MongoDB多文档事务
Mongo DB多文档事务
事务是数据库必备一项能力,目的是为了确保数据的可靠性和一致性。
事务包含了一系列的数据库读写操作,要确保原子性 要么全部命令都执行成功要么全部都不执行。
举个常见的电商例子:用户下单付款后,应当创建订单后 同时也扣减库存,他们一系列行为 视为 一个事务。
事务必须包含四个特性 ACID:
- 原子性(atomicity)
- 整个事务视为一个整体,要么全部命令都执行成功要么全部都不执行。
- 一致性(consistency)
- 事务应确保数据库的状态从一个一致状态转变为另一个一致状态
- 隔离性(isolation)
- 事务之间相互隔离,互不影响
- 持久性(durability)
- 对已经提交的事务修改必须是永久性的
1. MongoDB多文档事务
MongoDB支持在单个文档内 使用内嵌文档和数组,不需要太频繁的跨文档和集合,可以在一定程度上确保原子性,减少对事务的依赖。
MongoDB的事务能不用,尽量不用,合理的设计文档模型,可以规避掉大部分使用事务的场景。
使用事务的原则
- 能不使用事务就尽量不用事务
- 合理的设计文档模型,可以规避掉大部分使用事务
- 不要使用过大的事务(尽量控制在 1000 个文档更新以内)
- 一个事务超时时间60秒,超过60秒事务会自动结束,避免使用过大的事务,否则任务还没有结束 事务先结束
- 当必须使用事务时,尽可能让涉及事务的文档分布在同一个分片上,这将有效地提高效率
MongoDB对事务支持
| 事务属性 | 支持程度 |
|---|---|
| Atomocity 原子性 | 单表单文档 : 1.x 就支持 复制集多表多行:4.0 分片集群多表多行:4.2 |
| Consistency 一致性 | 一致性 通过2个方法来实现,writeConcern, readConcern |
| Isolation 隔离性 | readConcern |
| Durability 持久性 | Journal and Replication |
Java 事务使用方法
1 | try (ClientSession clientSession = client.startSession()) { |
1)writeConcern 写事务
writeConcern 决定一个写操作落到多少个节点上才算成功。
语法格式:
1 | { w: <value>, j: <boolean>, wtimeout: <number> } |
- w: 数据写入到多少个节点才向用客户端确认
- {w: 0} 对客户端的写入不需要发送任何确认,适用于性能要求高,但不关注正确性的场景
- {w: 1} 默认为1,数据写入到Primary就向客户端发送确认
- {w: majority} 数据写入到副本集大多数成员后向客户端发送确认,适用于对数据安全性要求比较高的场景,该选项会降低写入性能
- j: 写入操作的journal持久化后才向客户端确认
- 默认为{j: false},如果要求Primary写入持久化了才向客户端确认,则指定该选项为true
- wtimeout: 写入超时时间,仅w的值大于1时有效。
- 如果指定了{w}时,如 w = 3,数据需要成功写入3个节点才能正常返回。如果写入过程中节点故障了,就会一直无法返回结果。为了避免这种情况,我们可以指定最长超时时间。如果超过了wtimeout时间没有返回,就会认为写入失败。
写入测试
1 | # 成功写入数据到一半以上的从节点 才向客户端发送确认 |
writeConcern注意事项
虽然写入的节点越多数据越安全,但是为了降低对性能的影响,推荐重要数据用 {w: “majority”},普通数据用 {w: 1} 以确保性能。
不要设置 writeConcern 等于总节点数,因为一旦有一个节点故障,所有写操作都将失败;
2)read读取机制
在读取数据的过程中我们需要关注以下两个问题:
- 从哪里读?
- 什么样的数据可以读?
第一个问题是是由 readPreference 来解决,第二个问题则是由 readConcern 来解决。
readPreference 读偏好
readPreference决定使用哪一个节点来发起的读请求。 可选值如下:
- primary: 只选择主节点,默认模式;
- primaryPreferred:优先选择主节点,如果主节点不可用则选择从节点;
- secondary:只选择从节点;
- secondaryPreferred:优先选择从节点, 如果从节点不可用则选择主节点;
- nearest:根据客户端对节点的 Ping 值判断节点的远近,选择从最近的节点读取。
合理的 ReadPreference 可以极大地扩展复制集的读性能,降低访问延迟。
举个实际场景例子:
- 用户下单后立马跳转到订单详情页
- 优先使用 primary/primaryPreferred,避免从节点 还没有同步 主节点订单数据
- 用户 查询已经存在的订单
- 优先使用 secondary/secondaryPreferred,查询订单通常对时效性要求不高
- 生成报表
- 优先使用 secondary 报表对时效性要求不高,但资源需求大,可以在从节点单独处理,避免对线上用户造成影响;
readPreference 配置
- 通过 MongoDB 的连接串参数(数据源上修改)
mongodb://host1:27107,host2:27107,host3:27017/?replicaSet=rs0&readPre ference=secondary
- 通过 MongoDB 驱动程序 API(springBoot)
MongoCollection.withReadPreference(ReadPreference readPref)
- Mongo Shell
db.collection.find().readPref( "secondary" )
readPreference模拟实验
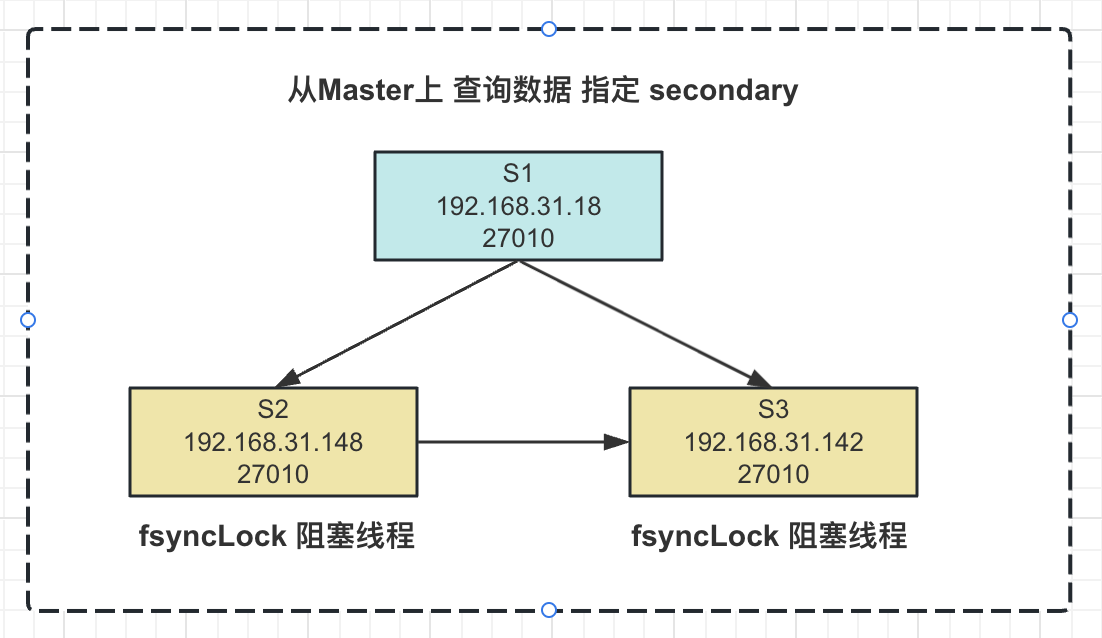
实验效果:我们阻塞2个从节点,然后在Master插入一条数据 name = ‘李四’ ,由于阻塞的问题,该数据并不会同步给其余的2个从节点。
我们可以在master上查询时,指定 通过 primary 还是secondary 查询数据。
- 阻塞2个从节点
1 | rs0:SECONDARY> rs.secondaryOk() |
- 登录shell 并 插入一条数据
1 | 登录用户,必须以--host rs0/localhost:port 复制集名称/主机名/端口号 登录 |
必须以–host rs0/localhost:port 复制集名称/主机名/端口号登录,如果不指定复制集名称直连的话 会查到数据,无法完成实验
- 指定 查询节点类型
1 | 通过从节点查询数据,由于2个从节点都被阻塞了无法同步到数据,所以是查询不到数据的 |
Tag 标签
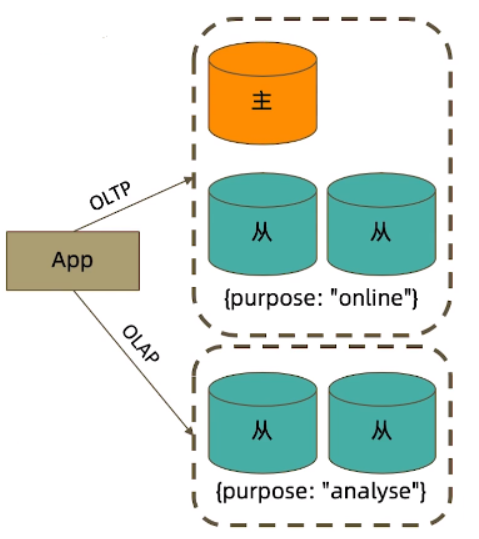
readPreference只能控制 使用 主节点还是从节点读取,而Tag可以控制 我们想要读取哪台节点的数据。
我们可以把复制集中的节点打上标签,在查询的时候 可以指定走响应标记的节点 进行查询。
举个例子:
一共有5个节点,1个主节点4个从节点。3个节点用于线上服务(online),2个节点用于数据报表分析、日志分析等(analyse)。
- 线上服务 打上标签:{purpose: “online”}
- 数据报表 打上标签:{purpose: “analyse”}
在线应用走online标签的节点, 做日志分析、数据报表走analyse标签的节点 查询数据。
添加标签
1 | conf = rs.conf() |
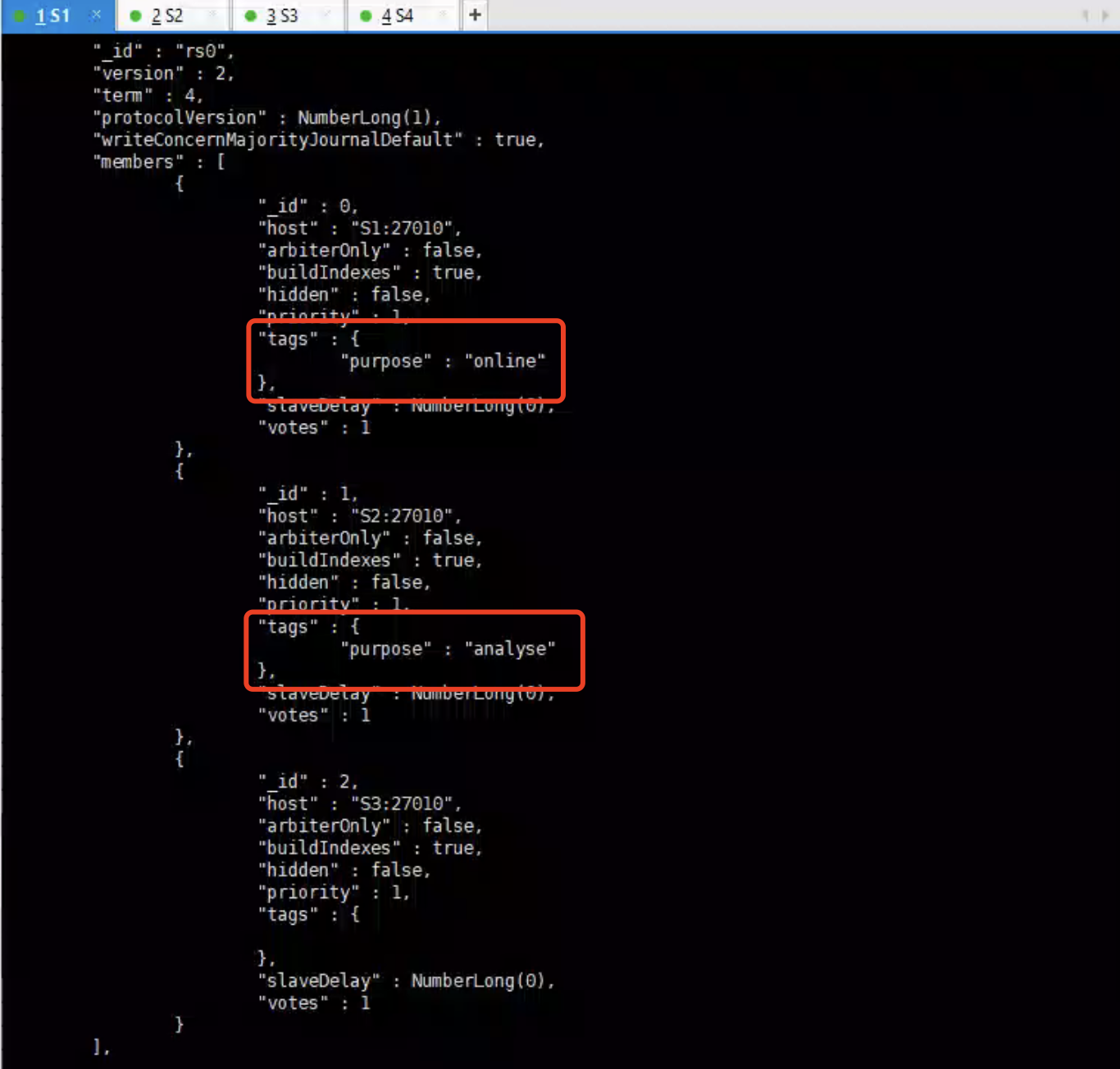
通过标签查询数据
1 | rs0:PRIMARY> db.users.find({}).readPref( "secondary", [ {purpose: "analyse"} ] ) |
查询的时候 指定走 从节点并且 从具有绑定analyse标签的节点上查询数据
使用tag注意事项
- 查询数据时,如果指定的TAG中没有可用节点,则会读取失败。
- 为了避免没有可用节点而失败,应当确保 tag中有多个节点可以做冗余
- 使用tag应当结合 节点优先级,选举权来考虑,如:做日志分析、报表分析的不应该成为主节点(priority = 0 不具备选举权)
readConcern
在 readPreference 选择了指定的节点后,readConcern 决定这个节点上的数据哪些是可读的。可选值有:
available:读取所有可用的数据;
local:读取所有可用且属于当前分片的数据;
majority:读取在大多数节点上提交完成的数据;
- 可以有效的避免脏读,性能较低但是却比较安全可靠
- 使用majority 只能查询到已经被多数节点确认过的数据
linearizable:可线性化读取文档,仅支持从主节点读;
snapshot:读取最近快照中的数据,仅可用于多文档事务;
在复制集中 local 和 available 是没有区别的,只有在一种情况下会出现区别:
当shard1 进行chunk迁移给shard2时,在迁移还没有完全结束之前,config 服务器上 是不会标记 该chunk 属于shard2的,那么使用local的话 在shard2上就会查不到该数据。
在 主节点读取数据时候,默认采用:local 。 在 从节点读取时,默认avaliable。
测试readConcern 命令
1 | replication: |
shell 命令 设置readConcern
1 | rs0:PRIMARY> db.user.insert({count:10}) |
如何安全的读写分离
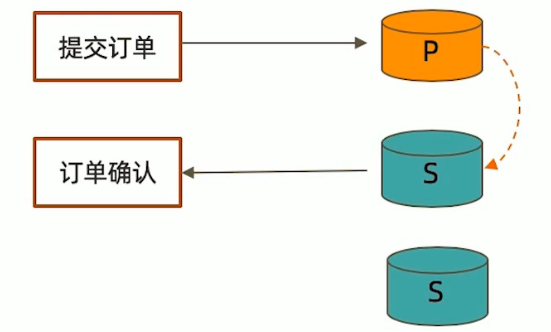
电商场景:
- 订单数据写入到primary
- 立即从secondary读取数据,如果secondary没有同步到那条数据的话,就会 查不到数据
如何才能确保 百分百读取到写入的数据?
正常的方式可能读取不到刚写入的订单
1 | db.orders.insert({oid:101,sku:"kite",q:1}) |
写入数据到primary后,立刻从secondary查询数据 很可能会查不到
使用writeConcern+readConcern majority来解决
1 | db.orders.insert({oid:101,sku:"kite",q:1},{writeConcern:{w:"majority"}}) |
1、writeConcern:只有写入一半以上的节点才能返回确认
2、readConcern majority:读取在大多数节点上提交完成的数据
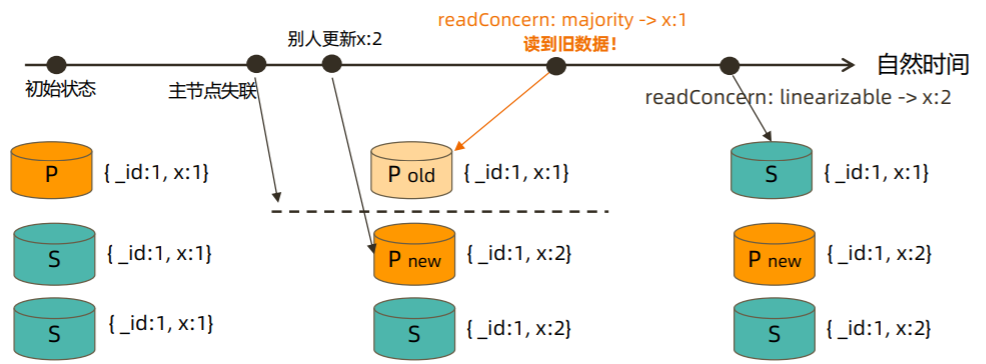
linearizable
只读取大多数节点确认过的数据。和 majority 最大差别是保证绝对的操作线性顺序
- 在写操作自然时间后面的发生的读,一定可以读到之前的写
- **只对读取单个文档时有效; **
- 可能导致非常慢的读,因此总是建议配合使用 maxTimeMS;
snapshot
{readConcern: “snapshot”} 只在多文档事务中生效。将一个事务的 readConcern 设置为 snapshot,将保证在事务中的读:
- 不出现脏读;
- 不出现不可重复读;
- 不出现幻读。
因为所有的读都将使用同一个快照,直到事务提交为止该快照才被释放。
小结
- available:读取所有可用的数据
- local:读取所有可用且属于当前分片的数据,默认设置
- majority:数据读一致性的充分保证,可能你最需要关注的
- linearizable:增强处理 majority 情况下主节点失联时候的例外情况
- snapshot:最高隔离级别,接近于关系型数据库的Serializable
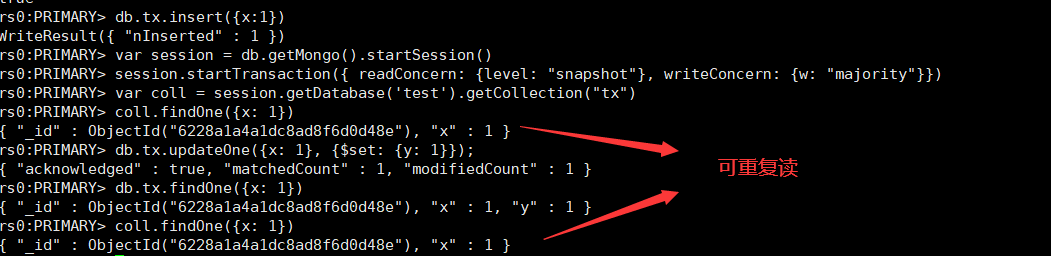
事务隔离级别
- 事务完成前,事务外的操作对该事务所做的修改不可访问
1 | db.tx.insertMany([{ x: 1 }, { x: 2 }]) |
- 如果事务内使用 {readConcern: “snapshot”},则可以达到可重复读 Repeatable Read
1 | var session = db.getMongo().startSession() |
事务超时
在执行事务的过程中,如果操作太多,或者存在一些长时间的等待,则可能会产生如下异常:
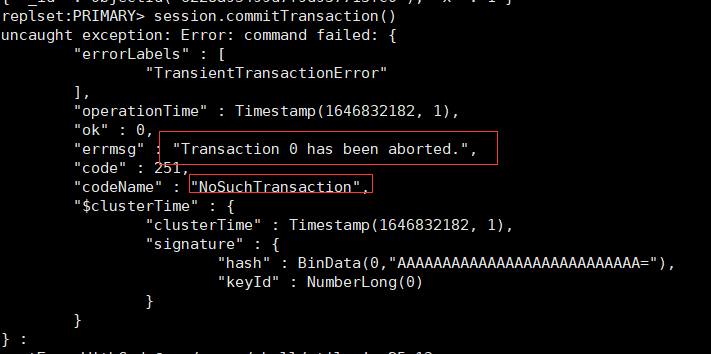
原因在于,默认情况下MongoDB每个事务1分钟超时,如果在该时间内没有提交,就会强制将其终止。该超时时间可以通过transactionLifetimeLimitSecond变量设定。
事务写机制
MongoDB 的事务错误处理机制不同于关系数据库:
- 当一个事务开始后,如果事务要修改的文档在事务外部被修改过,则事务修改这个 文档时会触发 Abort 错误,因为此时的修改冲突了。 这种情况下,只需要简单地重做事务就可以了;
- 如果一个事务已经开始修改一个文档,在事务以外尝试修改同一个文档,则事务以外的修改会等待事务完成才能继续进行。
写冲突测试
开3个 mongo shell 均执行下述语句
1 | var session = db.getMongo().startSession() |
窗口1: 正常结束
1 | coll.updateOne({x: 1}, {$set: {y: 1}}) |
窗口2: 异常 – 解决方案:重启事务
1 | coll.updateOne({x: 1}, {$set: {y: 2}}) |
窗口3:事务外更新,需等待
1 | db.tx.updateOne({x: 1}, {$set: {y: 3}}) |
注意事项
- 可以实现和关系型数据库类似的事务场景
- 必须使用与 MongoDB 4.2 兼容的驱动;
- 事务默认必须在 60 秒(可调)内完成,否则将被取消;
- **涉及事务的分片不能使用仲裁节点; **
- 事务会影响 chunk 迁移效率。正在迁移的 chunk 也可能造成事务提交失败(重试 即可);
- **多文档事务中的读操作必须使用主节点读; **
- readConcern 只应该在事务级别设置,不能设置在每次读写操作上。
2. SpringBoot中实现事务
1)MongoDB 事务底层逻辑
1 | /** |
底层逻辑和MySQL 事务差不多,一共分为以下几个步骤:
- 创建MongoClient 客户端,获取集合实例对象
- 创建事务管理器 TransactionOptions
- 使用try捕获并开启事务 clientSession.startTransaction
- 执行业务逻辑 … … 如果出错了就走异常分支 进行回滚事务
- 使用事务管理器 提交事务,如果提交失败了 就执行回滚事务 clientSession.abortTransaction()
实验测试
数据插入前,emp表空空如也

插入成功
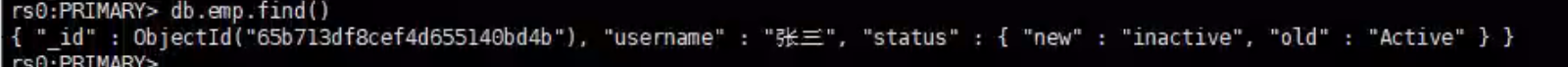
模拟插入失败的情况
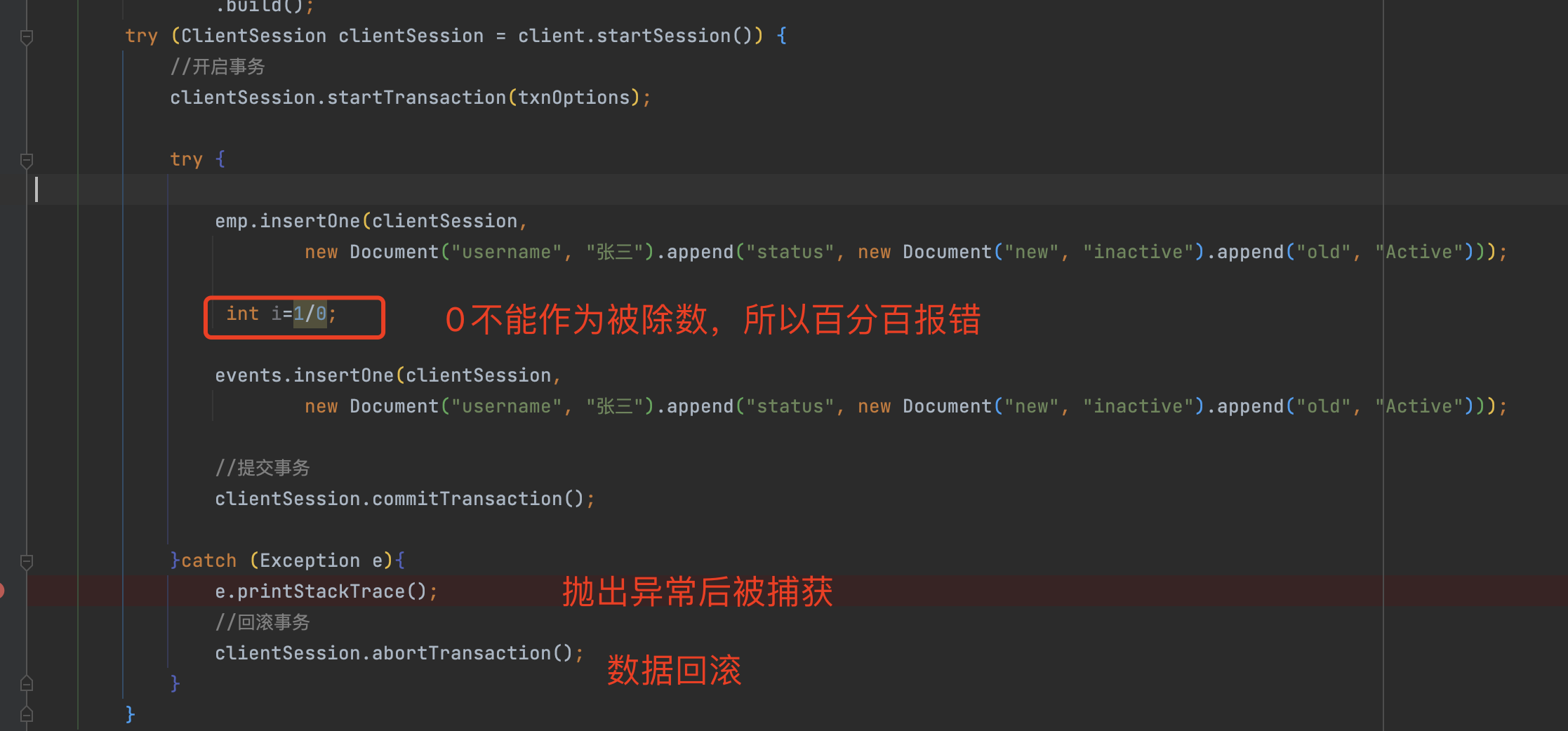

2)注解声明式事务
配置事务管理器
创建事务管理器并注入spring bean管理
1 |
|
@Transactional 本地事务
配置事务管理器后,使用Mongo DB事务的话 只需要在方法上面增加@Transactional注解就可以了,和MySQL本地事务一样的方法。
1 | package com.javaxing.service; |
测试事务
1 |
|
插入之前 查询数据,集合时空的:

成功插入数据后再次查询:

模拟异常的情况 再次插入数据会报错,java会捕获异常 进行事务回滚:
int i=1/0;






