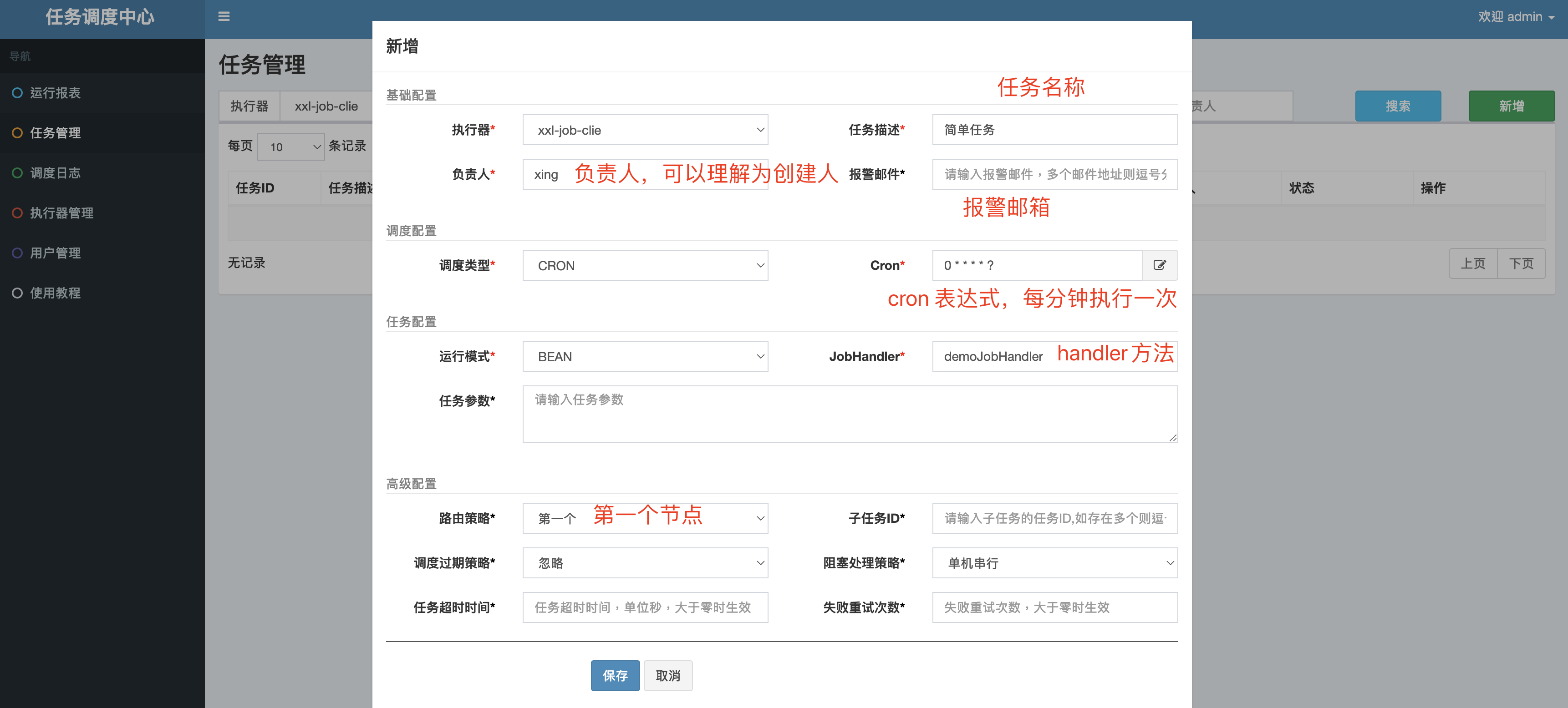
路由策略(只显示常用的):
- 第一个:设备列表 第一个节点
- 最后一个:设备列表 最后一个节点
- 轮询:轮询设备列表节点
- 随机:设备列表随机执行
- 分片广播:让多个执行器节点 协同执行 同一个任务
任务管理列表
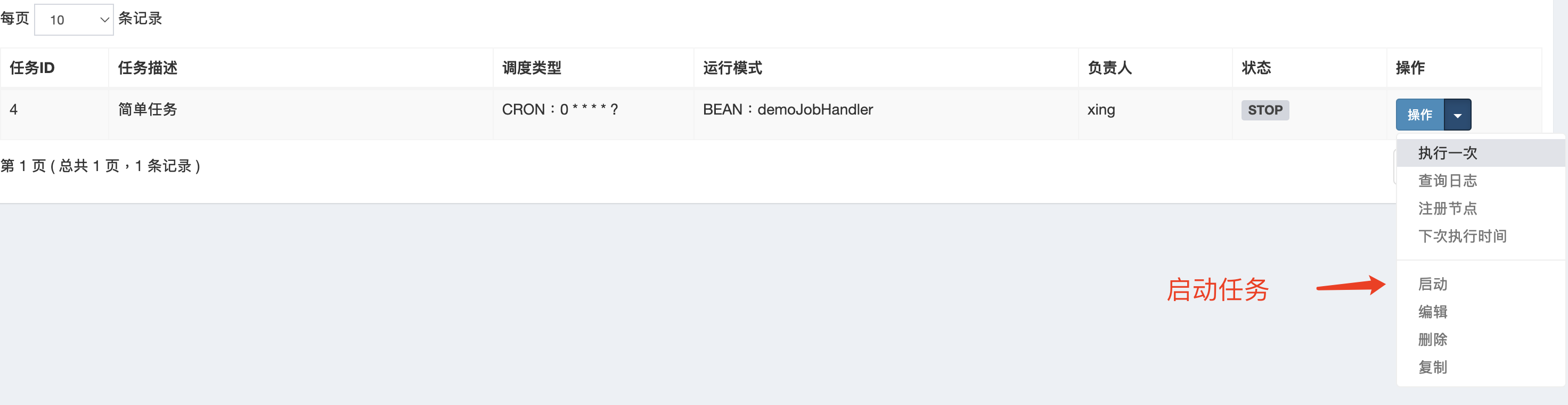
启动任务
调度日志
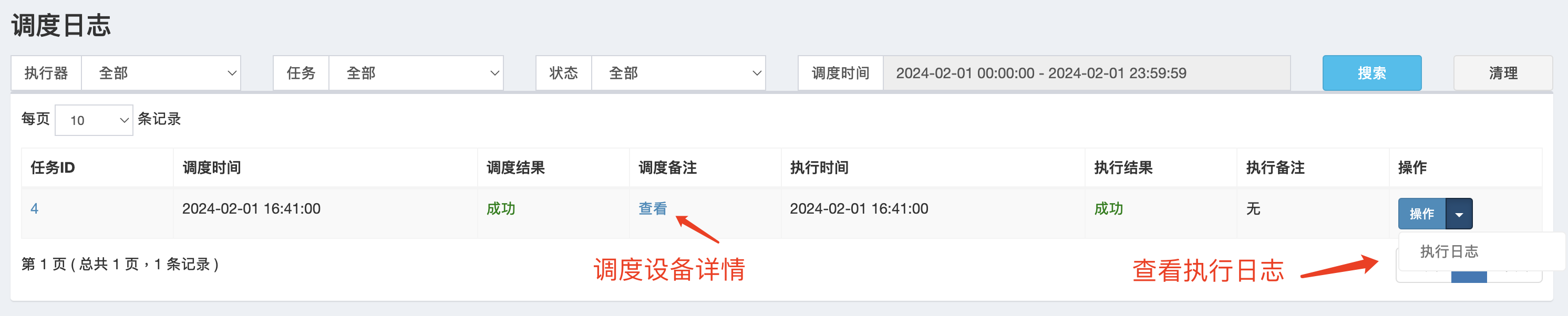
调度设备信息
我们可以通过调度日志 查看调度设备信息,可以清晰的看到 执行的节点,和调度策略。
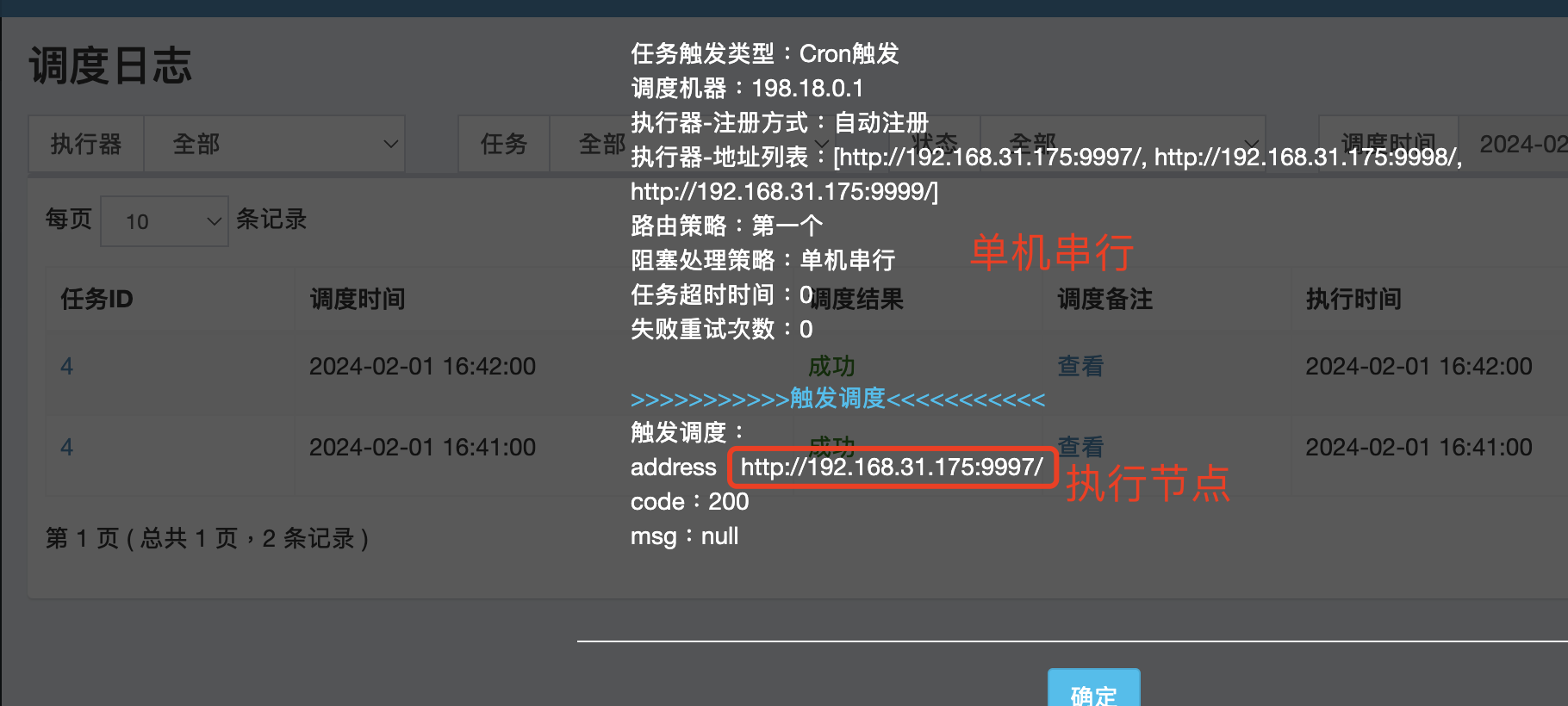
详细的执行日志
分片任务
执行器 编写 shardingJobHandler
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
@XxlJob("shardingJobHandler")
public void shardingJobHandler() throws Exception {
int shardIndex = XxlJobHelper.getShardIndex();
int shardTotal = XxlJobHelper.getShardTotal();
XxlJobHelper.log("分片参数:当前分片序号 = {}, 总分片数 = {}", shardIndex, shardTotal);
List<SysUser> userList = sysUserService.findAllByMod(shardTotal, shardIndex);
XxlJobHelper.log("当前分片分配的数据 {}", userList.toString());
}
|
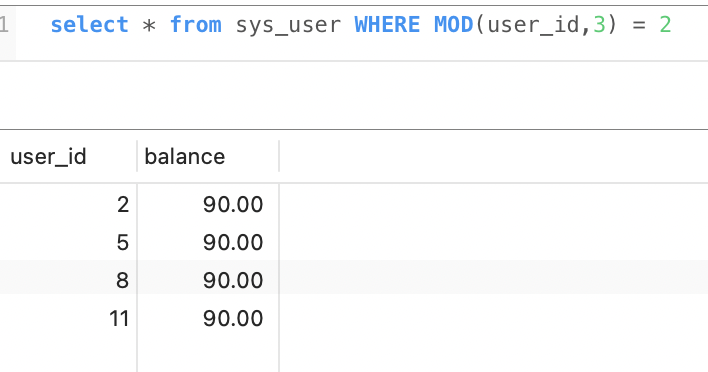
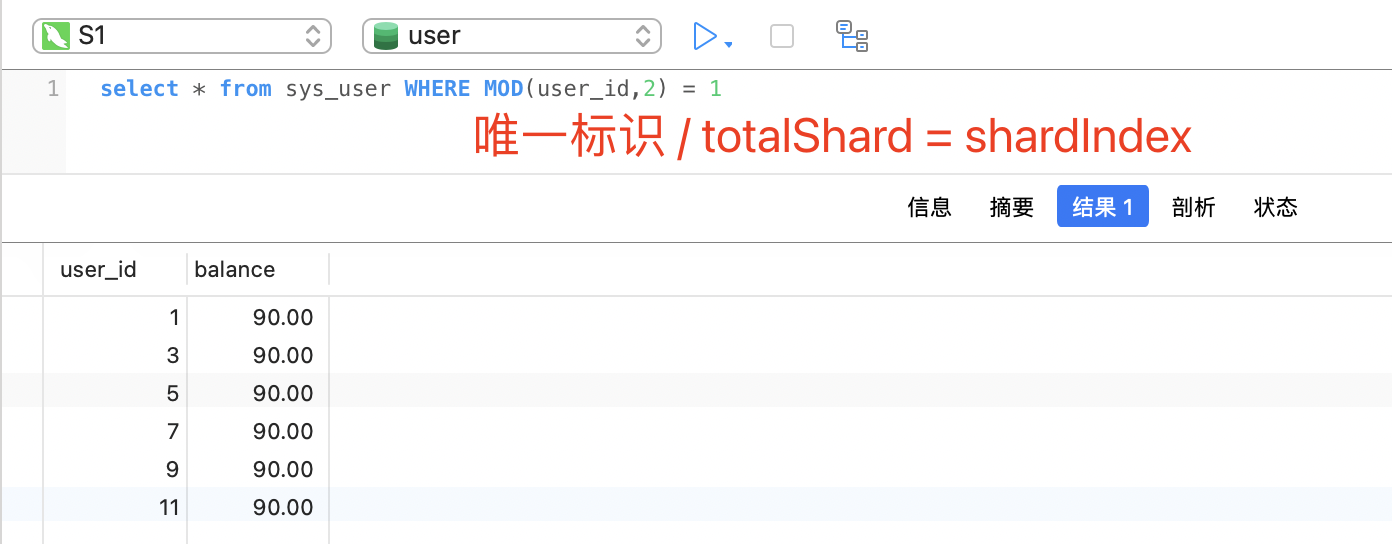
执行任务时,会先获取出 总分片数量,以及当前分片index,MySQL中查询数据时 会进行取模,公示如下:
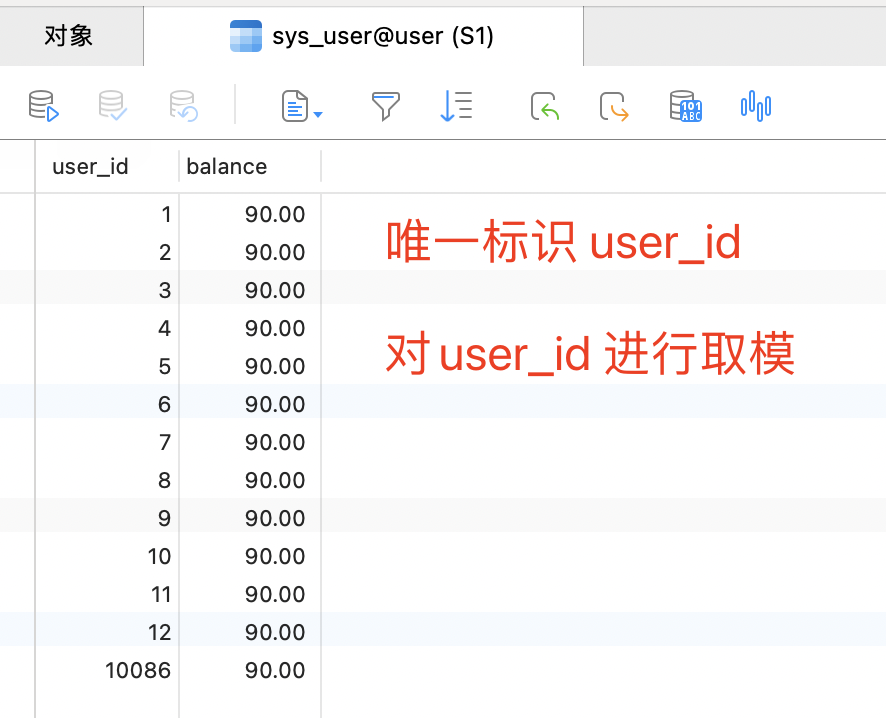
MOD(id, shardTotal) = shardIndex ; 取模MOD(唯一标识 , 分片总数) = 分片index
select * from sys_user WHERE MOD(user_id,2) = 1
取模结果:
后台新增任务
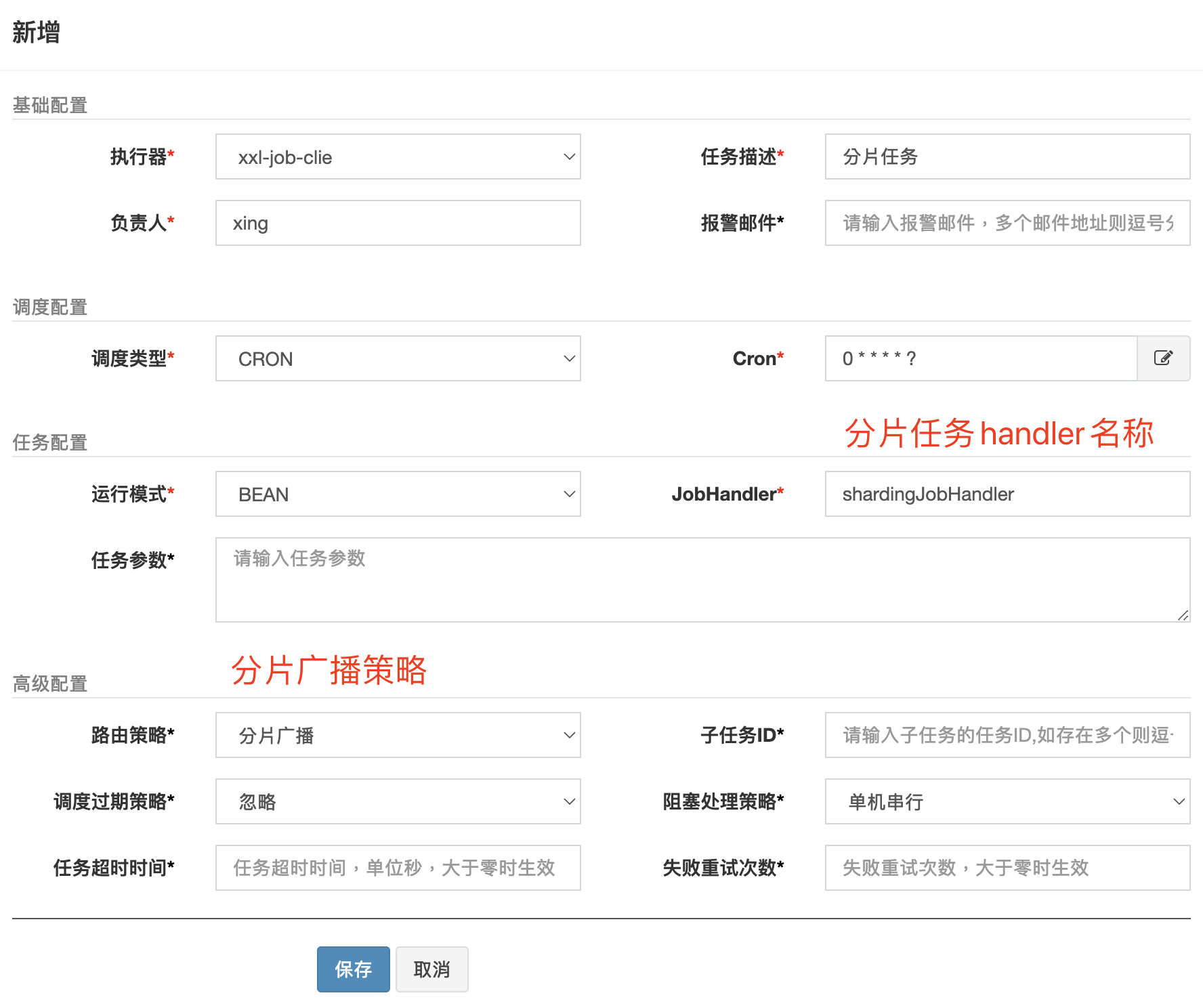
查看新增后的分片任务

执行分片任务



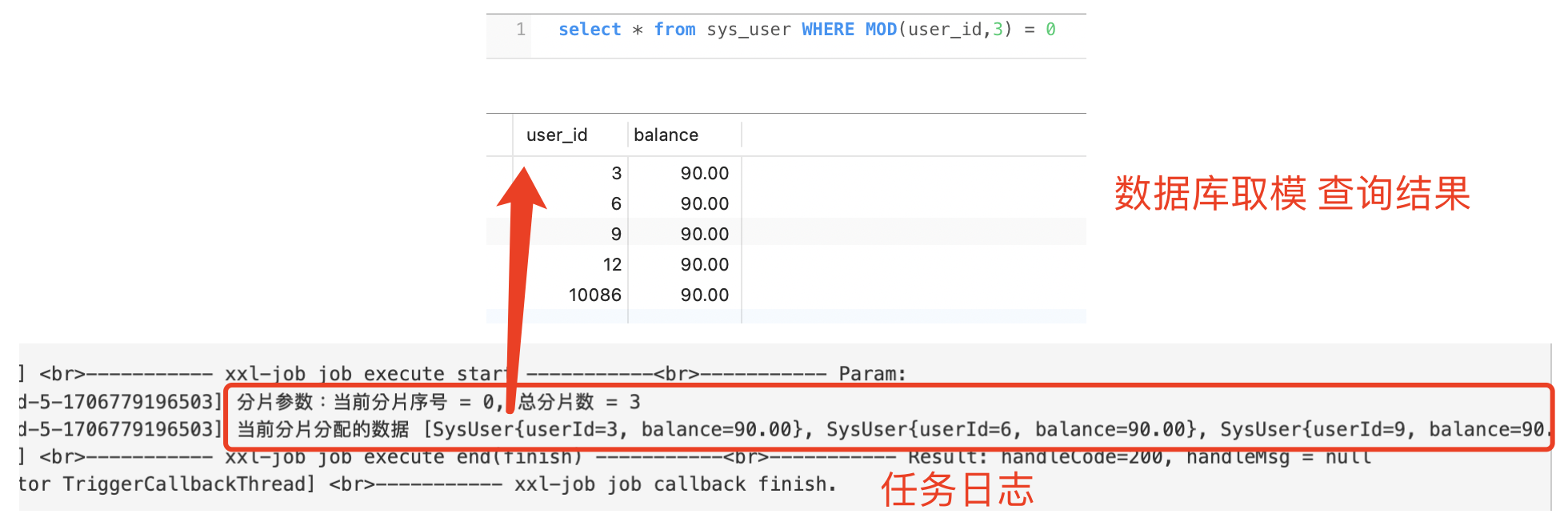
xxj-job执行分片任务时,会广播所有的执行器的节点,每个节点都会收到通知并执行任务。在执行任务的时候,为了避免重复执行,会对要执行的数据唯一标识 进行取模,如 用户表,每个分片通过唯一标识取模 拿到的数据都不一样。
MOD(id, shardTotal) = shardIndex ; 取模MOD(唯一标识 , 分片总数) = 分片index
`select * from sys_user WHERE MOD(user_id,3) = 0
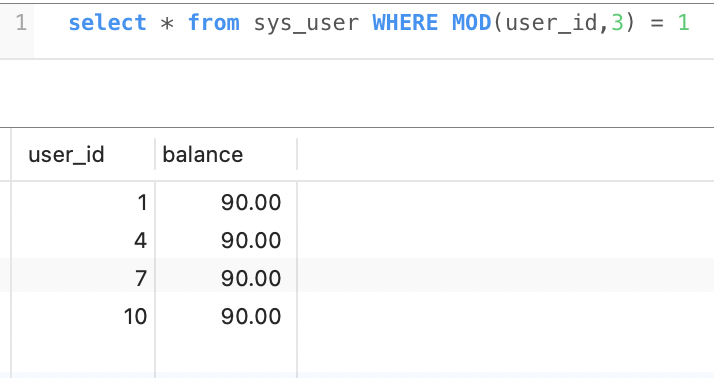
select * from sys_user WHERE MOD(user_id,3) = 1

select * from sys_user WHERE MOD(user_id,3) = 2