MongoDB 高可用之分片集群
分片集群架构
1. 分片概念
分片是指将 数据进行水平切分后,存储在不同服务器上。等同于MySQL的水平分片,如:
单节点只能存储1T数据,我们进行水平分片 分成2份存储在不同服务器上,就可以写热点分散并且可以存储2T的数据,设备可以无限扩展。而复制集不论怎么扩大,所有节点始终都是全量存储数据。
什么情况下要进行水平分片?
- 存储数据已经超过单机存储限制
- 即便是复制集集群,不论是Primary还是Secondary都是全量存储数据的,都会存在单机的存储瓶颈
- 活跃的数据集已经超过了单机内存限制
- MongoDB默认会将60%的数据存储在内存缓存中,如果活跃的数据超过了60%的话,其余数据会从硬盘读取数据(影响性能)
- 写IO达到了瓶颈
- 一个复制集只能有一个Primary节点(只有Primary可以写入数据),如果Primary节点写入IO达到了瓶颈,那么就会影响集群写入的性能
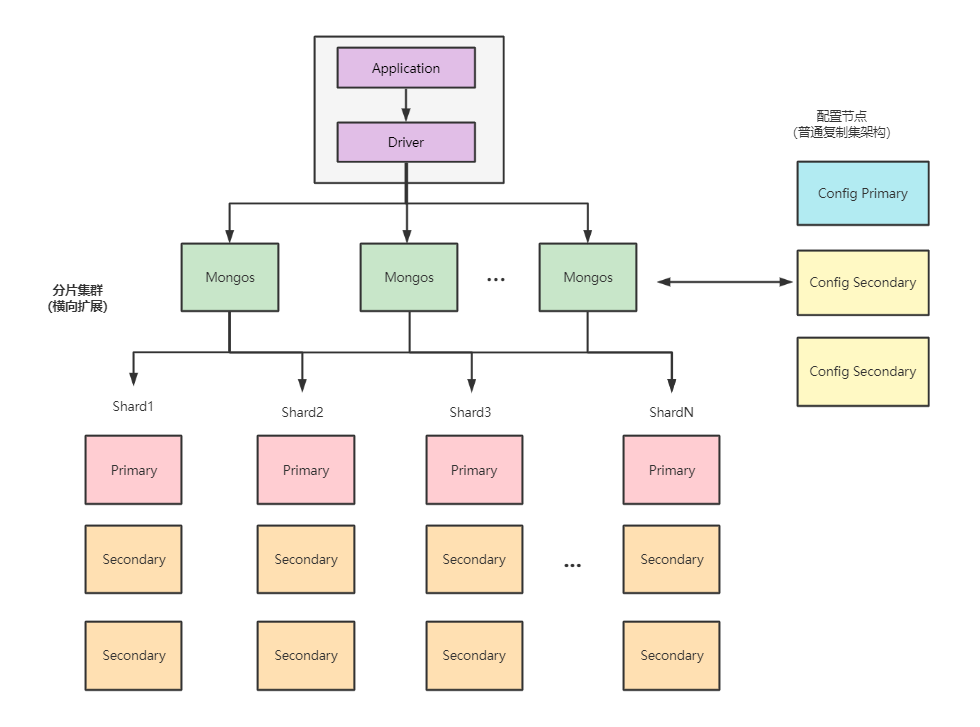
Mongo DB分片架构分为三个部分:
- mongos 路由网关
- 前端网关路由服务端,本身不存储数据,mongos启动后会从configsvr加载元数据
- 接收到mongo client 请求后根据 分片规则(从配置节点获取)进行数据转发
- configsvr 配置节点
- 它是一个mongod 实例,存储了整个集群的元数据,其中包含了分片策略、路由、节点信息等,它是存放着分片和数据的对应关系。比如哪个数据属于哪个分片。
- 为了保证高可用,配置节点也配置了 复制集架构(主从架构高可用)
- sharding server 数据分片服务端
- 用于存储实际的数据块,分片是个逻辑概念,它可以是单节点,也可以是复制集群,但在生产环境中为了保证高可用,我们一般都会搭建复制集 防止单节点故障
2. 分片策略
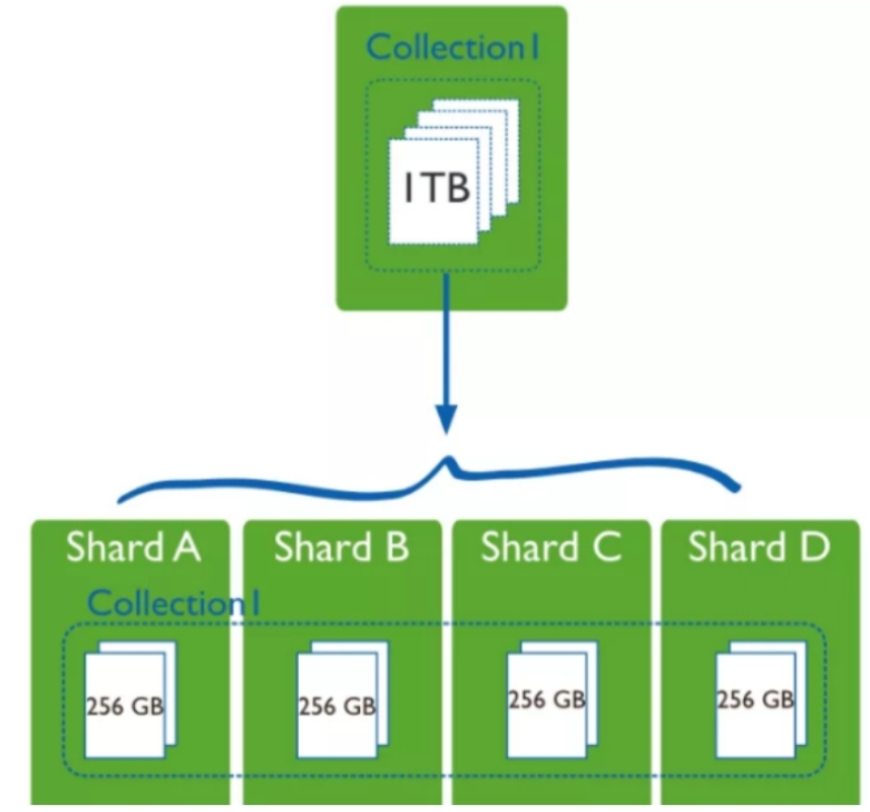
通过分片功能可以将一个大的集合分散到不同的分片上,解决单机存储瓶颈和写热点瓶颈问题。
如:user集合有1TB数据,可以分成4个片,分散在不同的服务器上。
1)chunk
chunk一个数据块,是分片里面的小分片,可以理解成 shard 分片中的最小单元数据块,描述的是范围区间。
如,users集合使用userId作为 分片键,那么会被切分成多个chunk存储在shard中,chunk就是存储users集合的数据块。

集群在操作shard时,会根据分片键(shard key)找到对应的chunk,并对该chunk的分片发起请求。
chunk分布在则在一定程度上影响会 读写效率,具体由以下两点决定:
- chunk切片算法,如 范围分片、哈希分片、TAG分片
- chunk分布情况,可以找到存储chunk的具体shard分片
2)分片算法
Chunk是根据分片策略进行切片的,分片策略包括 分片键、分片算法。
范围分片(range sharding)
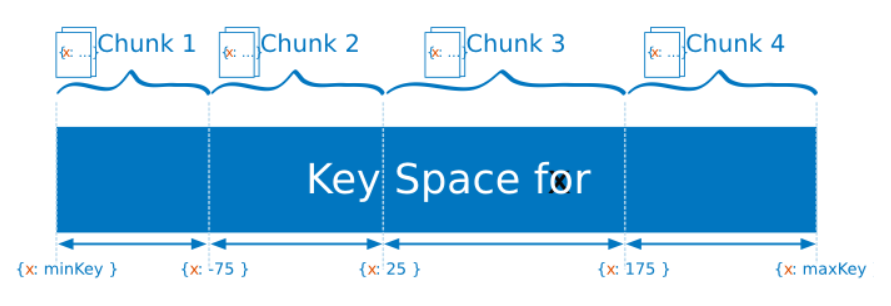
假如我们用x字段来做分片,x的完整取值范围为[minKey, maxKey] ,根据整个取值范围 切分成多个chunk,如:
- Chunk1 minKey ~ -75
- Chunk2 -75 ~ 25
- Chunk3 25 ~ 175
- Chunk4 175 ~ maxKey
范围分片的优缺点:
优点
- 范围分片可以满足 范围查询需求,比如 想查询 x的值在[-30,10]之间的所有文档,mongos会直接定位到chunk2的服务器上
缺点
如果有大量的写入操作的话,如果Shard key(分片key)有自增或递减的趋势,大量的写操作都会集中在同一个chunk上(因为chunk只有达到64MB才会进行分片),写压力都会集中在同一个chunk上,导致性能瓶颈。
可能导致自增的Shard key:
- 时间戳
- ObjectId,自动生成的_id,由时间+计时器
- UUID
- 自增序列
哈希分片(hash sharding)
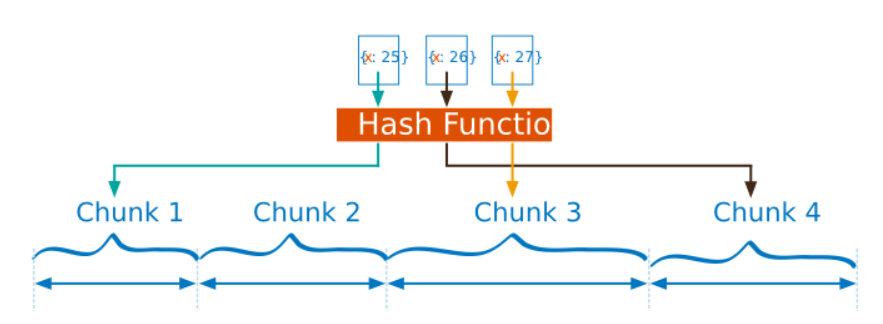
哈希分片会根据分片键计算出哈希值(64位),在根据哈希值按照范围分片的策略进行chunk划分。
哈希分片 适用于日志、互联网等高并发场景,也是目前最主流的做法。
优点:
- 哈希分配可以将文档分散到多个chunk上,避免了数据集中存储,解决了写热点瓶颈。
缺点:
- 执行范围查询时,效率不高。因为范围查询需要对所有的chunk进行遍历,如果集群中有5个分片,则需要对5个分片都进行查询。
创建哈希分片键
1 | mongos> sh.shardCollection("user.employee", {_id: 'hashed'}) |
哈希分片只支持单个分片键,而范围分片可以组合多个字段进行分片。4.4版本之后,支持单字段+多个范围查询字段组合成分片键
分片标签 ShardTag
MongoDB可以支持给Shard 分片打上TAG标签,一个标签可以关联多个分片区间(TagRange)。
插入数据时,均衡器会优先考虑 是否满足 某个分片区间条件(是否满足标签条件),如果满足的话会被chunk 切片到 绑定对应标签的分片上。如果不满足的话,则按照一般情况处理。
1、addShardTag 绑定分片和标签
shard01 绑定log标签,shard02 绑定order标签
1 | sh.addShardTag("shard01","log") |
2、创建分片区间 TagRange
后续如果在 order数据库,orderDetails 集合 插入数据的话,就会满足匹配条件被chunk切片到 order标签对应的shard分片上
1 | sh.addTagRange("order.orderDetails",{orderId:MinKey},{orderId:MaxKey},"order") |
order.orderDetails :匹配的数据库和集合,在 order数据库的orderDetails集合中插入数据的话,就会满足匹配条件
orderId :分片键
分片键(ShardKey)
分片键(ShardKey)的选择
- 分片键的基数越大,越有利于扩展
- 以性别分键,只能分成2份,因为只有 男、女
- 以月份分键,只能分成12分
- 分片键的取值分布应该尽可能均匀
- 分片键应该能适应大部分的业务操作
分片键(ShardKey)的约束
ShardKey 必须是一个索引。非空集合须在 ShardCollection 前创建索引;空集合 ShardCollection 会自动创建索引 。
4.4 版本之前:
ShardKey 大小不能超过 512 Bytes;
仅支持单字段的哈希分片键;
Document 中必须包含 ShardKey;
ShardKey 包含的 Field 不可以修改。
4.4 版本之后:
- ShardKey 大小无限制;
- 支持复合哈希分片键;
- Document 中可以不包含 ShardKey,插入时被当 做 Null 处理;
- 为 ShardKey 添加后缀 refineCollectionShardKey 命令,可以修改 ShardKey 包含的 Field;
而在 4.2 版本之前,ShardKey 对应的值不可以修改;4.2 版本之后,如果 ShardKey 为非_ID 字段, 那么可以修改 ShardKey 对应的值。
3. 数据均衡
理想状态下,我们希望所有分片都能均匀分布数据,均匀效果如下:
- 所有数据均匀分布到不同的chunk上
- 每个分片上的chunk数量尽可能相近
第一点效果由 分片策略来决定,第二点效果由 手动均衡和自动均衡 完成。
1)手动均衡
可以在初始化集合时预分配一定数量的chunk(仅适用于哈希分片),比如给10个分片分配1000个chunk,那么每个分片拥有100个chunk。另一种做法则是,可以通过splitAt、moveChunk命令进行手动切分、迁移。
该方法 基本用不到,也没什么人会在生产中手动去调整分片均衡,费时费力还不讨好。
2)自动均衡
在生产环境中,基本都使用Mongo DB自动均衡模式,均衡器会自动对chunk进行分裂。
开启MongoDB集群的自动均衡功能后,均衡器会在后台对各分片的chunk进行监控,一旦发现了不均衡状态就会自动进行chunk的迁移以达到均衡。
为什么chunk会不均衡?
- 在没有人工干预的情况下,chunk会持续增长并分裂,不断分裂的话会造成 chunk数量不均衡
- 在生产环境中动态增加分片服务器后,就会出现 分片不均衡的情况,这也是 chunk不均衡出现最多的情况
chunk分裂
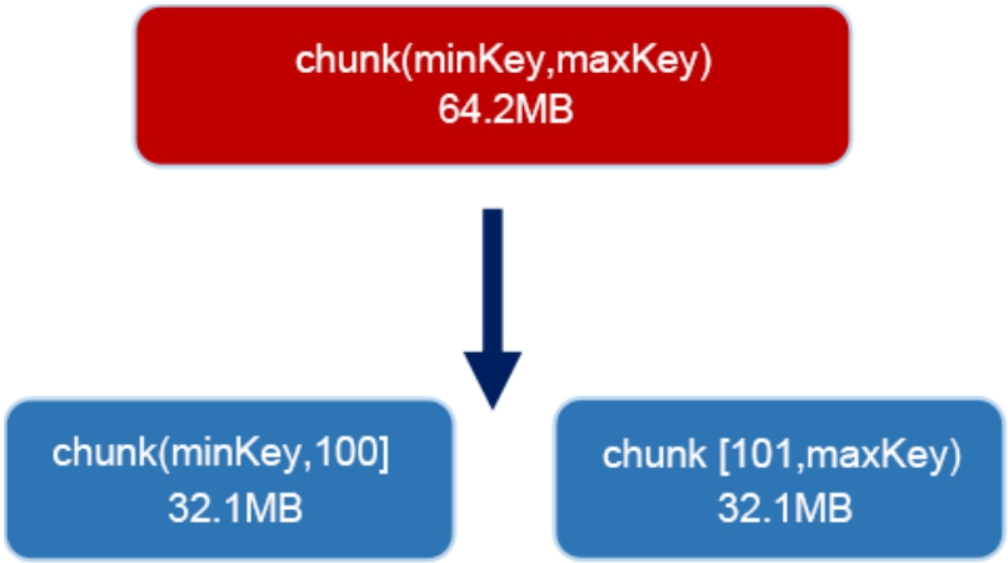
默认情况下,一个chunk 64MB(参数配置:chunksize),如果chunk超过了限制就会自动分裂,分裂成2个相同大小的chunk。
chunk分裂是基于分片键分裂的,如果分片键基数太小,可能导致无法分裂而产生 jumbo chunk(大数据块)的出现。
比如:使用性别 gender作为分片键,最多只能分类成2个chunk(man、woman),如果同一种性别的用户数量达到千万级,这个chunk块就无法继续分裂,最终导致这个chunk块 存储大量数据(超过64MB)。
jumbo chunk不利于数据迁移,chunk分裂是基于分片键的,所以分片键基数越大越好。
自动均衡流程
MongoDB的数据均衡器运行于Primary Config Server(配置服务器的主节点)上,而该节点也同时会控制chunk数据的迁移流程。
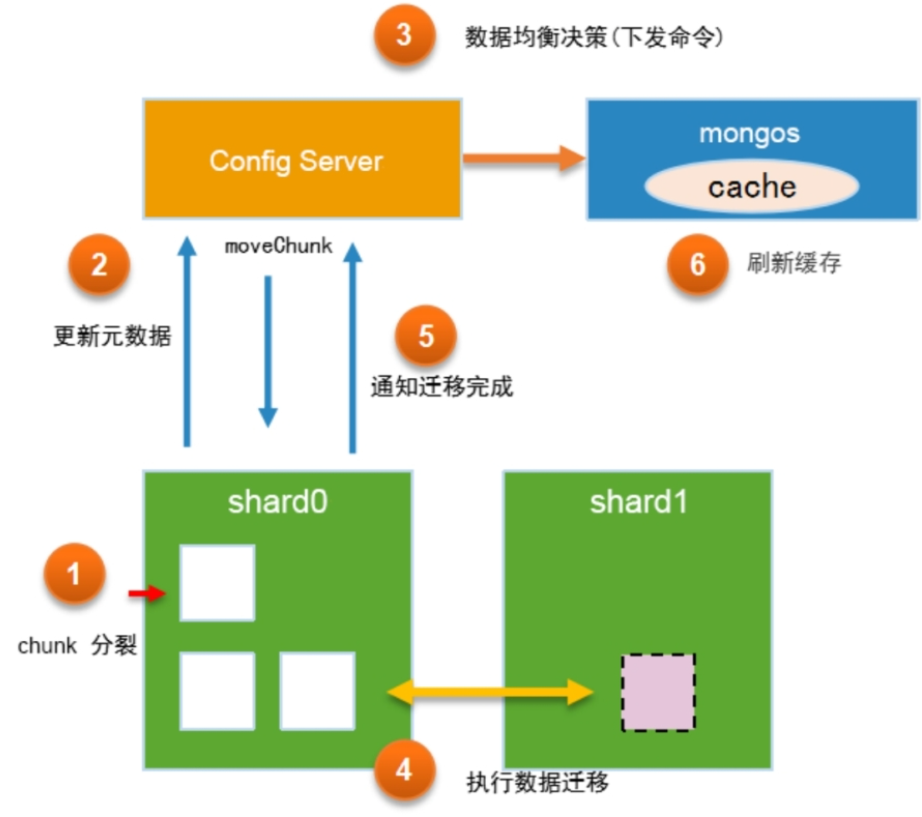
- MongoDB Driver 发送写操作请求,分片节点收到数据后会存入shard0的chunk中
- chunk如果存满64MB后就会开始分裂,分裂后判断是否要迁移到另外一个shard 分片(数据不均衡)
- 如果发现数据不均衡,就会自动进行迁移
- 向配置集群主节点发送迁移命令 moveChunk
- 对另外的shard 分片进行数据迁移,迁移数据期间 2个shard都会有该迁移的数据
- 迁移完成之后,shard 0 会通知配置集主节点,告知迁移完成,mongos 会刷新 元数据缓存(最新的分片数据)
- shard0 会通过异步的形式 删除 迁移成功的数据
迁移阈值
均衡器是如何判定数据分片不均匀的呢? 根据两个分片的chunk个数差异来判断。
| chunk个数 | 迁移阈值 |
|---|---|
| 少于20 | 2 |
| 20~79 | 4 |
| 80及以上 | 8 |
两个分片chunk相差少于20个,迁移2个数量
两个分片chunk相差少于20~79个,迁移4个数量
两个分片chunk相差少于80~N个,迁移8个数量
查询均衡器命令
sh.getBalancerState():查看均衡器是否开启。
sh.isBalancerRunning():查看均衡器是否正在运行。
sh.getBalancerWindow():查看当前均衡的窗口设定。
数据迁移带来的问题
- 数据迁移会对服务器性能造成影响,导致磁盘IO和CPU飙升
- 迁移过程中,由于两个分片会有重复数据存在,使用count去查询时 可能导致重复的计算
- 使用 db.collection.countDocuments({}),该方法会执行聚合操作进行实时扫描
数据迁移会对服务器带来很大性能影响,为了降低对性能的影响,可以采取以下的措施:
- 使用SSD或者更高性能的硬盘阵列
- 在业务的低峰期进行迁移
- 如:可以设置mongos 迁移时间。如 每天凌晨2-5点进行迁移
设置凌晨迁移
1 | use config |
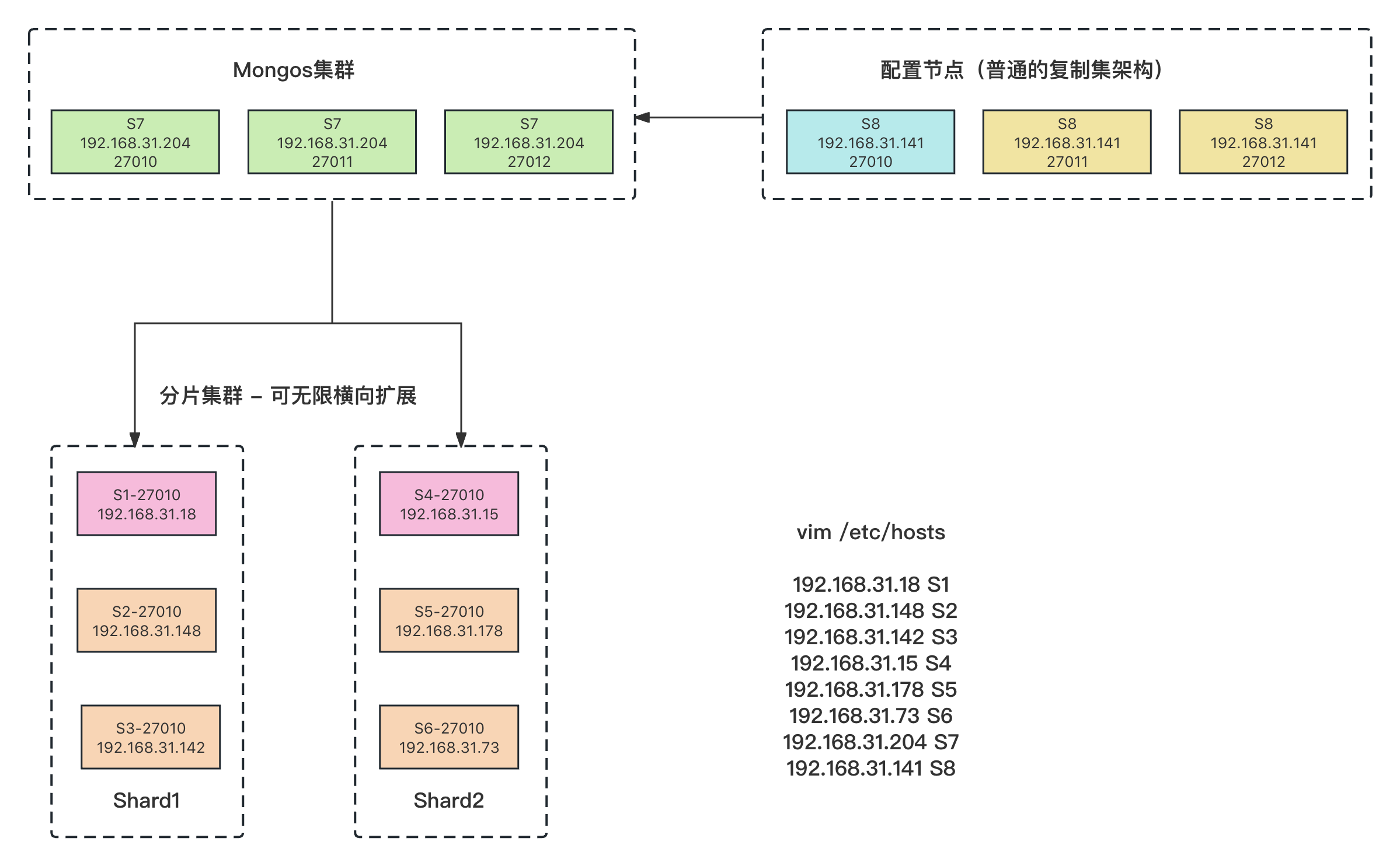
分片集群架构分为三大组件:
- mongos
- 前端网关路由服务端,接收到mongo client 请求后根据 分片规则(从配置节点获取)进行数据转发,看该数据属于哪个分片
- configsvr 配置节点
- 它是一个mongod 实例,存储了整个 Cluster Metadata,其中包括 chunk 信息。它是存放着分片和数据的对应关系。比如哪个数据属于哪个分片。
- 为了保证高可用,配置节点也配置了 复制集架构(主从架构高可用)
- sharding server 分片服务端
- 它是一个mongod 实例,用于存储实际的数据块,可以是单节点,但是在实际生产环境中为了保证分片的高可用,我们一般都会搭建复制集 防止单节点故障(主从架构高可用)
数据分片+设备集群可以完美解决海量数据存储,突破单机节点的存储瓶颈和性能瓶颈,提高并发和可用性,避免因为单机节点宕机导致数据不可用。
为什么需要搭建集群?
假设单机节点只能存储500G数据的话,那我们存储量不够的话,只能考虑搭建集群。假设我们搭建了10台节点,那就能存储5000G(5T)的数据。
集群后数据如何存储?
当集群后就会涉及到数据存储问题,因为不可能每台设备都存一份完整的数据,这样集群的意义只能用于 冗余备份。
所以我们会涉及到 分片存储:
- 当客户端存储数据时会通过一定分片规则,对数据进行哈希分片,分片后的数据存储到对应的节点。
- 后续查询数据时也会根据分片规则进行计算,求出存储数据的节点,找到对应的节点查询数据
如:此时我们存储一条数据 {name:”张三”,age:23},mongo通过分片规则哈希计算,求出存储节点S1,数据会落到对应的节点。
数据分片集群的好处
- 提高读写并发
- 数据分片的话,读写数据会分散,可以突破单机节点的性能瓶颈
- 高可用性
- 单机节点宕机后,就真宕机了。如果是数据分片集群的话,单机节点宕机了,集群的其他节点依然可以对外提供数据服务
1. 分片架构搭建
环境准备
- 需要12台Linux服务器,在上面配置mongoDB环境和环境变量,mongoDB版本必须保证完全一致
- 设备节点分配
- 分片
- 一共有2个分片,每个分片有3个节点,共计6个集群节点
- Mongos服务端集群
- 该架构实际上应该需要3个节点,但是实验中我只配置一个节点,没有配置成集群
- 复制集节点
- 复制集同上,我实际只配置了一个节点
- 分片
1)配置别名解析
vim /etc/hosts 在12个节点上都修改hosts,这样就可以通过别名直接访问对应的IP节点
1 | vim /etc/hosts |
2)创建Shard1 分片集群
在S1、S2、S3 3个节点上初始化mongoDB服务
1 | 下载MongoDB并解压 |
启动mongoDB服务
在Shard1 的3个节点上都启动mongoDB服务。
1 | [root@S1 ~]# mongod --bind_ip 0.0.0.0 --replSet shard1 --dbpath /data/shard1/db --logpath /data/shard1/log/mongod.log --port 27010 --fork --shardsvr --wiredTigerCacheSizeGB 1 |
–bind_ip 监听网卡IP,0.0.0.0 代表所有人都可以访问
–replSet 复制集名称
–shardsvr 声明这是一个集群的分片节点
–wiredTigerCacheSizeGB 设置MongoDB占用的的内存大小
–fork 指定后台启动
–dbpath指定数据文件存储目录
–logpath指定日志文件存储目录
–auth 以认证模式启动(这里我们没有配置这个,可以根据需求自己配置,配置之前需要在admin数据库中创建对应的用户名和权限)
初始化 第一个分片集群节点
1 | 进入mongod shell,注意:这里实验我们没有开启auth 认证模式,可以根据实际情况开启 |
查看复制集状态
1 | rs.status() |
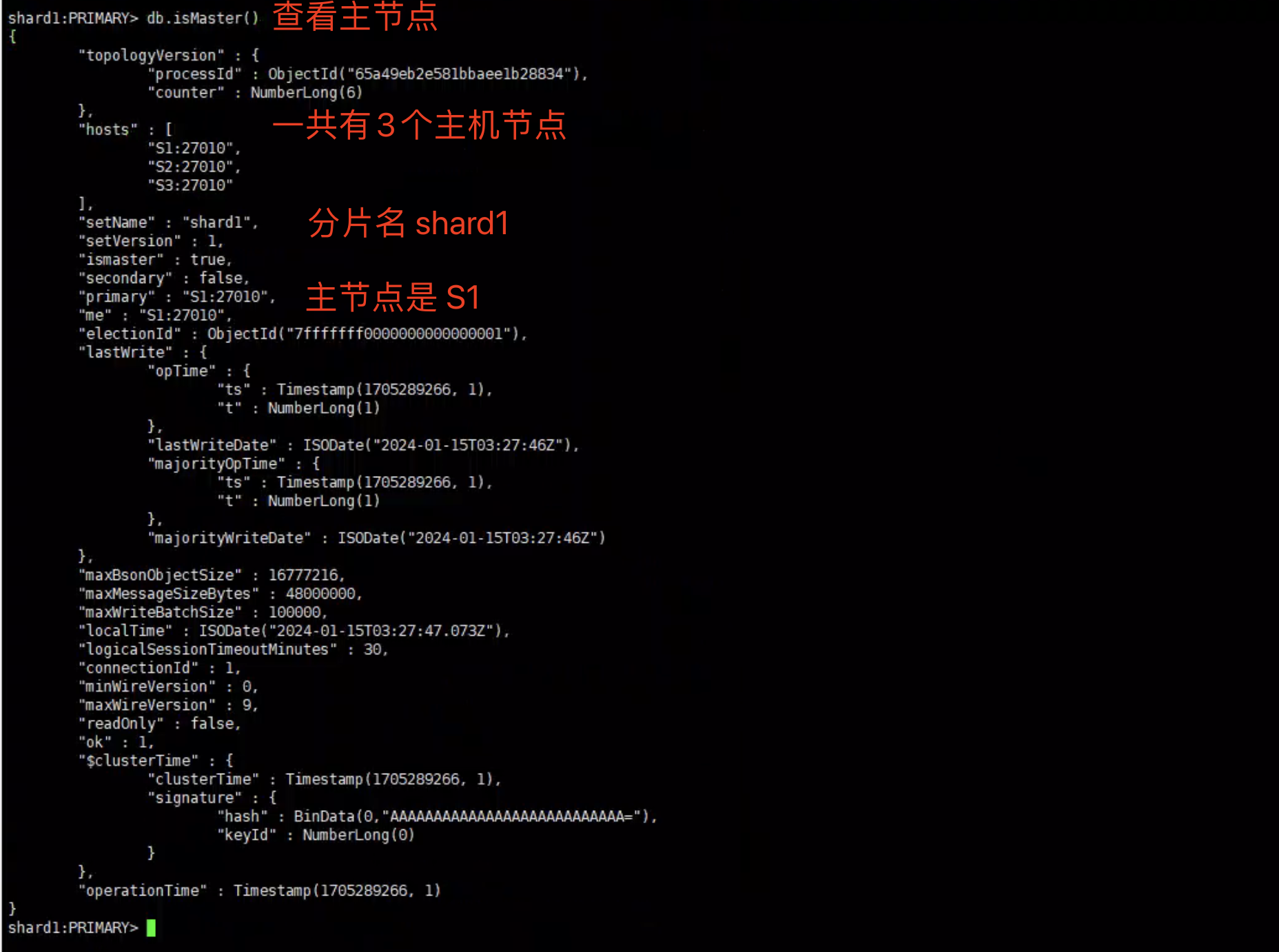
查看Shard1 Master节点信息
1 | shard1:PRIMARY> db.isMaster() |
3)创建Config Server 复制集
1 | 下载MongoDB并解压 |
启动MongoDB Config Server
1 | [root@S1 ~]# mongod --bind_ip 0.0.0.0 --replSet config --dbpath /data/config/db --logpath /data/config/log/mongod.log --port 27010 --fork --configsvr --wiredTigerCacheSizeGB 1 |
–replSet 复制集名称
–configsvr 声明这是Config 配置,存储Cluster Metada(节点信息)以及分片和数据的对应关系。
初始化Config复制集
1 | 初始化复制集 |
members是个数组,可以配置多个复制集节点,但是机器不够 所以我们只配置一个节点
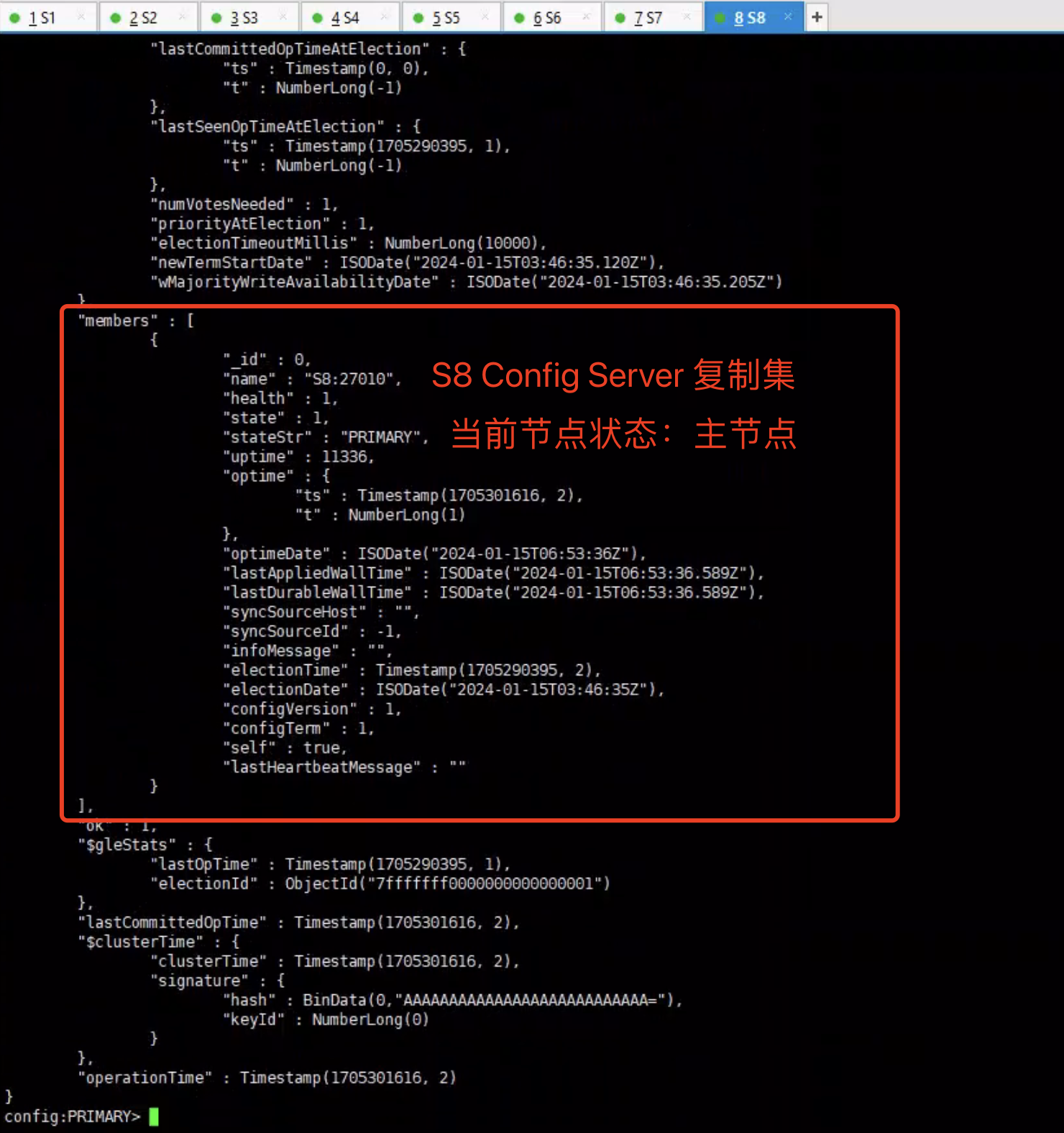
查看复制集状态
1 | rs.status() |
4)创建Mongo服务
1 | 下载MongoDB并解压 |
启动Mongo Server
1 | [root@S7 ~]# mongos --bind_ip 0.0.0.0 --logpath /data/mongos/mongos.log --port 27010 --fork --configdb config/S8:27010 |
–configdb 指定 配置集节点
mongos 加入Shard1
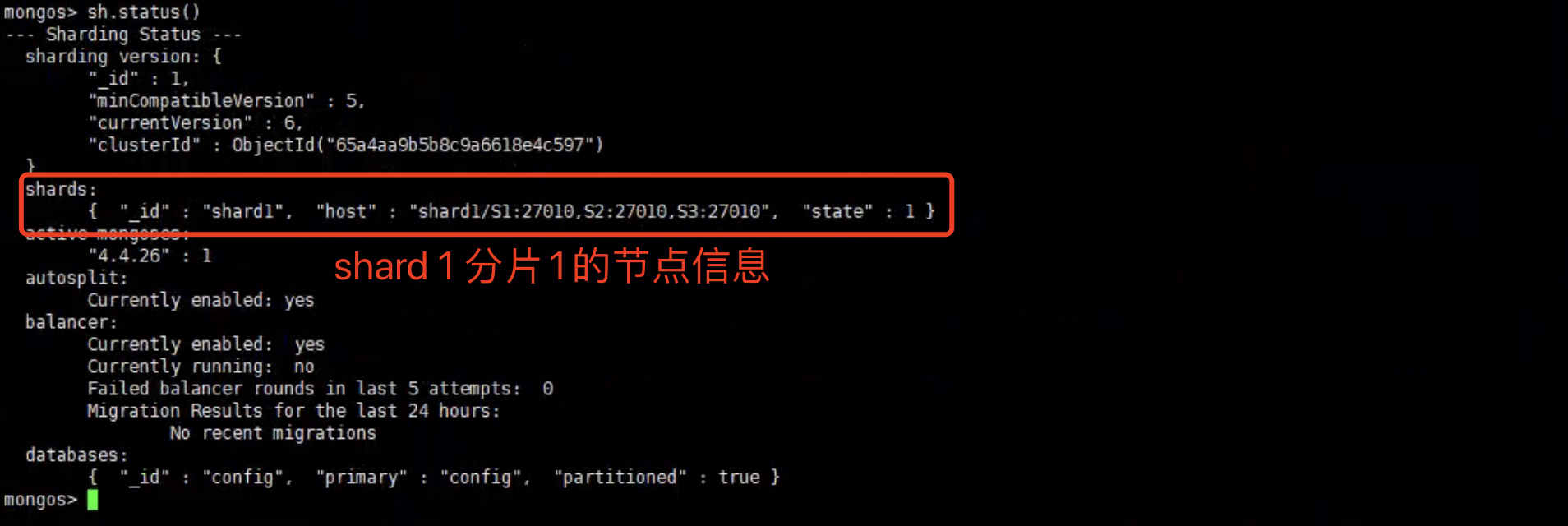
1 | 添加分片 |
查看shard状态
开启数据库分片功能和初始化集合
为了使集合支持分片,需要先开启database的分片功能
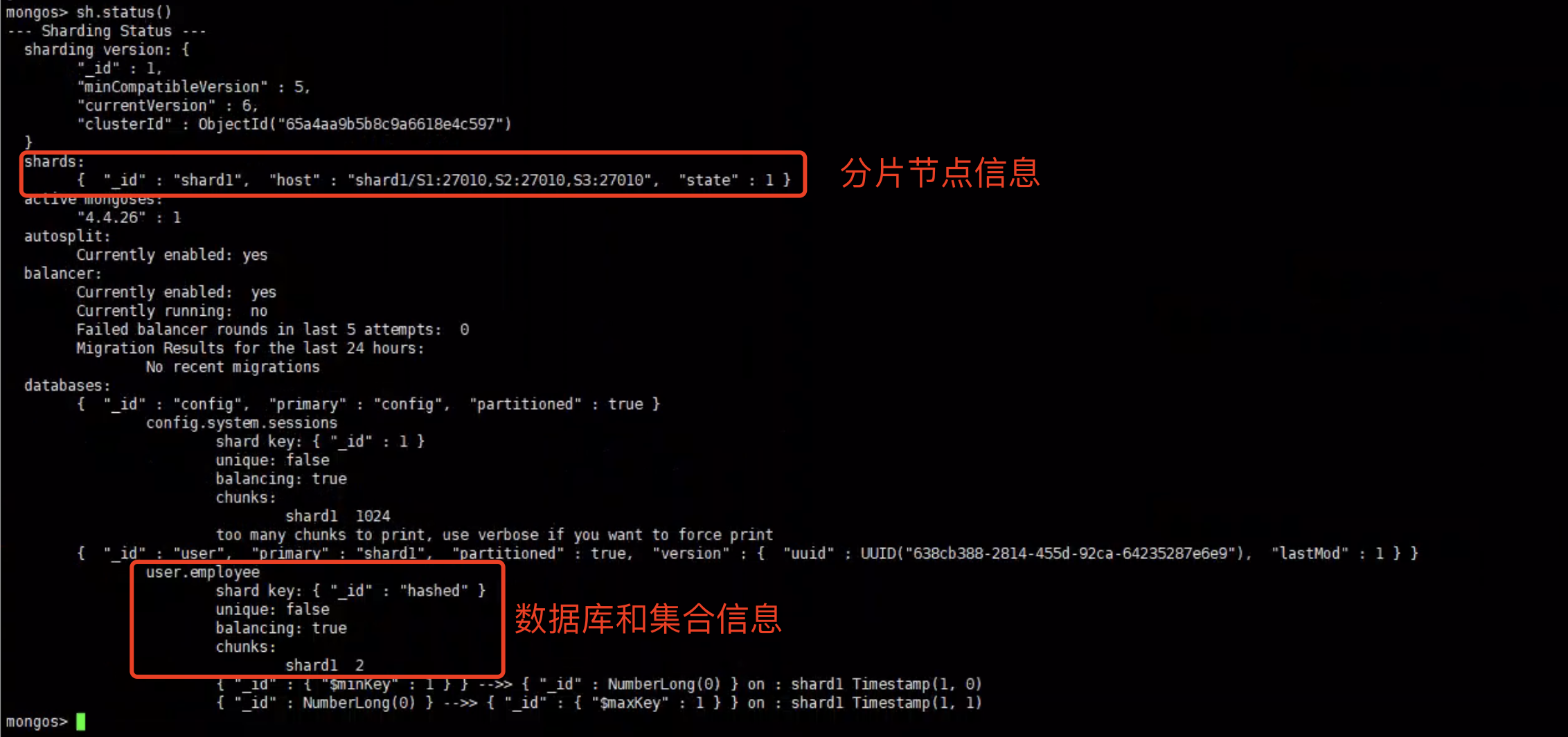
1 | sh.enableSharding("user") |
user 是我们需要开启分片的数据库
执行shardCollection命令,对集合执行分片初始化
1 | sh.shardCollection("user.employee", {_id: 'hashed'}) |
user.employee :需要分片初始化的集合,_id: ‘hashed’ 以哈希的算法进行分配
数据库和集合初始化后,再次查看状态。
5)分片测试
批量1W条插入文档
1 | use user |
查看集合的数据分布情况
mongos> db.employee.getShardDistribution()

只有一个分片的情况下,我们发现 所有的数据都是分布在Shard1 上的
6)创建Shard2 分片集群
创建Shard2
在S4、S5、S6 3个节点上初始化mongoDB服务
1 | 下载MongoDB并解压 |
启动mongoDB服务
在Shard2 的3个节点上都启动mongoDB服务。
1 | [root@S5 ~]# mongod --bind_ip 0.0.0.0 --replSet shard2 --dbpath /data/shard1/db --logpath /data/shard1/log/mongod.log --port 27010 --fork --shardsvr --wiredTigerCacheSizeGB 1 |
–bind_ip 监听网卡IP,0.0.0.0 代表所有人都可以访问
–replSet 复制集名称
–shardsvr 声明这是一个集群的分片节点
–wiredTigerCacheSizeGB 设置MongoDB占用的的内存大小
–fork 指定后台启动
–dbpath指定数据文件存储目录
–logpath指定日志文件存储目录
初始化 第二个分片
1 | 进入mongod shell,注意:这里实验我们没有开启auth 认证模式,可以根据实际情况开启 |
mongos 加入Shard
1 | sh.addShard("shard2/S4:27010,S5:27010,S6:27010") |
查看shard状态
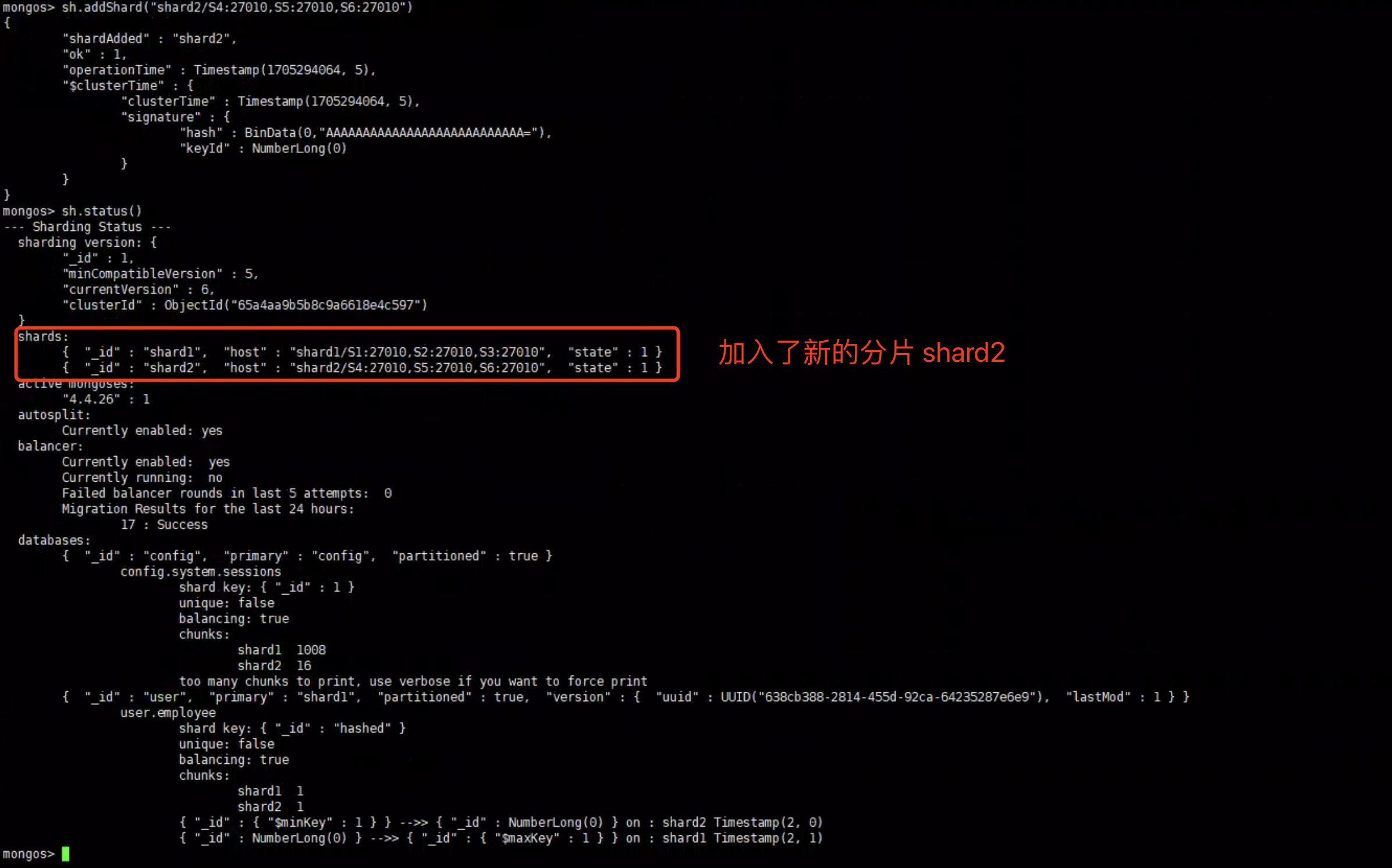
查看集合的数据分布情况
mongos> db.employee.getShardDistribution()

只有一个分片的情况下,我们发现 所有的数据都是分布在Shard1 上的。而现在存在2个分片,数据就会发生一定的迁移,不会将所有数据都放在 一个分片上。
3. mtools快速搭建集群和复制集
mtools是基于python实现的MongoDB工具集,其 包括了日志分析,报表等其他功能。
使用工具可以快速的搭建出复制集和分片集实例,但是仅限于 测试环境,无法用于生产环境,其目的是为了提高测试效率。
1)准备环境
安装编译环境
1 | yum -y install zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gcc make |
安装python3.9
1 | 创建安装目录 |
配置环境变量
1 | [root@S1 bin]# vim /etc/profile |
安装mongoDB环境
mtools是基于mongoDB的工具,所以必须要安装mongoDB并设置环境变量,才可以正常运行mtools。
1 | 下载MongoDB并解压 |
安装需要的依赖
1 | [root@S1 bin]# pip3 install python-dateutil |
安装mtools
1 | [root@S1 bin]# pip3 install mtools |
4. MongoDB高级集群架构
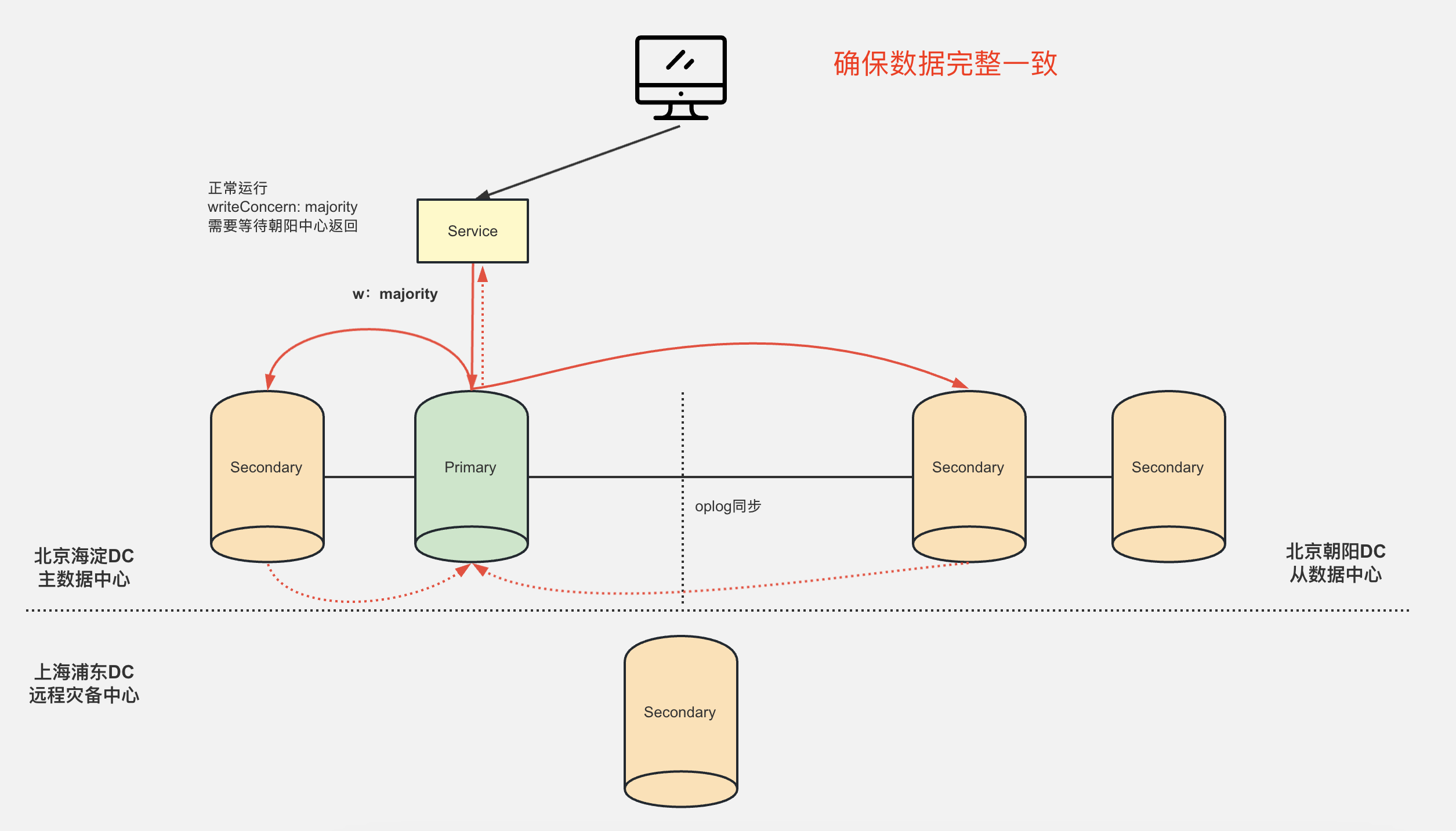
1)两地三中心集群架构
该架构一共有三个机房,北京海淀主数据中心(下述 主中心)、北京朝阳从数据中心(下述 从中心)、上海浦东远程容灾备份中心。
该架构可以避免不可抗拒(如 地震,火灾)的情况,让整个机房宕机导致服务不可用。当 主中心整个机房宕机后,从中心依旧可以对外提供服务。
默认情况下,该架构进行读写分离,写入服务由集群中的Primary节点提供,读取服务由集群中的Secondary节点提供。
注意:同城双中心架构为了确保 数据的一致性,需要拉低延迟专线,确定双机房的数据通信稳定,推荐使用阿里云等云机房云服务器。
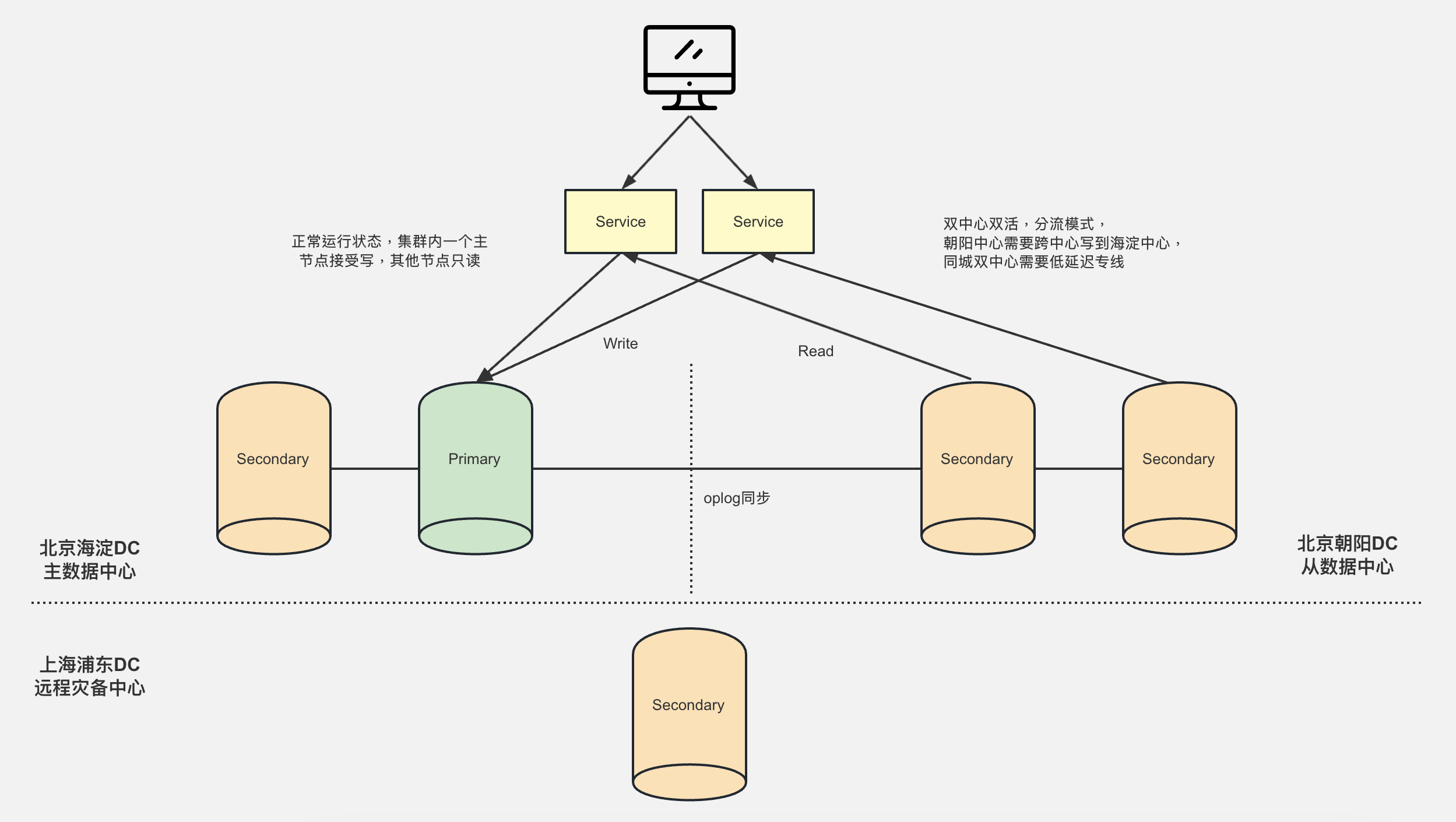
机房介绍:
- 北京海淀主数据中心
- 默认:对外提供 Write 写入数据服务
- 主中心数据Secondary距离Primary最近,理论上Secondary是最新的数据,我们可以将主中心的所有节点优先级调到最高
- 如果主中心Primary宕机了,会优先从主中心的Secondary进行选举
- 北京朝阳从数据中心
- 默认:对外提供 Read 读取数据服务
- 从中心会通过oplog同步主中心数据,确保数据一致
- 上海浦东远程灾备中心
- 不对外提供任何服务,隐藏节点,也不参与选举,主要是用于 灾难备份。
- 从中心会通过oplog同步主中心数据
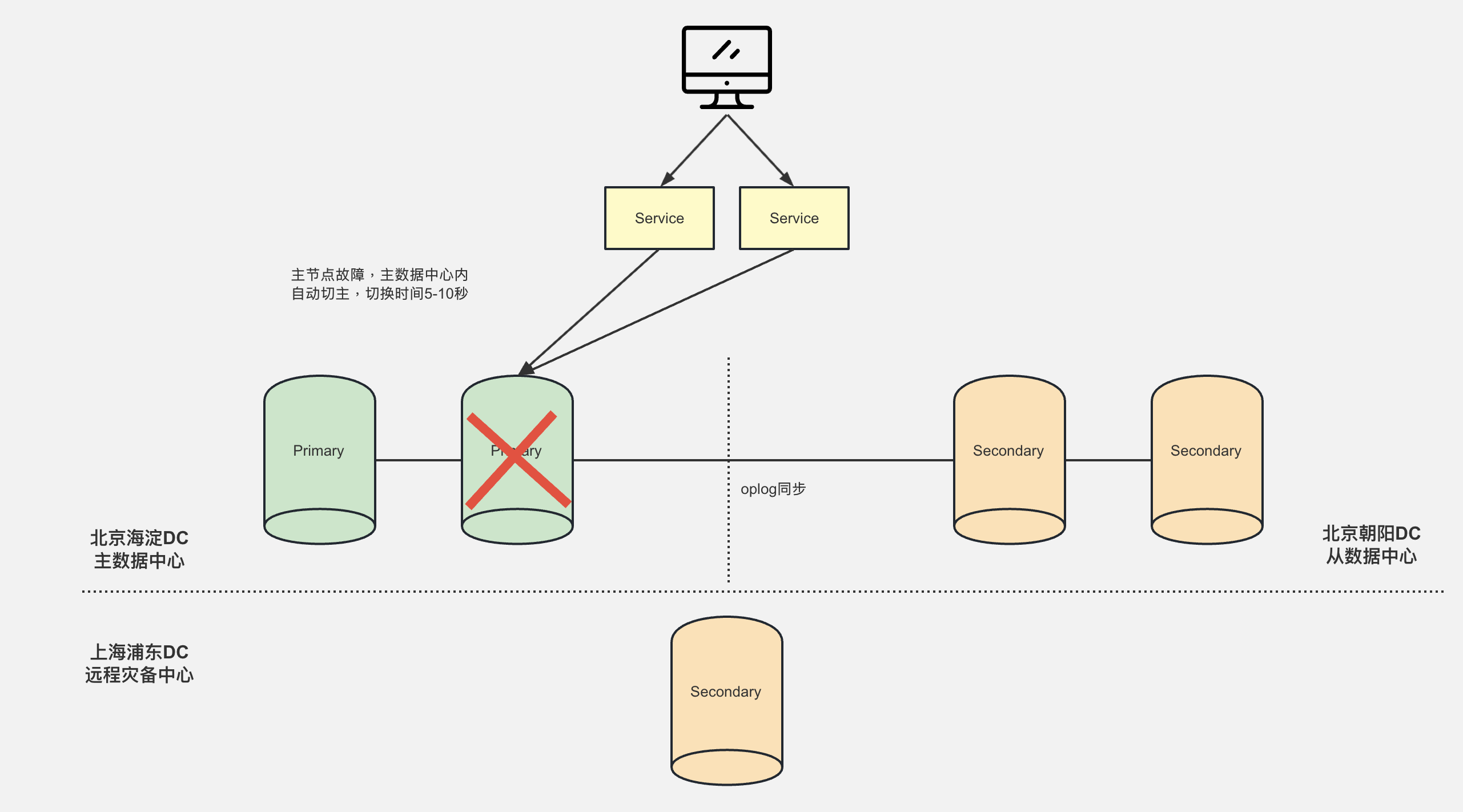
主中心Primary节点宕机
主中心Primary节点宕机后,由于主中心其他Secondary节点优先级较高,会更优先选举成Primary节点。
为什么要优先从主中心的Secondary进行选举
- 因为主中心的Secondary数据是最新的
- 主中心的Secondary和Primary在同一个机房,当主节点故障后 进行选举时最快的(5~10秒)。
主中心机房灾难级宕机
当整个主中心出现了特大灾难事故或网络不可用时,从中心的Secondary会进行选举,选举出新的Primary对外提供服务。
由于从中心的距离较远,进行选举的话 时间会较长,需要5~30秒。
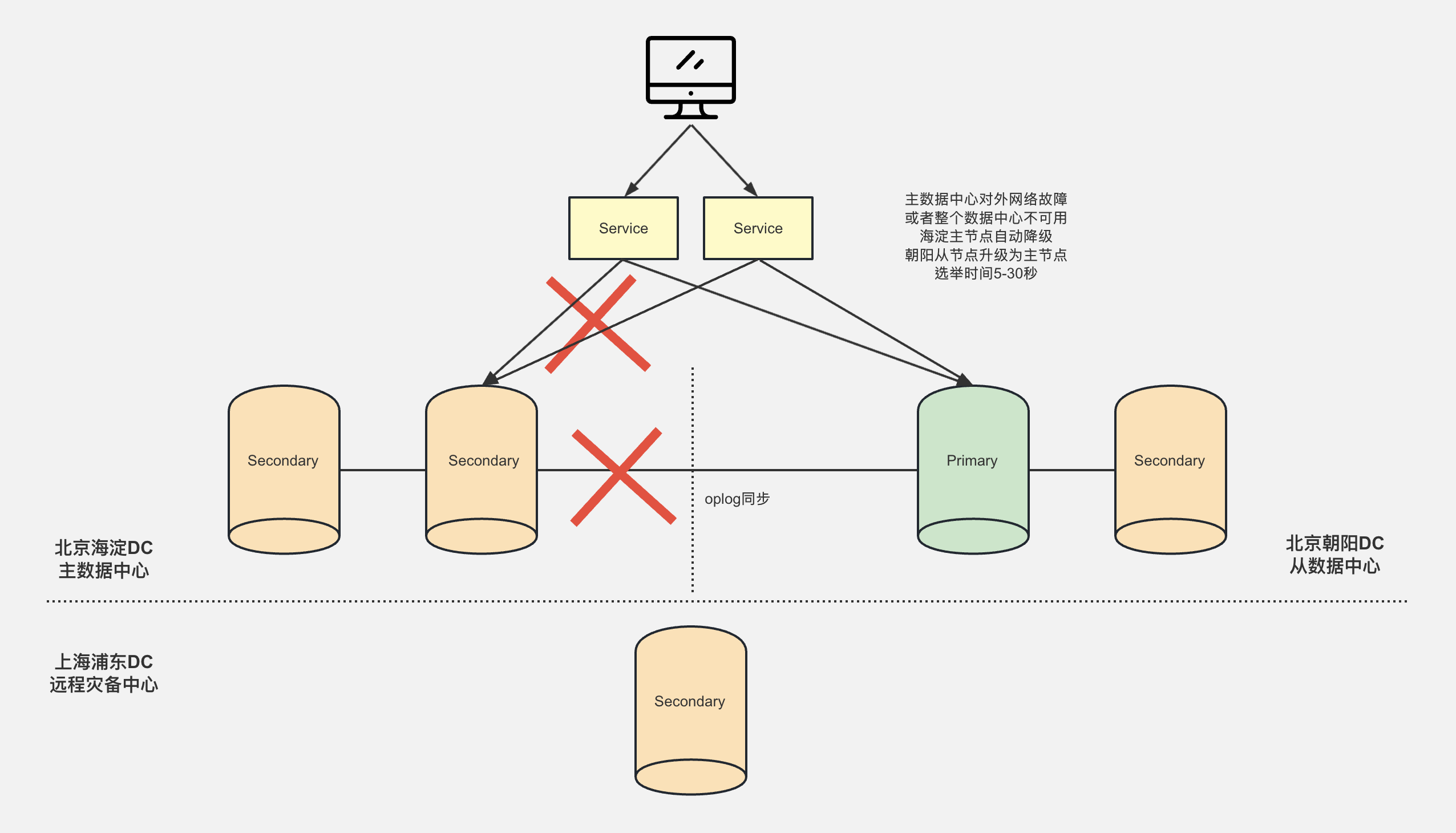
如何确保不同机房数据一致性
写入数据时指定 writeConcern: majority,在写入数据时 确保大部分节点都写入成功后才给客户端返回确认。
2)全球多写集群架构
一般要做全球架构的话,都是单地区部署服务器,然后做全球CDN加速进行加速,很少会 每个地区都部署服务器,然后进行数据同步。
因为远距离的服务器同步数据,最怕的就是数据不一致的情况出现。
如果真的要采用全球多写架构的话,可以考虑以下的方案。
基础复制集架构
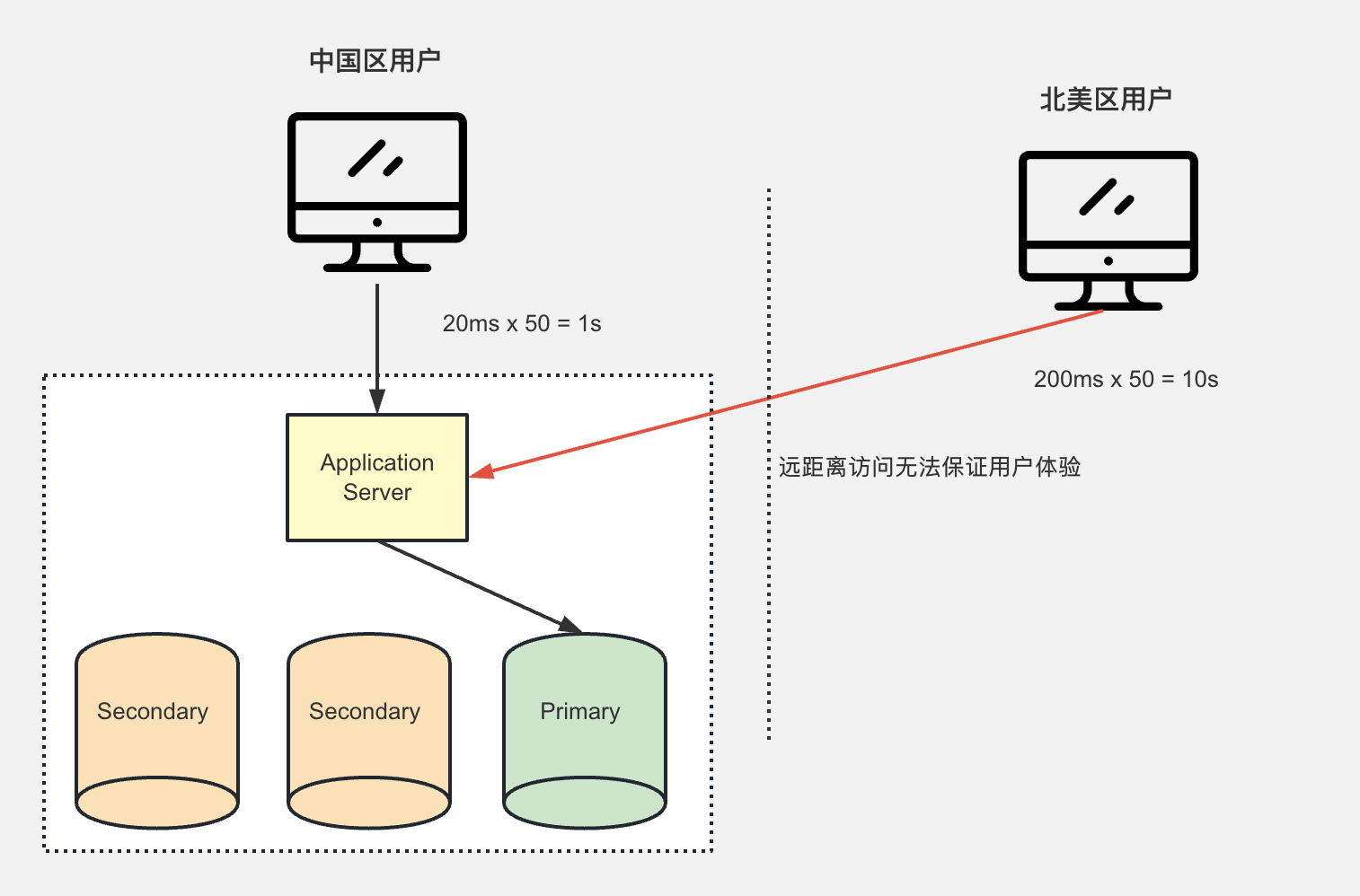
服务器部署在中国,国内客户一切正常,但是北美的客户需要远程访问中国的服务器,访问速度无法保证,延迟非常高,客户体验差。
进阶架构 - 本地读写异地读
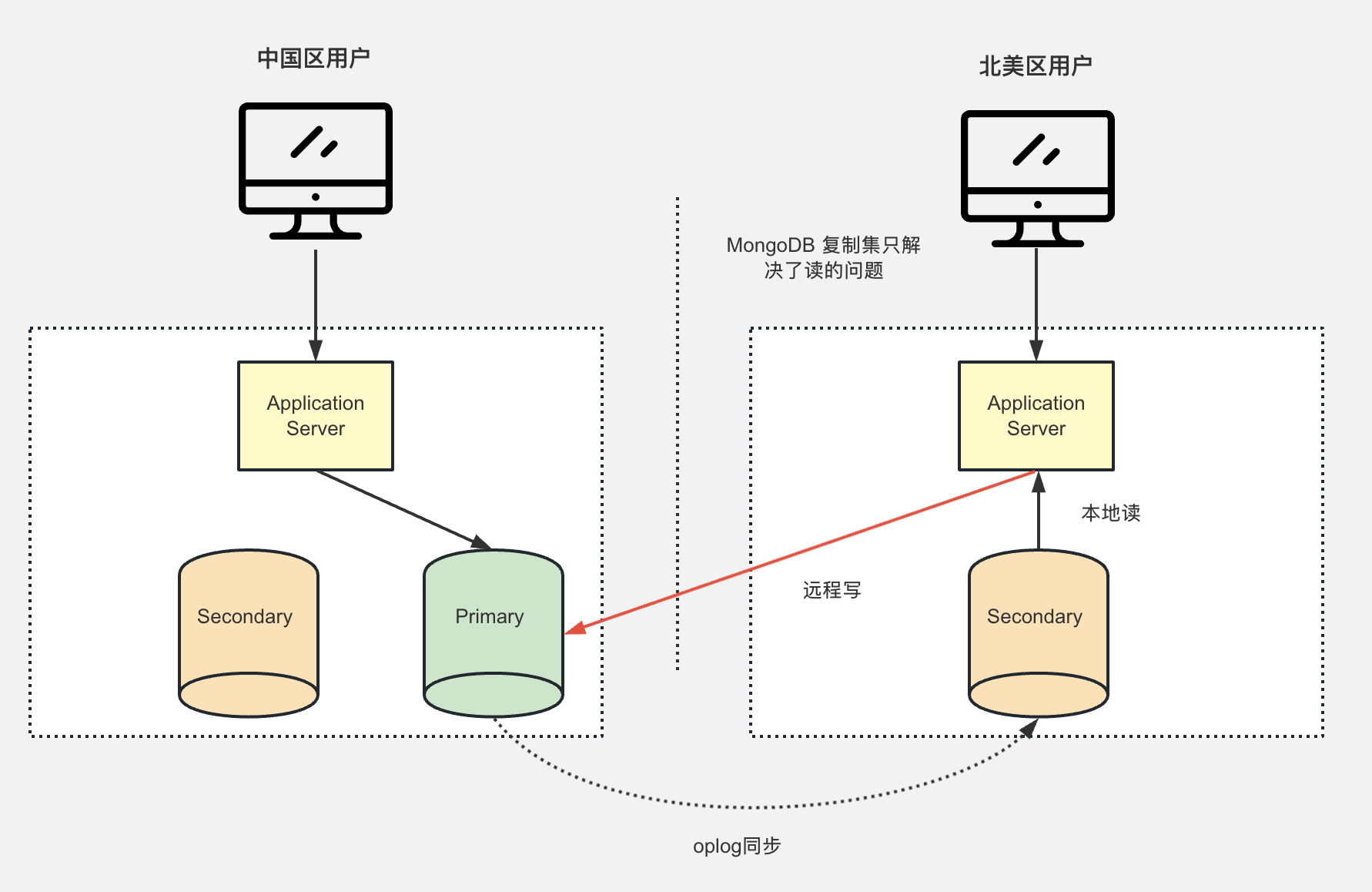
在中国境内部署 复制集群,而北美区部署Secondary节点。写入数据通过远程写入中国区服务器,而北美用户通过本地读取数据。
但是仅仅只是解决了读取的问题,写入依旧是远程写入,写入数据依然存在延迟和速度的问题。
完善架构 - 全球分片集群
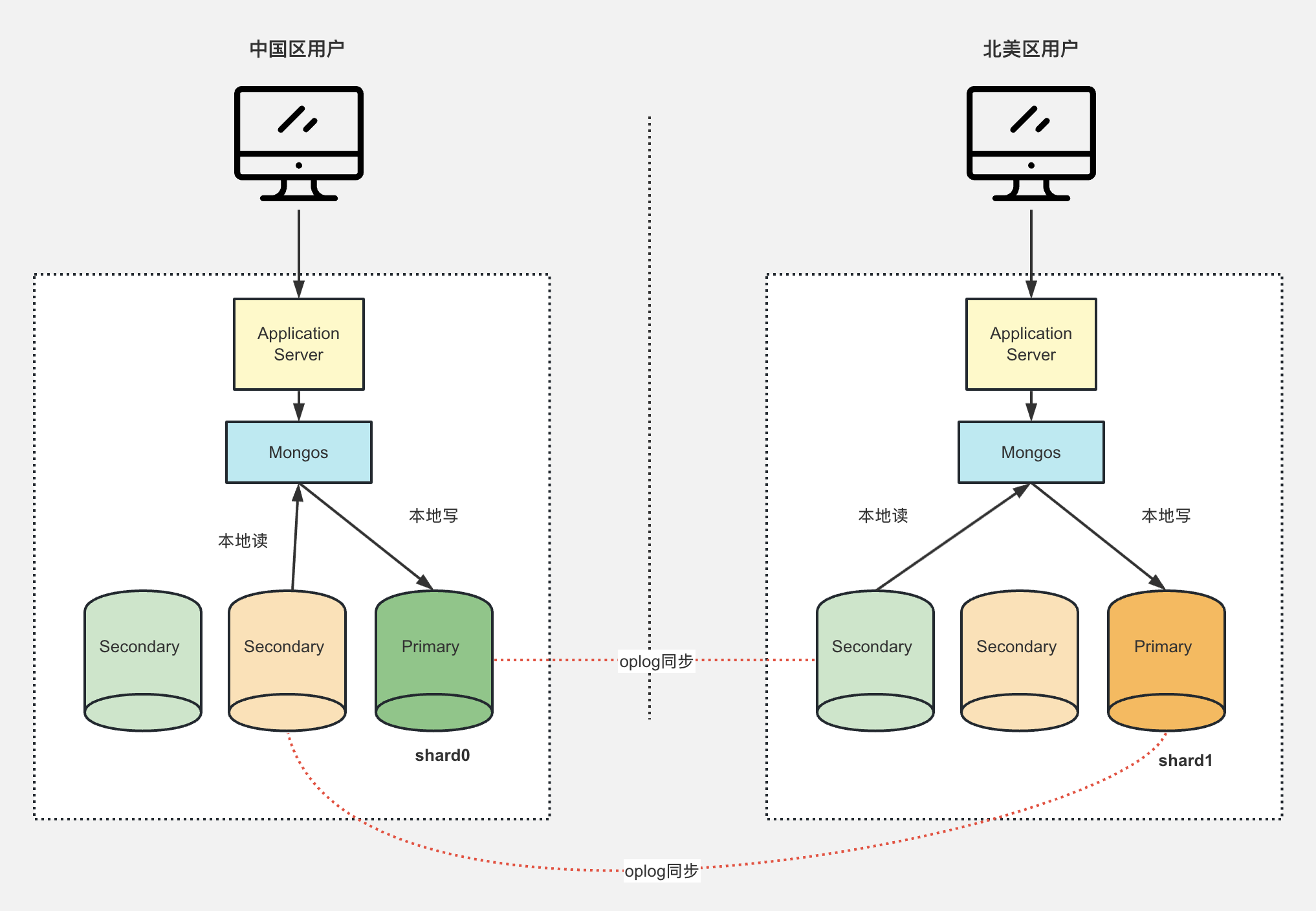
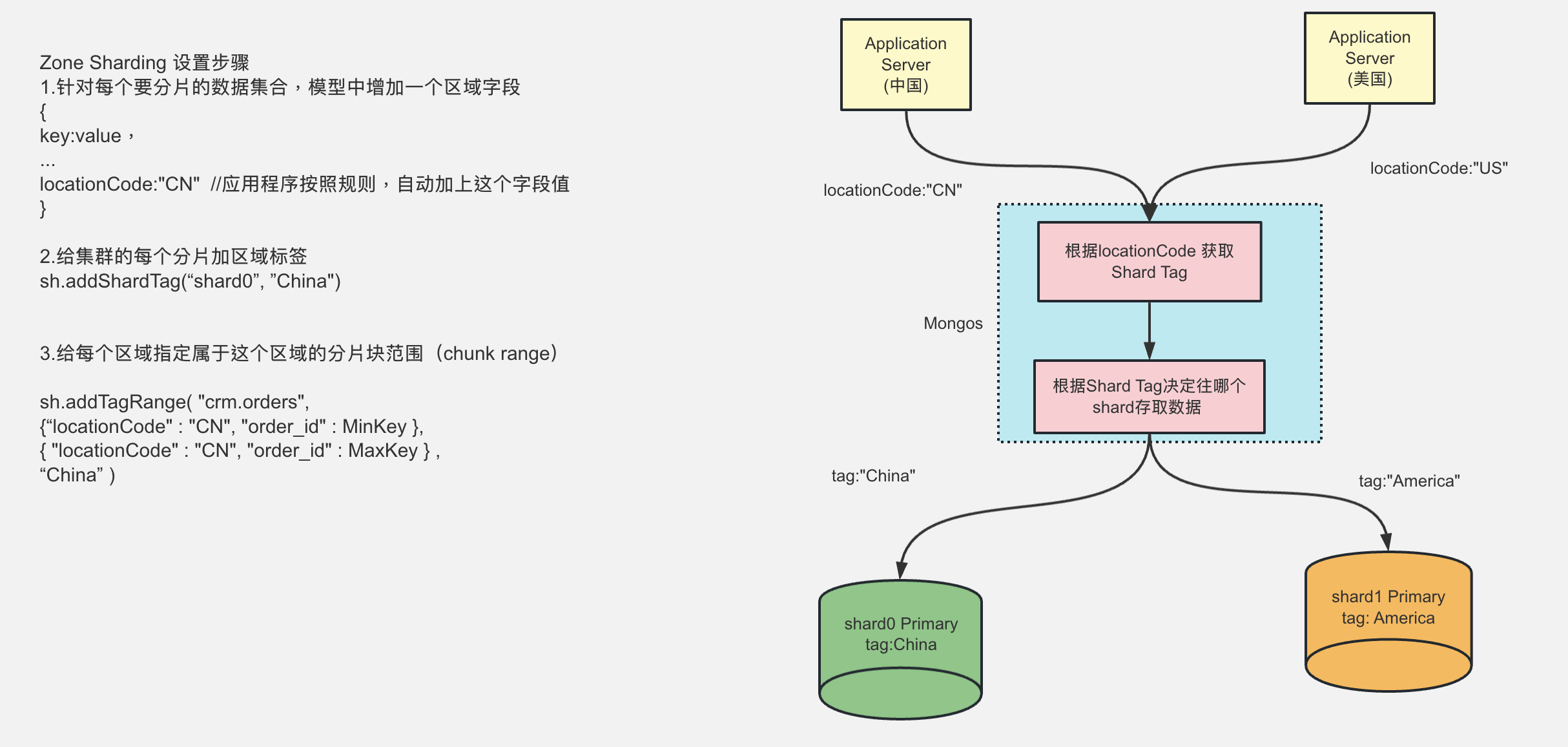
在中国区(shard0)和北美区(shard1)都部署分片集群。
- 通过国家代码创建2个TAG标记,CN、US 分别绑定shard0 和shard1 。并且创建分片区间 和tag进行绑定。
- 写入数据时,判断数据来源(locationCode 客户端传入) 是中国还是美国,然后根据不同的国家获取对应的TAG。
- 根据TAG 查询绑定的分片,就可以根据分片进行存储




