MongoDB基础快速入门
一、MongoDB介绍
1. 什么是MongoDB
MongoDB是一个JSON文档数据库,由C++语言编写,旨在为WEB应用提供可扩展的高性能数据存储解决方案,适用于敏捷式开发、高可用和水平扩展的大数据应用。
MongoDB是非关系型数据库(NoSQL),采用BSON(Binary JSON)来存储数据,一种类似JSON的二进制形式的存储格式,但是访问和存储速度更快,因此可以存储比较复杂的数据类型。
相比 JSON 有以下优势:
- 访问速度更快。BSON 会存储 Value 的类型,相比于明文存储,不需要进行字符串类型到其他类型的转换操作。以整型 12345678 为例,JSON 需要将字符串转成整型,而 BSON 中存储了整型类型标志,并用 4 个字节直接存储了整型值。对于 String 类型,会额外存储 String 长度,这样解析操作也会快很多;
- 存储空间更低。还是以整型 12345678 为例,JSON 采用明文存储的方式需要 8 个字节,但是 BSON 对于 Int32 的值统一采用 4 字节存储,Long 和 Double 采用 8 字节存储。 当然这里说存储空间更低也分具体情况,比如对于小整型,BSON 消耗的空间反而更高;
- 数据类型更丰富。BSON 相比 JSON,增加了 BinData,TimeStamp,ObjectID,Decimal128 等类型。
- 底层编解码更快。BSON会转成二进制格式进行存储,所以在底层框架传输的时候效率更高,因为在存储的时候就是二进制,在底层框架传输的时候不需要再解析编码成二进制。
MongoDB支持的查询语言非常强大,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。原则上 Oracle 和 MySQL 能做的事情,MongoDB 都能做(包括 ACID 事务)。
MongoDB vs 关系型数据库
MongoDB概念与关系型数据库(RDBMS)非常类似:
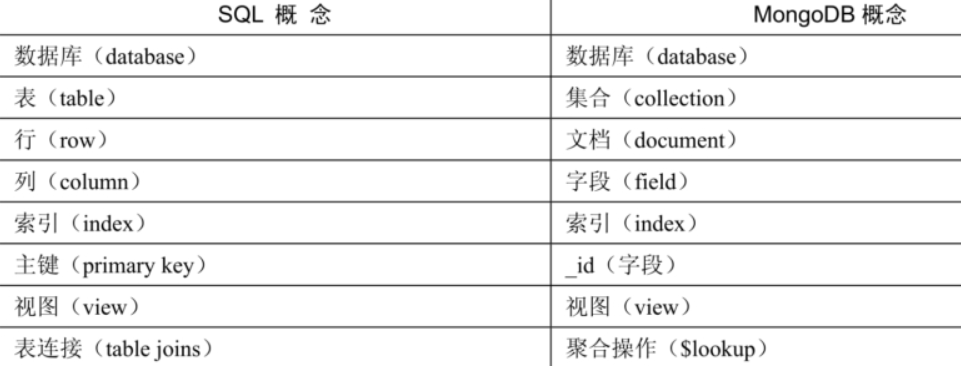
- 数据库(database):最外层的概念,可以理解为逻辑上的名称空间,一个数据库包含多个不同名称的集合。
- 集合(collection):相当于SQL中的表,一个集合可以存放多个不同的文档。
- 文档(document):一个文档相当于数据表中的一行,由多个不同的字段组成。
- 字段(field):文档中的一个属性,等同于列(column)。
- 索引(index):独立的检索式数据结构,与SQL概念一致。
- _id:每个文档中都拥有一个唯一的_id字段,相当于SQL中的主键(primary key)。
- 视图(view):可以看作一种虚拟的(非真实存在的)集合,与SQL中的视图类似。从MongoDB 3.4版本开始提供了视图功能,其通过聚合管道技术实现。
- 聚合操作($lookup):MongoDB用于实现“类似”表连接(tablejoin)的聚合操作符。
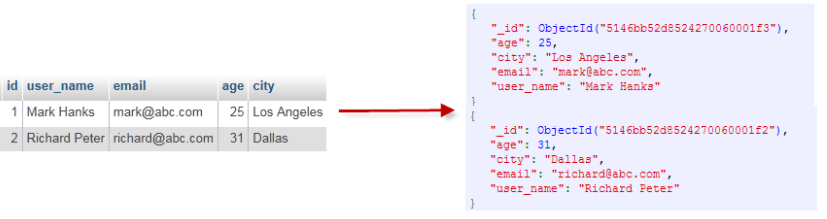
MongoDB与MySQL的区别
- 半结构化
- 字段:在一个集合中,文档的字段不需要去提前定义声明,可以随时变动。
- 嵌套:文档内的字段结构可以随意变动非常灵活,可以多级嵌套、数组。
- 弱关系化
- MongoDB没有外键约束,也没有join 连表能力。但是我们可以用聚合管道来实现join连表。
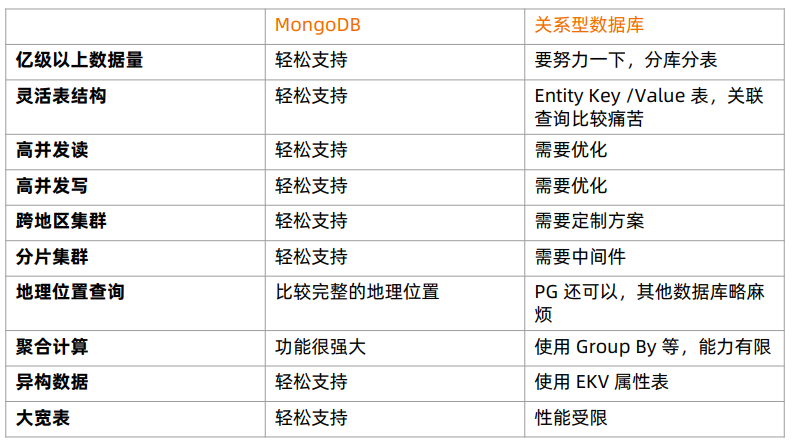
不论从任何角度来分析,MongoDB都是完全碾压关系型数据库,现在越来越受互联网公司青睐,只是在国内被严重低估了。
2. MongoDB技术优势
MongoDB基于灵活的JSON文档模型,非常适合敏捷式的快速开发。与此同时,其与生俱来的高可用、高水平扩展能力使得它在处理海量、高并发的数据应用时颇具优势。
- JSON 结构和对象模型接近,开发代码量低,更容易响应新的业务需求
- 复制集提供99.999%高可用
- 分片架构支持海量数据和无缝扩容
1)简单的对象模型
从错综复杂的关系模型到一目了然的对象模型
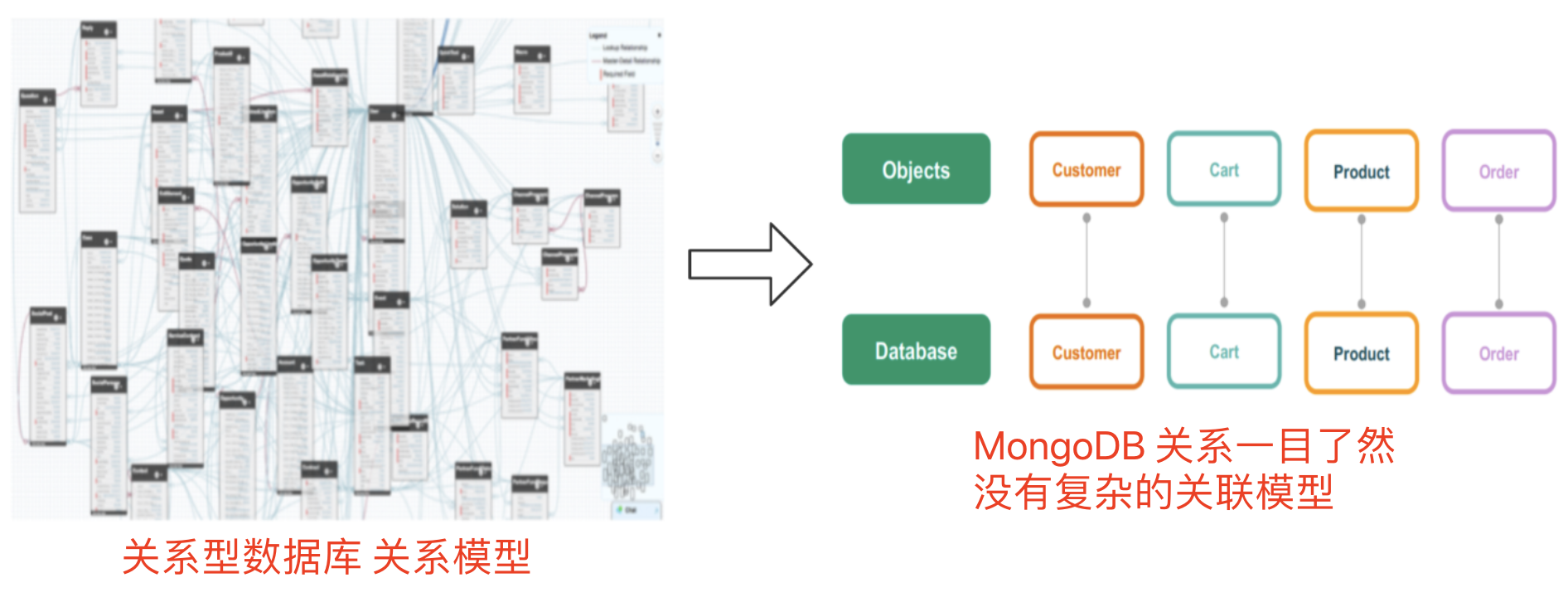
关系型数据库需要创建各样的表和关系模型,而MongoDB 客户集合就对应客户集合,购物车结合就对应购物车集合,不需要创建关系模型,之间也不会有直接外键交集,关系模型非常简单。
2)敏捷快速开发
最简单快速的开发方式

在MySQL中,如果需要存储的字段有多个的话,如 电话、地址等,就需要建立多张表来存储,如 Phone表,Address表。
而在MongoDb中,集合里面的结构和数据可以随意变动,想要存储多个的话,直接用数组来实现。
3)灵活变化
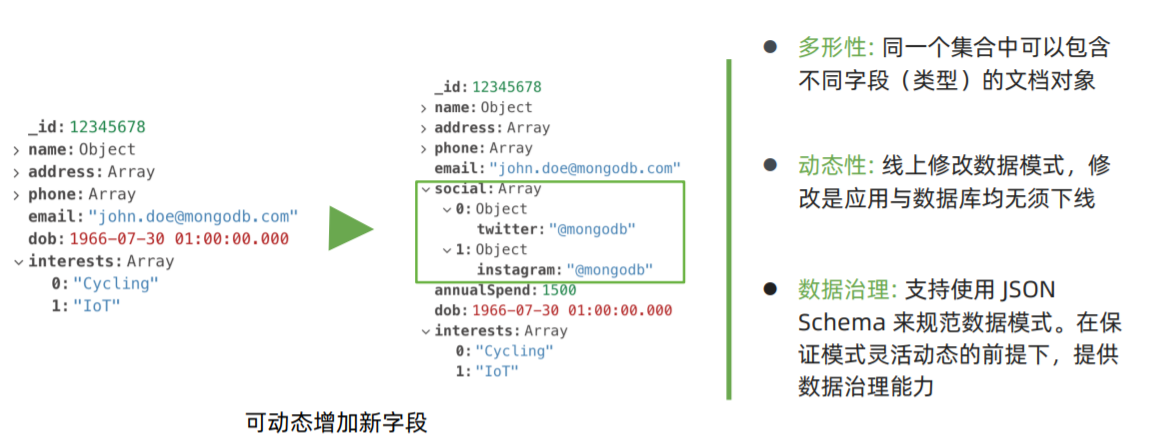
在MySQL的情况下,某个字段需要进行变动的话,就需要修改数据结构和字段类型(如 新增关联表进行存储)。
而在MongoDB中,如果需要增加字段可以随时动态增加、修改,不需要去 定义数据结构。
4)高可用性
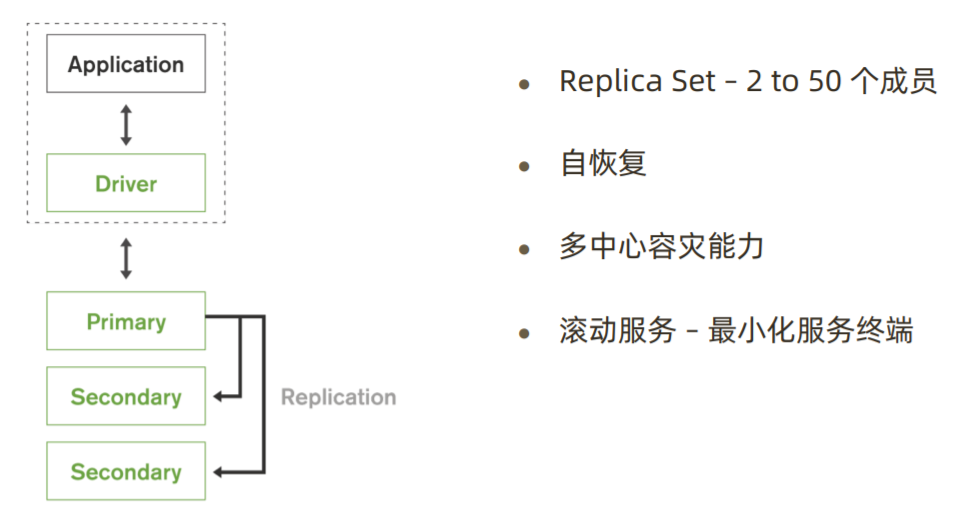
MongoDB基于复制集功能,具备自恢复,多中心容灾能力。
滚动服务:
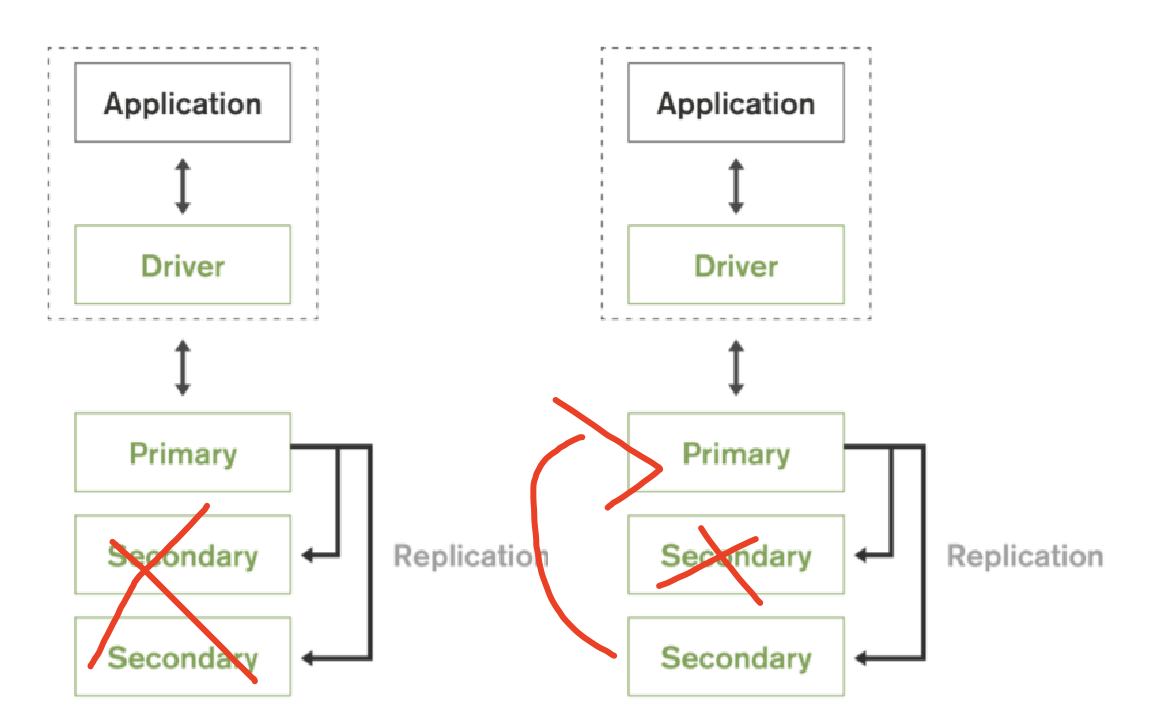
mongoDB版本迭代上线,不需要暂停服务,可以直接上新的节点,然后让主节点宕机,把新节点变成主节点。
5)横向扩展力
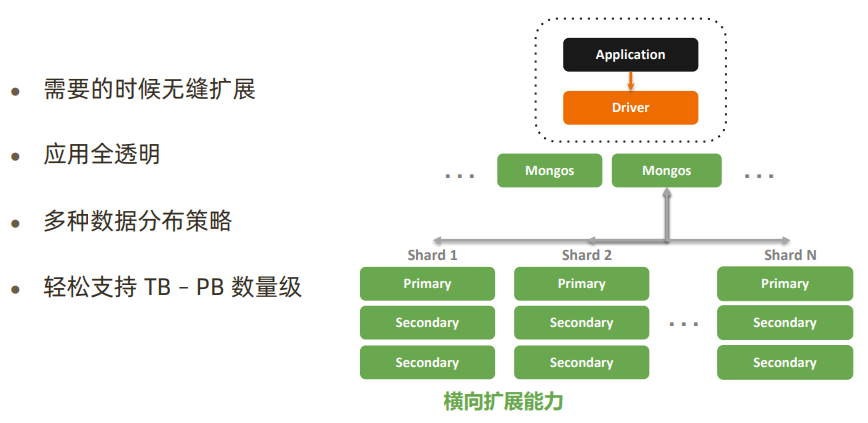
当读写吞吐量达到一定瓶颈时,或者集群存储空间不够时,可以横向扩展分片节点(增加服务器设备)来提高吞吐量。
3. MongoDB应用场景
从目前阿里云 MongoDB 云数据库上的用户看,MongoDB 的应用已经渗透到各个领域:
- 游戏场景,使用 MongoDB 存储游戏用户信息,用户的装备、积分等直接以内嵌文档的形式存储,方便查询、更新;
- 物流场景,使用 MongoDB 存储订单信息,订单状态在运送过程中会不断更新,以MongoDB 内嵌数组的形式来存储,一次查询就能将订单所有的变更读取出来;
- 社交场景,使用 MongoDB 存储存储用户信息,以及用户发表的朋友圈信息,通过地理位置索引实现附近的人、地点等功能;
- 物联网场景,使用 MongoDB 存储所有接入的智能设备信息,以及设备汇报的日志信息,并对这些信息进行多维度的分析;
- 视频直播,使用 MongoDB 存储用户信息、礼物信息等;
- 大数据应用,使用云数据库MongoDB作为大数据的云存储系统,随时进行数据提取分析,掌握行业动态。|
国内外知名互联网公司都在使用MongoDB: 
如何考虑是否选择MongoDB?
没有某个业务场景必须要使用MongoDB才能解决,但使用MongoDB通常能让你以更低的成本解决问题。如果你不清楚当前业务是否适合使用MongoDB,可以通过做几道选择题来辅助决策(官方推荐)。
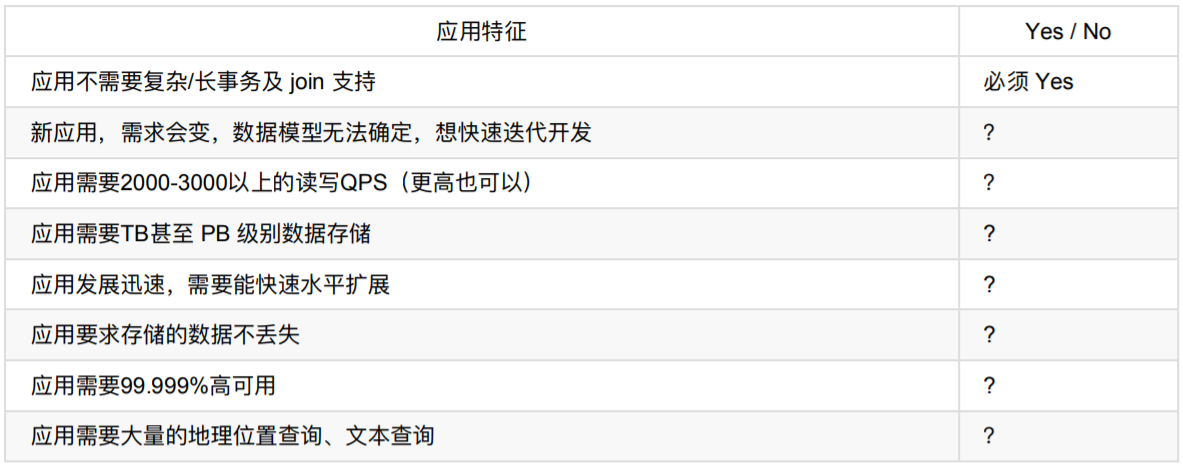
只要有一项需求满足就可以考虑使用MongoDB,匹配越多,选择MongoDB越合适。
4. MongoDB快速使用
1)安装mongoDB
- Linux安装mongoDB方式有两种:1、官网安装 2、docker ,任君采撷。
Linux 官网安装
下载地址:https://www.mongodb.com/try/download/community
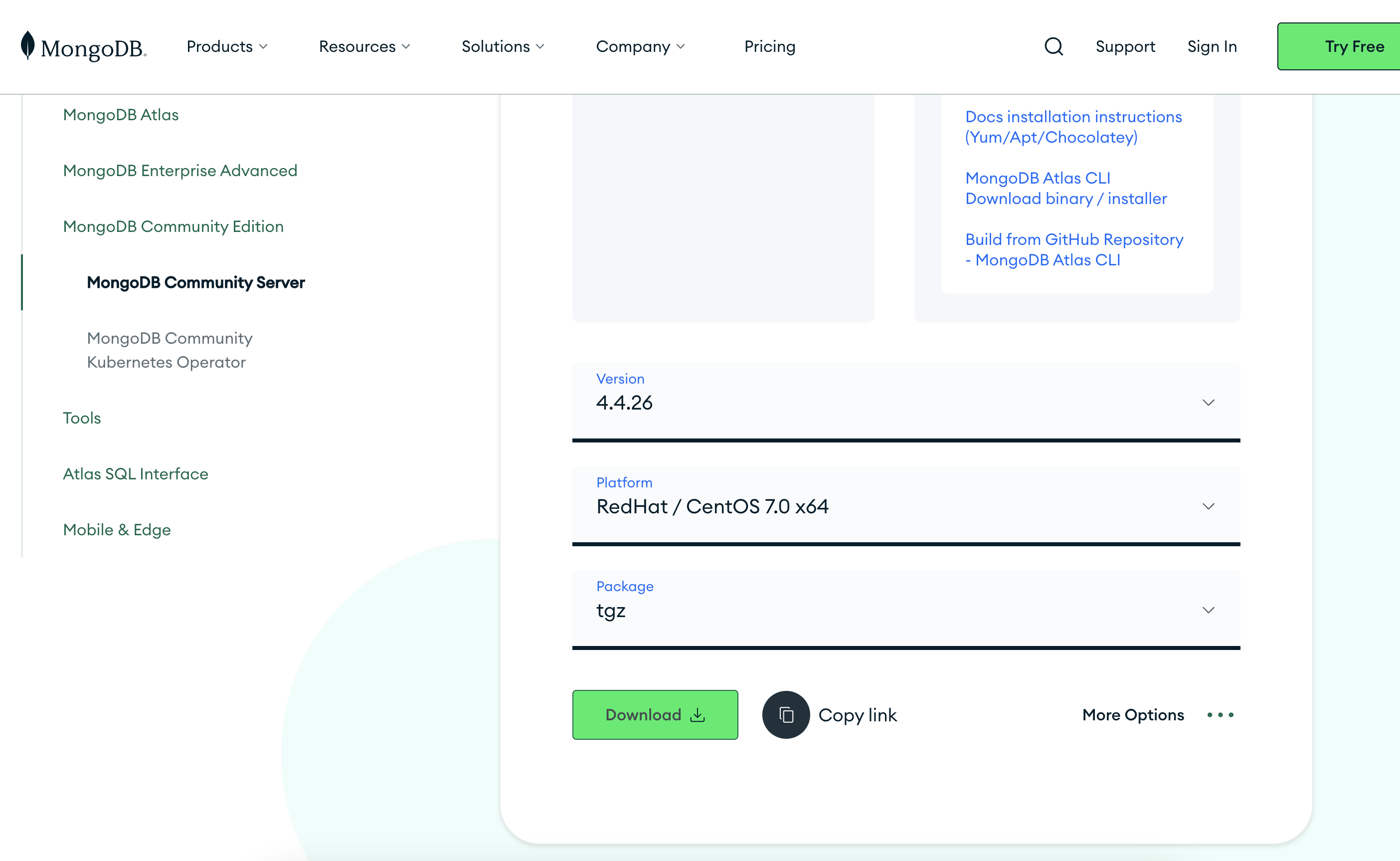
生产版本推荐用4.x稳定版,选择对应的系统,安装方式设置成 tgz压缩包,并复制 下载地址(Copy link)
1 | 下载mongoDB并解压 |
Docker安装mongoDB
1 | 拉取mongoDB镜像 |
1 | 进入容器 |
2)启动和关闭mongoDB服务
help 查看命令手册
1 | [root@cvm52851 ~]# cd mongodb-linux-x86_64-rhel70-4.4.26/bin/ |
常用命令:
–fork 后台启动
–logpath arg 当前存储日志路径
–bind_ip 绑定IP,默认绑定localhost,如果需要远程访问的话就需要绑定到 服务器公网IP,0.0.0.0表示谁都可以访问,生产环境慎用。
–dbpath arg mongoDB 数据库默认存储目录 /data/db
–journal 是否写入日志
–wiredTigerCacheSizeGB arg mongoDB默认启动时会占用一半的内存。(未考究。)默认情况下,允许最大占用一半内存。
添加环境变量
修改 /etc/profile 添加环境变量,方便执行MongoDB命令
1 | export MONGODB_HOME=/root/mongodb-linux-x86_64-rhel70-4.4.26 |
命令行快速启动
1 | 创建mongoDB 数据文件存储路径和日志路径 |
–dbpath:指定数据文件存储目录
–logpath:指定日志文件存储目录
–logappend:以末尾追加的形式 记录日志
–port:指定启动端口,默认端口27017
–bind_ip:默认只监听localhost网卡
–fork:后台启动
–auth:开启认证模式
配置文件启动服务
- 通过配置文件启动服务的话,就不需要每次都在命令行里面设置参数
1 | # 编辑配置文件 |
格式必须是yaml格式,空格不能多也不能少,否则无法启动。
1 | 以配置文件启动服务 |
关闭服务
关闭服务的话不可以直接kill服务,否则下次启动时需要恢复启动。用下面两种方式的话,则不存在该隐患。
方式一:
1 | [root@cvm52851 mongodb-linux-x86_64-rhel70-4.4.26]# bin/mongod --port=27017 --dbpath=/mongodb/data --logpath=/mongodb/log/mongodb.log --bind_ip=0.0.0.0 --fork --shutdown |

方式二,通过mongo shell:
1 | use admin |
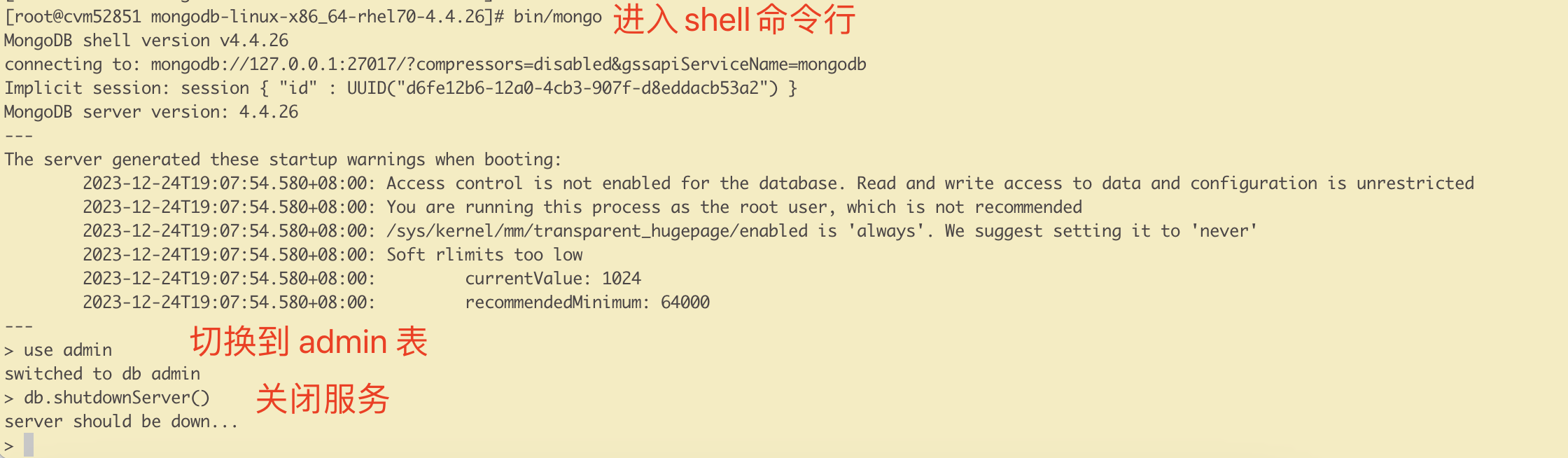
3)Mongo shell常用命令
1 | 进入shell控制台 |
–port 默认端口 27017
–host 连接的主机地址,默认127.0.0.1
进入shell控制台后,第一件事情一定是要进入对应要操作的数据库,才能进行操作!
| 命令 | 说明 |
|---|---|
| show dbs | show databases | 显示数据列表 |
| use 数据库名 | 切换数据库,如果不存在创建数据库 |
| db.dropDatabase() | 删除数据库 |
| show collections | show tables | 显示当前数据库的集合列表 |
| db.集合名.stats() | 查看集合详情 |
| db.集合名.drop() | 删除集合 |
| show users | 显示当前数据库的用户列表 |
| show roles | 显示当前数据库的角色列表 |
| show profile | 显示最近发生的操作 |
| load(“xxx.js”) | 执行一个JavaScript脚本文件 |
| exit quit() | 退出当前shell |
| help | 查看mongodb支持哪些命令 |
| db.help() | 查询当前数据库支持的方法 |
| db.集合名.help() | 显示集合的帮助信息 |
| db.version() | 查看数据库版本 |
数据库操作
1 | # 查看所有库 |
切换数据库时,如果数据库不存在的话则会自动为其创建。
集合操作
1 | # 查看集合 |
创建集合语法
db.createCollection(name, options)
options参数:
| 字段 | 类型 | 描述 |
|---|---|---|
| capped | 布尔 | (可选)如果为true,则创建固定大小的集合。 当达到最大值时,它会自动覆盖最早的文档。 |
| size | 数值 | (可选)为固定集合指定一个最大值(以字节计)。如果 capped 为 true,也 需要指定该字段。 |
| max | 数值 | (可选)指定固定集合中包含文档的最大数量 |
注意:当集合不存在时,向集合中插入文档也会创建集合
4)安全认证
创建管理员账号
- 每个数据库都可以为其创建对应的用户并且赋予 角色。不同的角色可以具备不同的操作权限。
- 如果要创建root管理员的话,就必须切换到 admin数据库
1 | # 切换到admin数据库,创建管理员必须到admin数据库 |
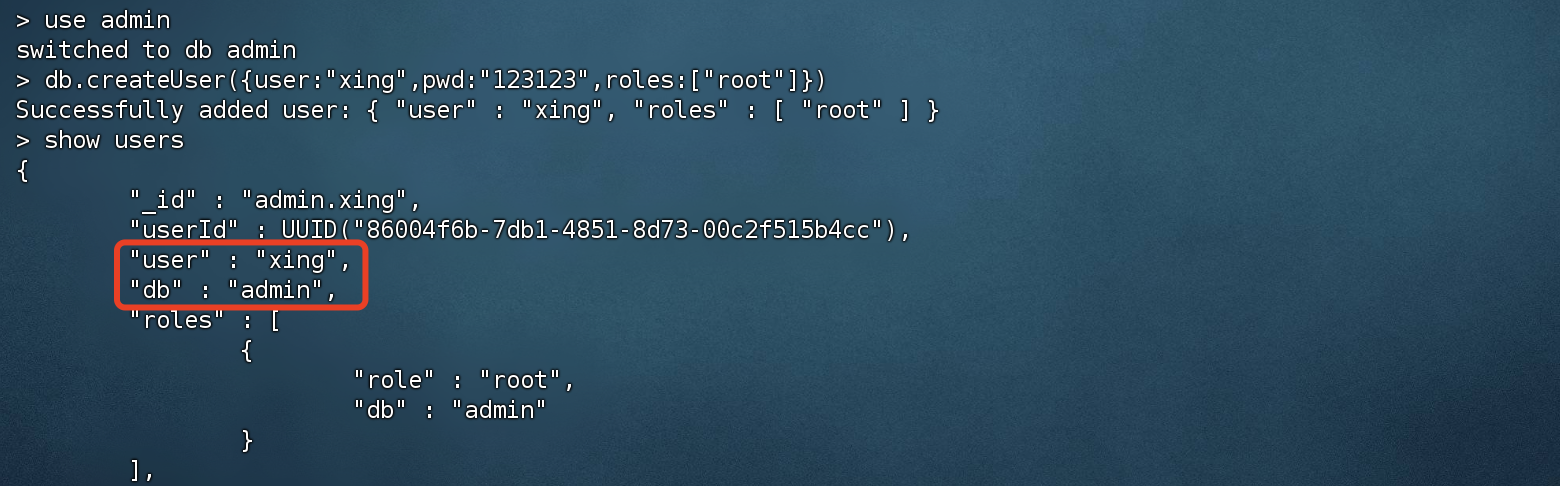
常用权限:
| 权限名 | 描述 |
|---|---|
| read | 允许用户读取指定数据库 |
| dbAdmin | 允许用户在指定数据库中执行管理函数,如索引创建、删除,查看统计或访问system.profile |
| dbOwner | 允许用户在指定数据库中执行任意操作,增、删、改、查等 |
| userAdmin | 允许用户向system.users集合写入,可以在指定数据库里创建、删除和管理用户 |
| clusterAdmin | 只在admin数据库中可用,赋予用户所有分片和复制集相关函数的管理权限 |
| readAnyDatabase | 只在admin数据库中可用,赋予用户所有数据库的读权限 |
| readWriteAnyDatabase | 只在admin数据库中可用,赋予用户所有数据库的读写权限 |
| userAdminAnyDatabase | 只在admin数据库中可用,赋予用户所有数据库的userAdmin权限 |
| dbAdminAnyDatabase | 只在admin数据库中可用,赋予用户所有数据库的dbAdmin权限 |
| root | 只在admin数据库中可用。超级账号,超级权限 |
校验用户密码是否正确
1 | # 切换到对应的数据库后,才可以正确校验 |
创建测试数据库和用户
1 | # 切换到数据库,不存在则自动创建数据库 |
注意:默认情况下mongoDB不会开启认证模式,如果我们要使用用户名密码登录的话,就要以 认证模式开启。
1 | # 关闭掉原本启动的mongo服务端 |
启用认证模式后登录mongoDB:
1 | # -u 用户名,-p 密码,指定要登录的数据库 |

5.MongoDB文档操作
1)插入文档
3.2 版本之后新增了 db.collection.insertOne() 和 db.collection.insertMany(),推荐使用这两个API完成插入。
新增单个文档
insertOne: 支持writeConcern 确认节点参数(可选,参数非必填,默认为1)
db.collection.insertOne( <document>, { writeConcern: <document> } )> writeConcern:写入多少个节点才返回成功,默认为1 。代表本机写入成功就可以返回 > > ordered:指定是否按顺序写入,默认 true,按顺序写入1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
> writeConcern:写入到多少个节点才返回成功确认。<span style="color:red;">**数字越大,效率越低**</span>,可靠性越高。
>
> + 0 - 不关心是否写入成功,直接返回
> + 1~集群最大节点数量,假设我们有3台节点,writeConcern设置成了2,那就必须保证2个节点写入成功后才会返回成功
> + majority:<span style="color:red;">**一半以上的节点**</span>写入成功 才会返回成功
+ insert:如果插入的数据主键已经存在,则会抛 DuplicateKeyException 异常,提示主键重复,不保 存当前数据。
+ save: 如果 _id 主键存在则更新数据,如果不存在就插入数据。
<img src="https://image.javaxing.com/document/image-20231225153206637.png" alt="image-20231225153206637" style="zoom:50%;" />
> 需要注意,insertOne和insert、save 的返回值不太一样,acknowledged = true 代表插入成功。
#### 批量新增文档
+ insertMany:向指定集合中插入多条文档数据
+ ```sql
# example
db.collection.insertMany(
[ <document 1> , <document 2>, ... ],
{
writeConcern: <document>,
ordered: <boolean>
}
)
# 插入实测
> db.user.insertMany([{name:"王五"},{name:"张伟"}])
{
"acknowledged" : true,
"insertedIds" : [
ObjectId("658930d7d3782c6a9883d358"),
ObjectId("658930d7d3782c6a9883d359")
]
}
insert和save也可以实现批量插入,但是更多我们推荐使用新的api。
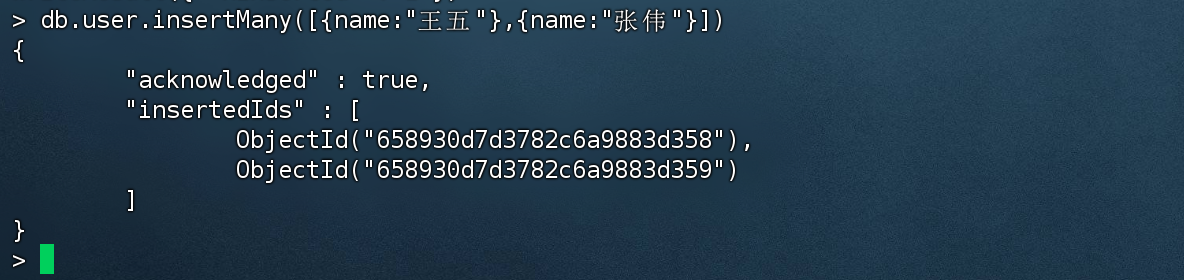
批量插入测试
因为mongo shell 是以JS编写出来的,所以支持js的语法,我们将以下代码写入到js文件中。
1 | // 值得注意的是,这个路径是相对路径,mongoDB 的bin在哪里,文件就放哪里 |
Mongo shell读取的位置是相对路径,所以要与 mongoDB 的bin目录 放一起,不可以在该目录上级,否则会找不到文件。
执行:
1 | load("books.js") |

2)查询文档
简单查询
1 | db.collection.find(query, projection) |
- collection:对应的集合名称,可以理解成 MySQL的表名
- query :可选,使用查询操作符指定查询条件
- projection:可选,只返回的字段,可以理解为 mysql select 后面的字段
1 | > db.books.find() |

单条查询
1 | > db.books.findOne() |
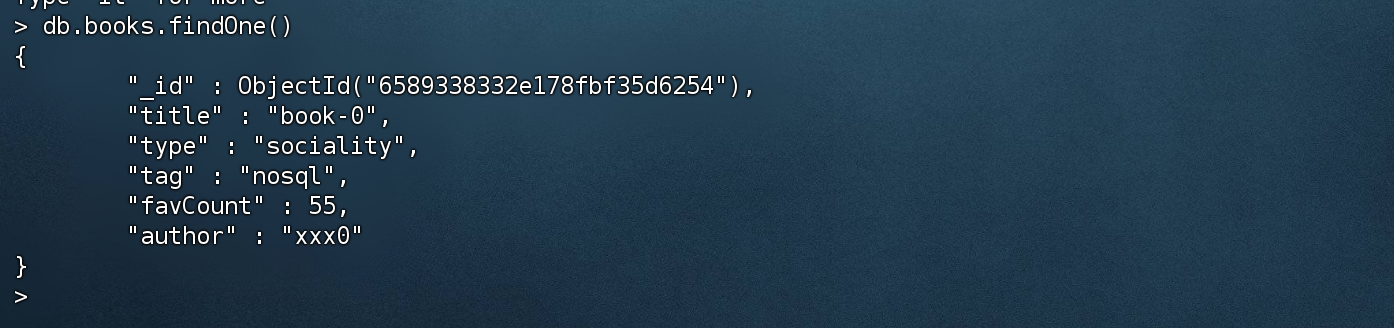
只返回想要的数据
1 | # 查询title = book-19 并只返回title、type |

条件查询
1 | #查询带有nosql标签的book文档: |
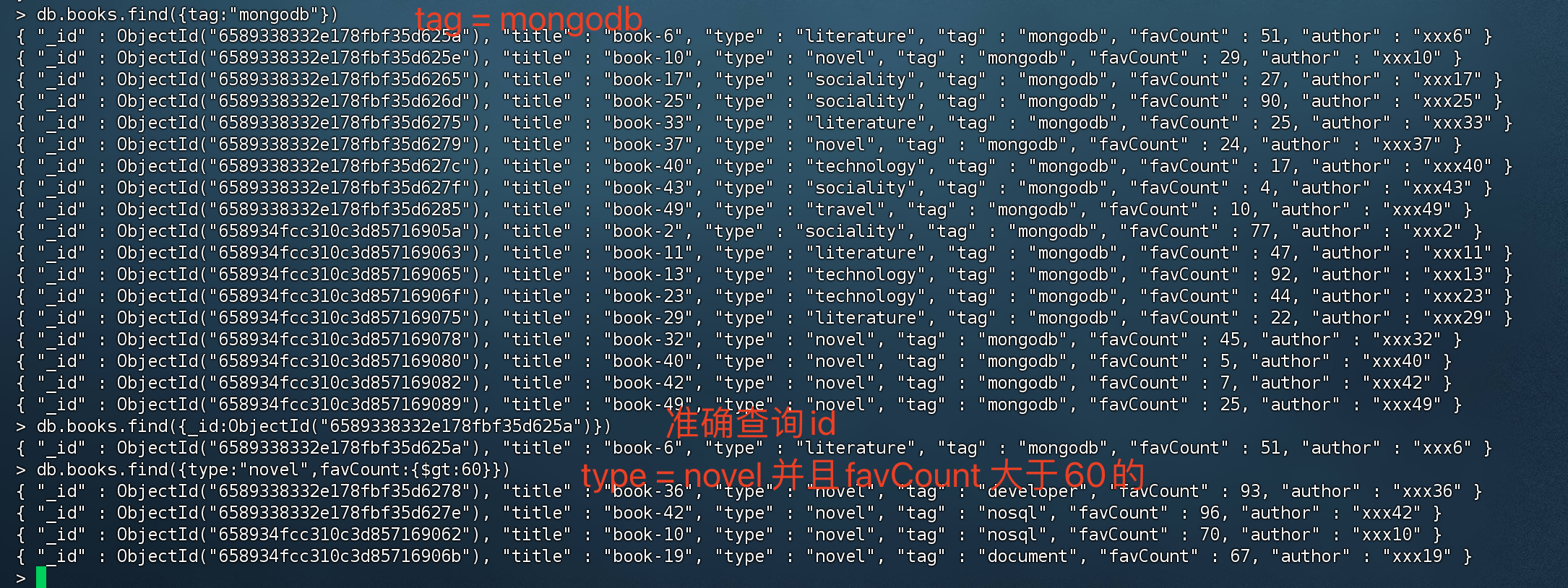
查询条件对照表
| SQL | MQL |
|---|---|
| a = 1 | {a: 1} |
| a <> 1 | {a: {$ne: 1}} |
| a > 1 | {a: {$gt: 1}} |
| a >= 1 | {a: {$gte: 1}} |
| a < 1 | {a: {$lt: 1}} |
| a <= 1 | {a: {$lte: 1}} |
a 代表字段名,如 上面的截图 a就是 favCount。
查询逻辑对照表
| SQL | MQL |
|---|---|
| a = 1 AND b = 1 | {a: 1, b: 1}或{$and: [{a: 1}, {b: 1}]} |
| a = 1 OR b = 1 | {$or: [{a: 1}, {b: 1}]} |
| a IS NULL | {a: {$exists: false}} |
| a IN (1, 2, 3) | {a: {$in: [1, 2, 3]}} |
查询逻辑运算符
$lt: 存在并小于
$lte: 存在并小于等于
$gt: 存在并大于
$gte: 存在并大于等于
$ne: 不存在或存在但不等于
$in: 存在并在指定数组中
$nin: 不存在或不在指定数组中
$or: 匹配两个或多个条件中的一个
$and: 匹配全部条件
排序&分页
排序
在 MongoDB 中使用 sort() 方法对数据进行排序
1 | #指定按收藏数(favCount)降序返回 |
sort 参数1 代表正序,-1 代表降序。

分页
skip用于指定跳过记录数,limit限定返回结果数量。可以在执行find命令的同时指定skip、limit
1 | # 从0开始查询,返回10条记录 |
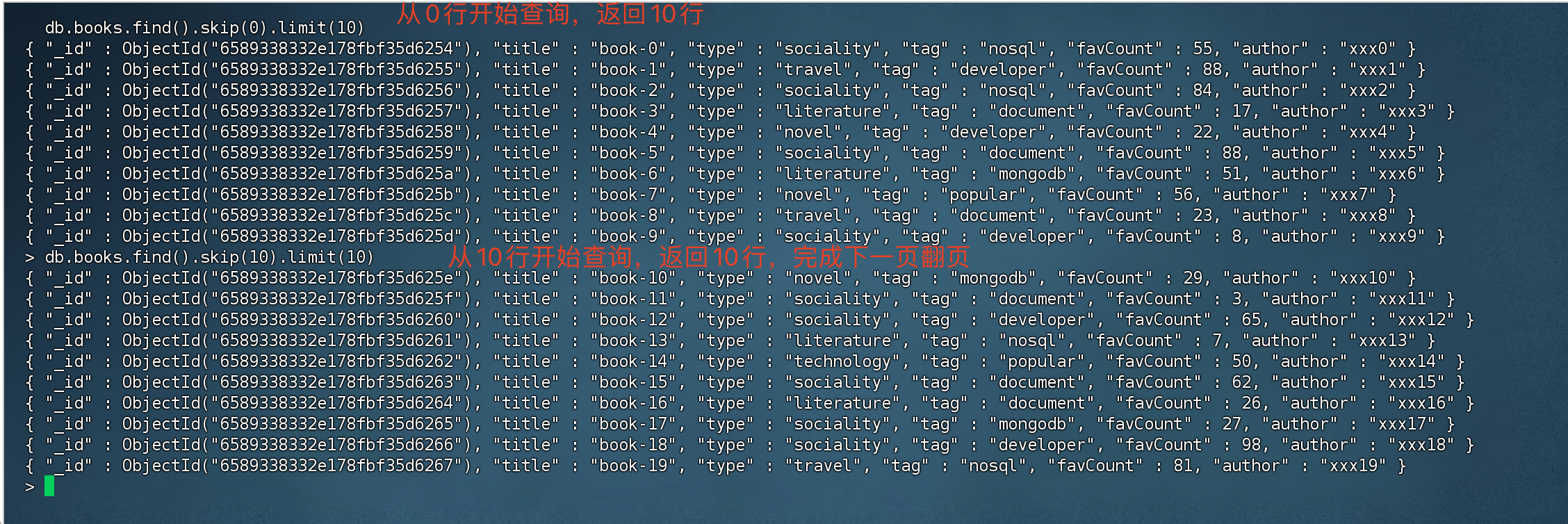
如果要完成分页查询的话,就设定skip 和limit即可。下次查询的话 就skip 通过已经查询过的数量就行。
正则表达式查询
MongoDB 使用 $regex 操作符来设置匹配字符串的正则表达式。
1 | //使用正则表达式查找type包含 so 字符串的book |
3)更新文档
1 | db.collection.update(query,update,options) |
- collection:创建的集合名称,类似于 MySQL的表;
- query:描述更新的查询条件;
- update:描述更新的动作及新的内容;
- options:描述更新的选项
- upsert: 可选,如果不存在update的记录,是否插入新的记录。默认false,不插入
- multi: 可选,是否按条件查询出的多条记录全部更新。 默认false,只更新找到的第一条记录
- writeConcern :可选,决定一个写操作落到多少个节点上才算成功。
更新操作符
| 操作符 | 格式 | 描述 |
|---|---|---|
| $set | {$set:{field:value}} | 指定一个键并更新值,若键不存在则创建 |
| $unset | {$unset : {field : 1 }} | 删除一个键 |
| $inc | {$inc : {field : value } } | 对数值类型进行增减 |
| $rename | {$rename : {old_field_name : new_field_name } } | 修改字段名称 |
| $push | { $push : {field : value } } | 将数值追加到数组中,若数组不存在则会进行初始化 |
| $pushAll | {$pushAll : {field : value_array }} | 追加多个值到一个数组字段内 |
| $pull | {$pull : {field : _value } } | 从数组中删除指定的元素 |
| $addToSet | {$addToSet : {field : value } } | 添加元素到数组中,具有排重功能 |
| $pop | {$pop : {field : 1 }} | 删除数组的第一个或最后一个元素 |
更新单个文档
1 | # 查询id为6589338332e178fbf35d6267,然后 favCount 自增+1 |
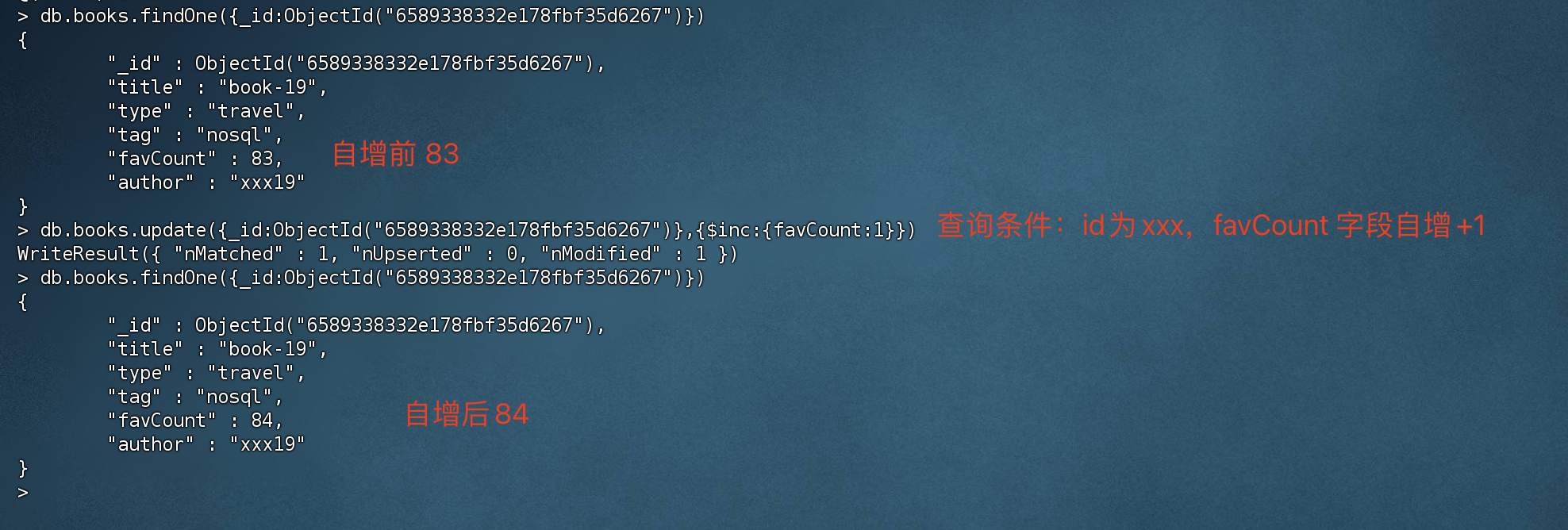
更新多个文档
默认情况下,MongoDB只会更新匹配到的第一个文档,如果需要更新多个文档,则可以使用multi选项。
1 | # 匹配type:travel,设置publishedDate为最新时间,如果字段不存在的话则为其创建该字段,multi:更新多条数据 |
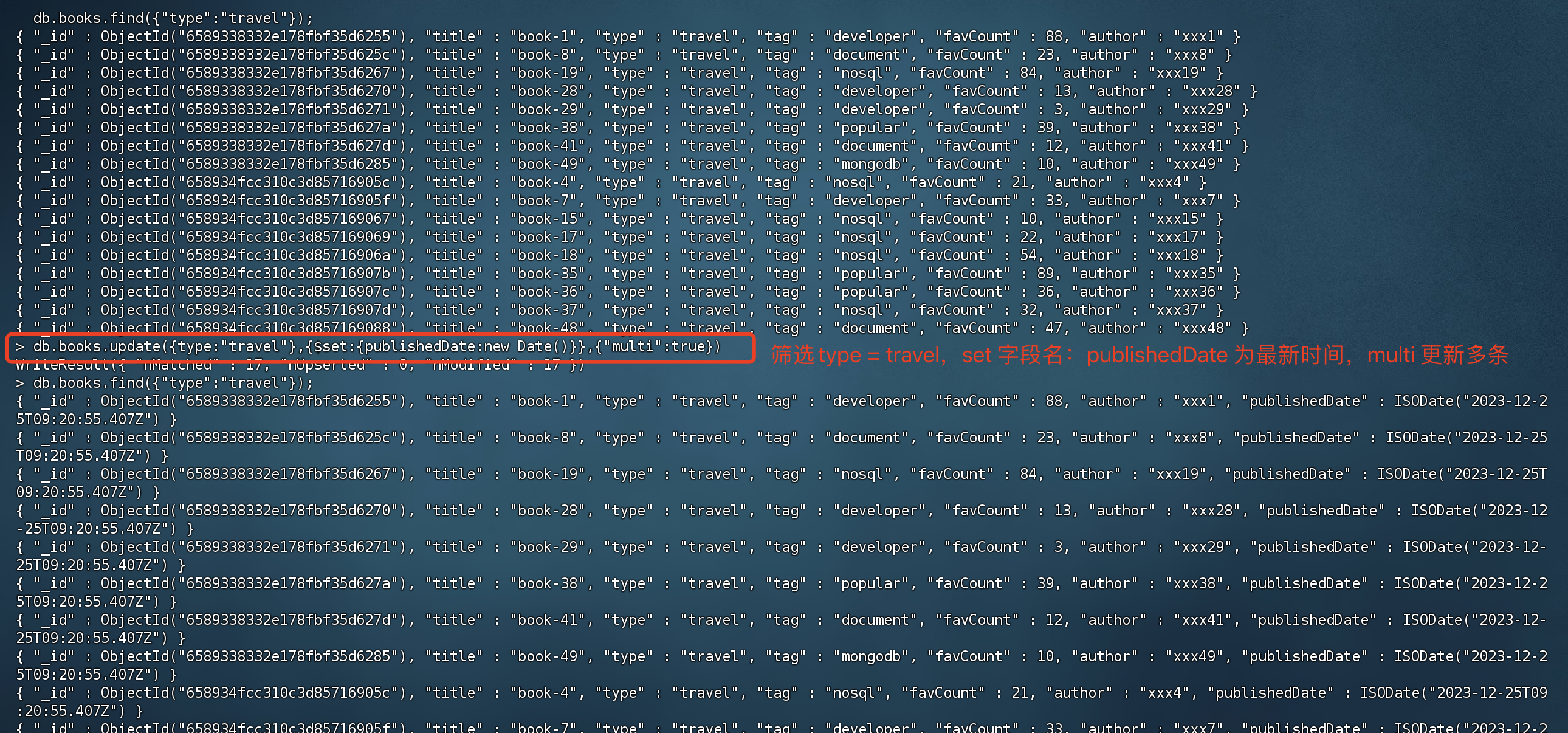
update命令的选项配置较多,为了简化使用还可以使用一些快捷命令:
注意:快捷命令的API接口返回值不同,这个需要单独区分。
updateOne:更新单个文档
> db.books.updateOne({type:"travel"},{$set:{publishedDate:new Date()}}) { "acknowledged" : true, "matchedCount" : 1, "modifiedCount" : 1 }1
2
3
4
5
6
+ <span style="color:red;">**updateMany**</span>:更新多个文档
+ ```sql
> db.books.updateMany({type:"travel"},{$set:{publishedDate:new Date()}})
{ "acknowledged" : true, "matchedCount" : 17, "modifiedCount" : 17 }
replaceOne:替换单个文档
使用upsert命令
upsert是一种特殊的更新,其表现为如果目标文档不存在,则执行插入命令。
1 | db.books.update( |
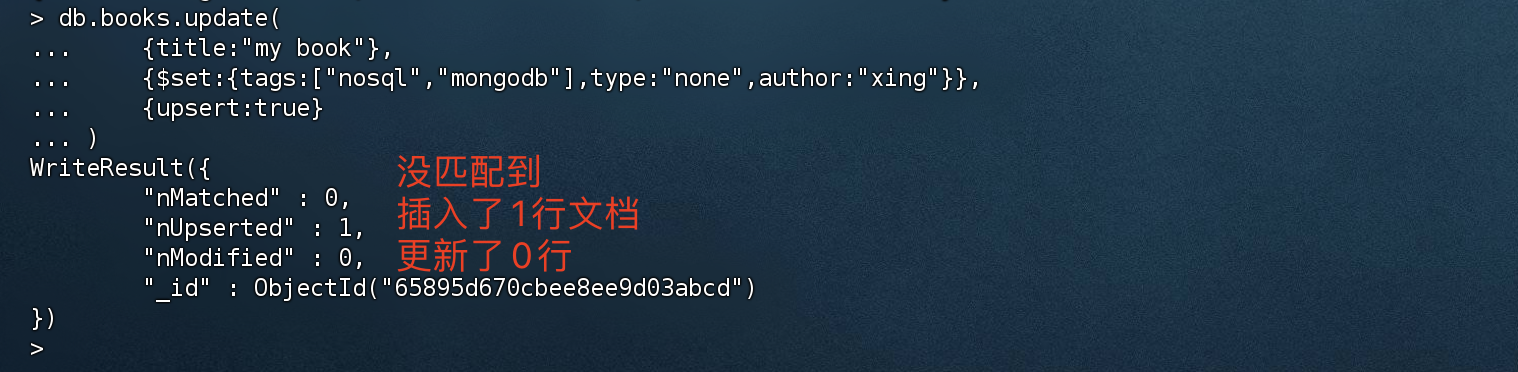
nMatched:0 没有匹配到数据
nUpserted:1 插入了1行文档
nModified:0 更新了0行数据
实现replace替换
如果我们想实现替换功能,可以使用命令:replace。
如果更新描述中不包含任何操作符,那么 MongoDB会实现文档的replace功能,替换掉相应内容。
1 | # 前面是要查询替换的字段和条件,后面是要替换的 字段 |

findAndModify
更新之后并返回 更新前 或更新后的结果。
1 | # 执行后,返回更新之前的数据 |

与findAndModify语义相近的命令如下:
- findOneAndUpdate:更新单个文档并返回更新前(或更新后)的文档。
- findOneAndReplace:替换单个文档并返回替换前(或替换后)的文档。
4)删除文档
delete删除(官方推荐)
1 | # 根据条件删除 第一个文档 |
remove删除
1 | # 根据条件删除指定文档 |
注意,不论是remove还是delete,要删除该集合下所有文档时,建议直接把整个集合drop,因为drop的效率更高。
5)生产实践建议
关于文档结构
- 防止使用太长的字段名(浪费空间)
- 因为mongoDB索引树采用的是B+Tree结果,字段越长 叶子节点能存放的内容越少
- 防止使用太深的数组嵌套(超过2层操作比较复杂)
- 不使用中文,标点符号等非拉丁字母作为字段名
- 在程序员的世界里,不论是代码还是数据库都尽可能的不要使用中文,避免一些不必要的情况出现
关于写操作
- update 语句里只包括需要更新的字段
- 按需更新,只更新需要更新的字段,比如 你只需要更新一个age,别全部字段都更新了,这样做只会降低更新效率
- 尽可能使用批量插入来提升写入性能
- 使用TTL自动过期日志类型的数据
- 对于一些不重要,或需要定期删除的数据,如 日志等,可以使用TTL索引让数据定时过期,腾出更多的存储空间
6.数据类型和高级特性
1)BSON支持的数据类型
MongoDB中,一个BSON文档最大大小为16M,文档嵌套的级别不超过100
https://docs.mongodb.com/v4.4/reference/bson-types/
| Type | Number | Alias | Notes |
|---|---|---|---|
| Double | 1 | “double” | |
| String | 2 | “string” | |
| Object | 3 | “object” | |
| Array | 4 | “array” | |
| Binary data | 5 | “binData” | 二进制数据 |
| Undefined | 6 | “undefined” | Deprecated. |
| ObjectId | 7 | “objectId” | 对象ID,用于创建文档ID |
| Boolean | 8 | “bool” | |
| Date | 9 | “date” | 日期类型 |
| Null | 10 | “null” | |
| Regular Expression | 11 | “regex” | 正则表达式 |
| DBPointer | 12 | “dbPointer” | Deprecated. |
| JavaScript | 13 | “javascript” | |
| Symbol | 14 | “symbol” | Deprecated. |
| JavaScript code with scope | 15 | “javascriptWithScope” | Deprecated in MongoDB 4.4. |
| 32-bit integer | 16 | “int” | |
| Timestamp | 17 | “timestamp” | |
| 64-bit integer | 18 | “long” | |
| Decimal128 | 19 | “decimal” | New in version 3.4. |
| Min key | -1 | “minKey” | 表示一个最小值 |
| Max key | 127 | “maxKey” | 表示一个最大值 |
$type操作符(用不到)
$type操作符基于BSON类型来检索集合中匹配的数据类型,并返回结果。
1 | 查询title 的类型为 int类型的数据 |
日期类型
MongoDB的日期类型使用UTC(Coordinated Universal Time)进行存储,也就是+0时区的时间。
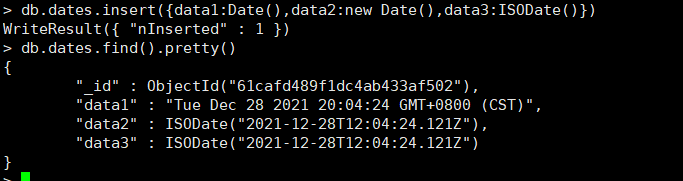
1 | db.dates.insert([{data1:Date()},{data2:new Date()},{data3:ISODate()}]) |
使用new Date与ISODate最终都会生成ISODate类型的字段(对应于UTC时间)
2)ObjectId生成器
MongoDB集合中的所有文档都有一个唯一的_id字段,ObjectId并非Mongo服务端生成,而是客户端生成的。
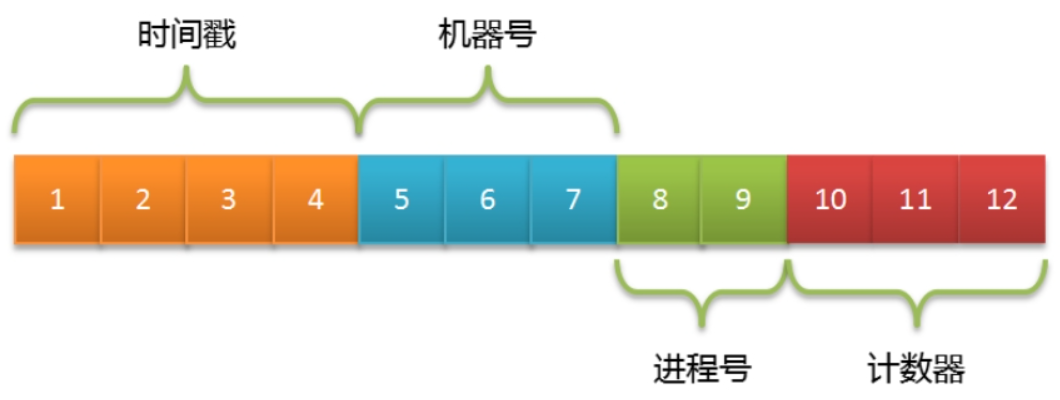
ObjectId组成一共分为三个部分:
- 4字节表示Unix时间戳(秒)。
- 5字节表示随机数(机器号+进程号唯一)。
- 3字节表示计数器(初始化时随机)。
3)内嵌文档和数组
内嵌文档
一个文档中可以内嵌多条数据,而不需要在建立其他集合然后进行关联。
1 | db.books.insert({ |
该文档 里面嵌套 author 作者信息,作者信息包含了 名词、性别、国家,当我们查询该数据时,会将author信息一同返回。
在MySQL中需要去查询和修改嵌套数据的话,需要单独去查表。但是在mongoDB中可以直接对其进行查询和操作。
查询 title = 瓦尔登湖的文档
1 | // 查询 title = 瓦尔登湖的文档 |
直接查询嵌套数据
1 | // 查询 文档的内嵌数据 名称为xxx的 |
更新内嵌文档数据
1 | // 更新作者名为xxx的数据,新增一个state 州 为NY(纽约) |
数组
在文档中一个字段允许存放多个数据(数组),如tag标签。
1 | // 根据条件新增 tags 标签 |
tags 标签字段是个数组,里面包含了多个标签。
只返回需要的字段
1 | > db.books.findOne({"author.name":"亨利·戴维·梭罗"},{title:1,tags:1}) |
数组分割
我们可以通过$slice 指定数组分割位置,如:只返回最后一个 tag 写-1,返回第一个写1
1 | > db.books.findOne({"author.name":"亨利·戴维·梭罗"},{title:1,tags:{$slice:-1} }) |
数组末尾追加元素,可以使用$push操作符
1 | # 匹配条件 往数组末尾 追加一个标签 = 治愈丛书 |
$push配合$each操作符配合可以用于添加多个元素
$push只能追加一个元素,而$push 配合$each 可以追加多个元素。
1 | > db.books.updateOne({ "author.name":"亨利·戴维·梭罗"},{ $push:{tags:{ $each:["大师作品","感人系列"] } } }) |
根据数组的元素进行查询
1 | > db.books.findOne({tags:"哲学文书"}) |
嵌套型数组
数组可以是基本元素类型,也可以是嵌套结构。
举个最常见的例子,就是商品的SKU信息。如果要将这样一个信息存入到MySQL中,需要创建多张表进行关联。
而在MongoDB中,直接可以进行嵌套,并存入一条文档中:
1 | # 插入多个商品文档 |
筛选出颜色为 雅川青的商品
当我们需要对商品里面的规格进行查询时,可以使用$elemMatch,它可以匹配到 数组里面内嵌文档里面的元素。
1 | db.goods.find({ |

组合式条件查询 检索规格
如果存在多个查询条件,可以使用多个$elemMatch 检索规格里面的数组元素。
1 | db.goods.find({ |

固定集合
创建集合时就要指定好集合大小和最大存储文档数量。
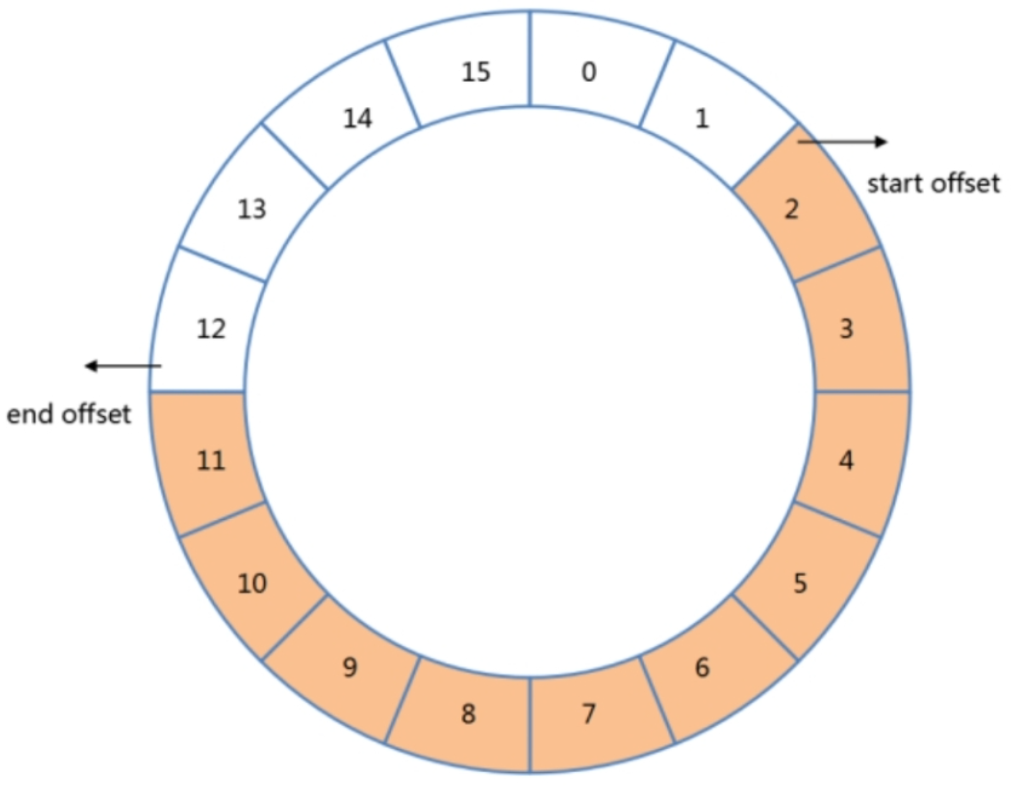
可以将固定集合想象为环形队列,我们往队列末尾里面写入数据,如果队列满了,之前写入的文档会被覆盖掉。
固定集合优点:
- 固定集合底层使用的顺序IO,普通集合使用的是随机IO,因此顺序IO的读写性能是非常高的
固定集合缺点:
- 无法动态修改存储的上限,如果要修改size或max的话,必须先删除集合再重新创建
- 无法删除已有的数据
- 对已有的数据修改的话,修改之前和修改之后的文档存储大小必须一致(基本做不到)
- 默认情况下只有_id主键索引,新增索引会降低写入性能,但是可以提高查询效率
- 固定集合不支持分片
适用场景
固定集合一般用于存放临时的数据,或需要定期删除的数据。如:
- 系统日志
- 一般系统日志都需要定期删除,或者满多大空间后就会覆盖写入之前的数据
- 存储少量的数据,如 最新的N条数据
创建固定集合
1 | > db.createCollection("systemLogs",{capped:true,size:4096,max:10}) |
size:集合占用最大空间,如4096字节(4KB)
max:集合的文档最大数量,如 10条
只要达到任意一个条件,就会认定为集合已经满了,后续写入的数据会覆盖写入之前的数据
查看集合占用空间
1 | > db.systemLogs.stats() |

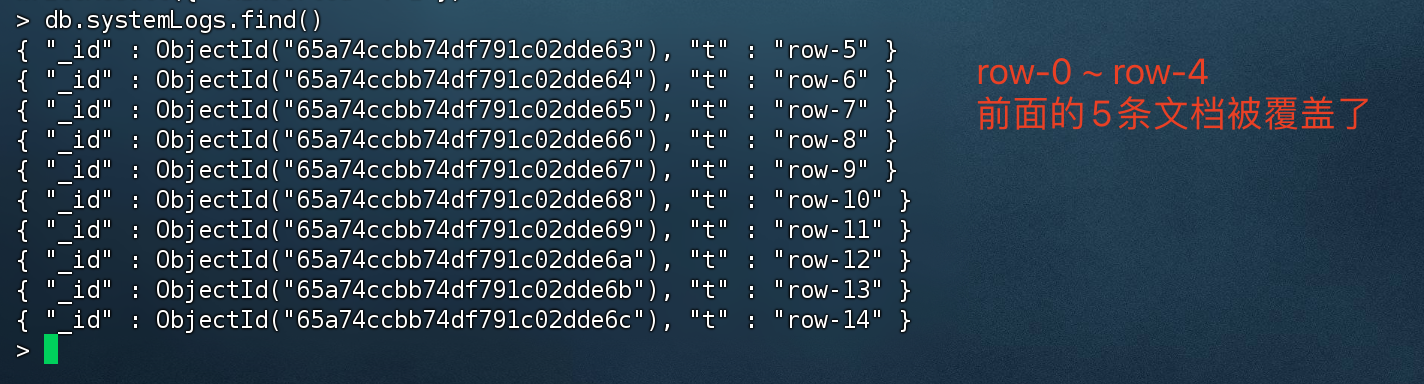
固定集合测试
我们尝试插入15条文档后,由于固定集合上限是10条文档,后续的5条文档会覆盖之前的数据。
1 | for(var i=0;i<15;i++){ |
4)WiredTiger读写模型详解
MongoDB从3.0开始引入可插拔存储引擎的概念。目前主要有MMAPV1、WiredTiger存储引擎可供选择。
读缓存
理想情况下,MongoDB可以提供近似内存式的读写性能。redTiger引擎实现了数据的二级缓存,第一层是操作系统的页面缓存,第二层则是引擎提供的内部缓存。
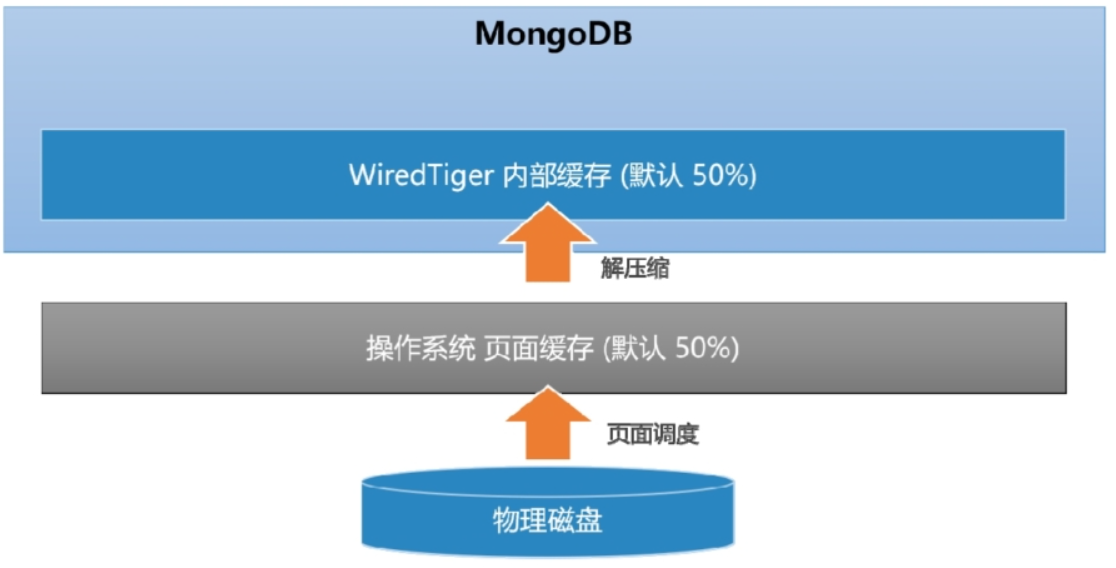
读取数据时的流程如下:
- 数据库发起Buffer I/O读操作,由操作系统将磁盘数据页加载到文件系统的页缓存区。
- 引擎层读取页缓存区的数据,进行解压后存放到内部缓存区。
- 在内存中完成匹配查询,将结果返回给应用。
MongoDB为了尽可能保证业务查询的“热数据”能快速被访问,其内部缓存的默认大小达到了内存的一半,所以启动mongoDB时默认会占用一半内存。
写缓存
当数据发生写入时,MongoDB并不会立即持久化到磁盘上,而是先在内存中记录这些变更,之后通过CheckPoint机制将变化的数据写入磁盘。
MongoDB单机保证数据不丢失主要依赖两个机制:
- CheckPoint(检查点)机制
- Journal日志
CheckPoint(检查点)机制
默认情况下,MongoDB每60s建立一次CheckPoint(快照持久化)。每次CheckPoint都会把内存中所有数据生成快照并进行持久化(落盘)。
疑问:
如果在下次CheckPoint之前宕机了,那么在CheckPoint之前的数据都会丢失,mongoDB如何挽救呢?
Journal日志
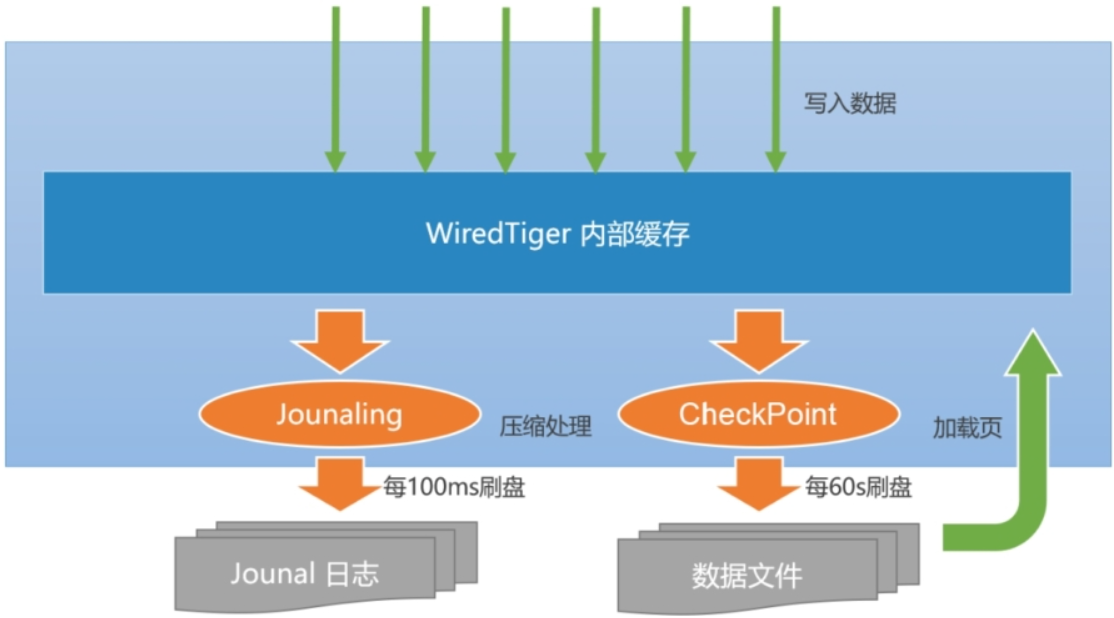
Journal是一种预写式日志机制,主要弥补因为没来得及CheckPoint持久化导致的数据丢失。
每个写操作的请求都会写入到Journal日志中,而默认情况下,Journal缓冲区每100ms执行一次持久化。
Journal 100ms持久化一次,在这么短的时间内丢失数据时极为罕见的情况,如果担心Journal日志在持久化之前宕机导致部分数据丢失,可以在 mongoDB写入命令的时候执行journal:true,这样写入数据的时会马上触发journal持久化。
数据恢复流程:
- 由于每隔60s会进行一次CheckPoint,如果数据丢失也仅仅丢失60秒的数据,所以mongoDB先恢复上一个CheckPoint检查点后,在增量的恢复Journal日志数据,从而起到了 数据不丢失的效果。
触发Journal日志持久化情况:
- 每隔100ms 就会触发一次
- Journal日志达到100MB时
- mongoDB增删改命令时,后面增加 journal:true ,会马上触发持久化
CheckPoint和Journal的性能去呗:
- CheckPoint 是随机IO写入,频繁写入对磁盘性能影响比较大。
- Journal是顺序IO写入,频繁写入对磁盘性能没影响。
6. MongoDB整合SpringBoot
1)环境搭建
项目代码:https://files.javaxing.com/Java%08Demo/spring-boot-mongo-demo-01.zip
引入依赖
1 | <parent> |
配置application.yml
1 | spring: |
authSource=appDb 认证数据库(用户在哪个数据库创建的,就写哪个)
注入mongoTemplate
1 |
|
2)集合操作
1 | .junit.Test |
3)文档操作
相关注解
@Document
- 修饰范围: 用在类上
- 作用: 用来映射这个类的一个对象为mongo中一条文档数据
- 属性:( value 、collection )用来指定操作的集合名称
@Id
- 修饰范围: 用在成员变量、方法上
- 作用: 将成员变量的值映射为文档的_id的值
@Field
- 修饰范围: 用在成员变量、方法上
- 作用: 将成员变量的值映射到文档的字段
- 属性:( name , value )用来指定在文档中 key的名称,默认为成员变量名
@Transient
修饰范围:用在成员变量、方法上
作用:用来指定此成员变量不参与文档的序列化
创建实体类
1 | //对应employee集合中的一个文档 |
@Field 如果有值,代表将值映射到文档的字段,那么在java中取值的时候 就可以通过name取到nickName字段的值
添加文档
1 | .junit.Test |
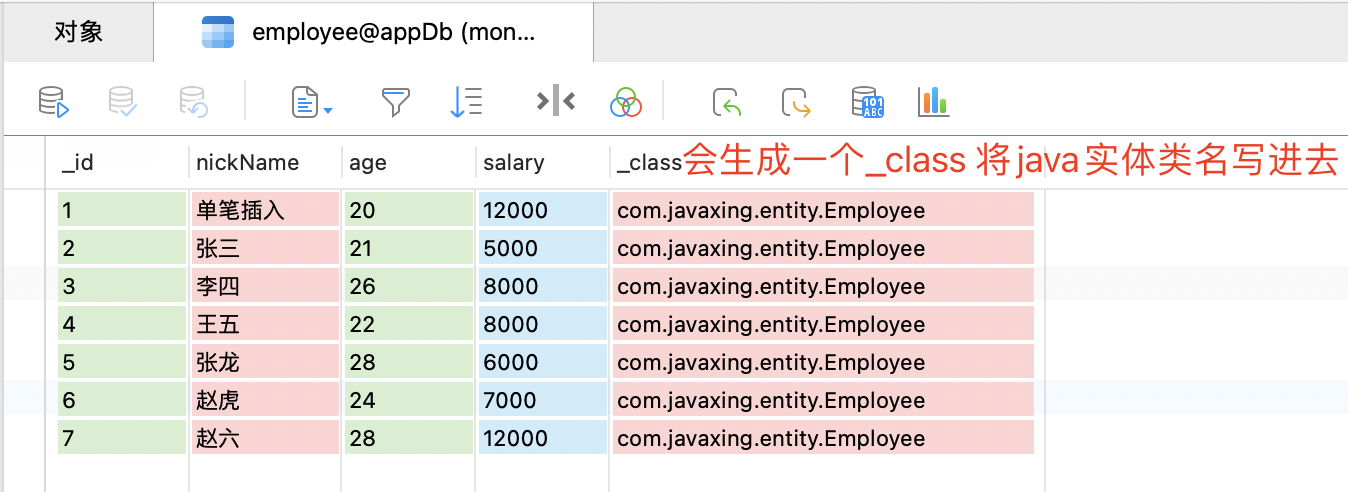
- save 数据不存在会插入,存在的话会更新
- insert 数据不存在会插入,存在的话会抛出异常,但是该方法支持 批量插入
- 通过SpringData插入成功后,会发现 自动多了一个字段_class,存储了实体类的全限定路径,目的是为了查询的时候能将文档转换成java类型。
查询文档
Criteria是标准查询的接口,可以组合多个条件进行查询。
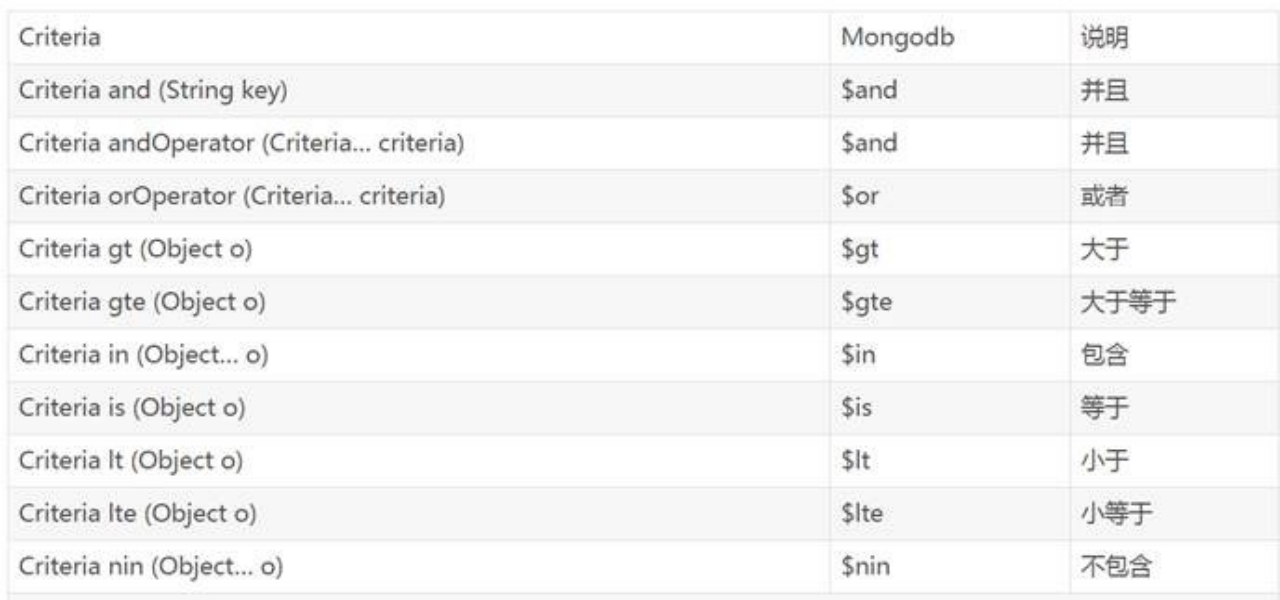
简单查询
1 | .junit.Test |
简单条件查询
1 | .junit.Test |
查询条件可以自定义,具体方法名称上面的截图有写。
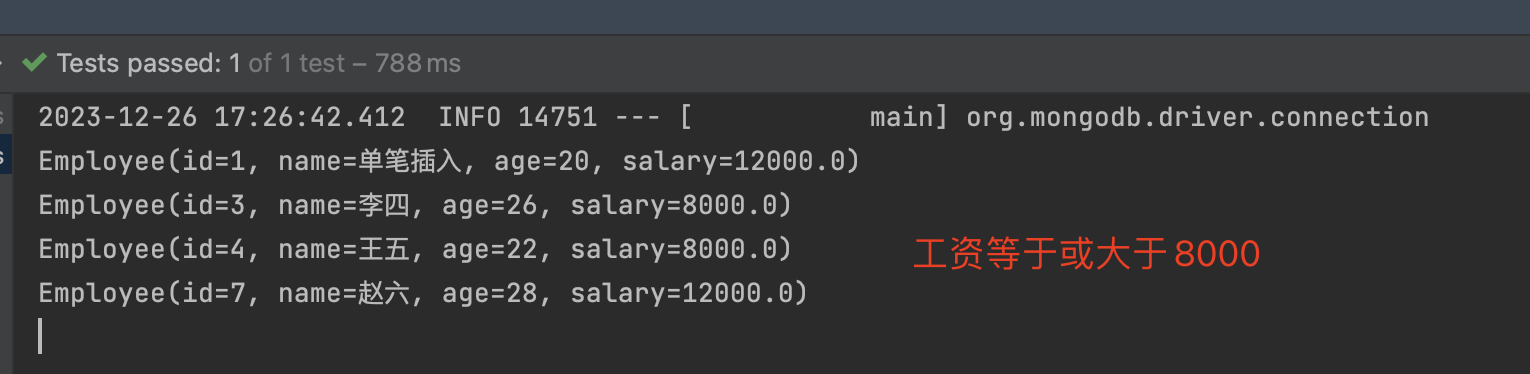
Query query = new Query(Criteria.where(“salary”).gte(8000));
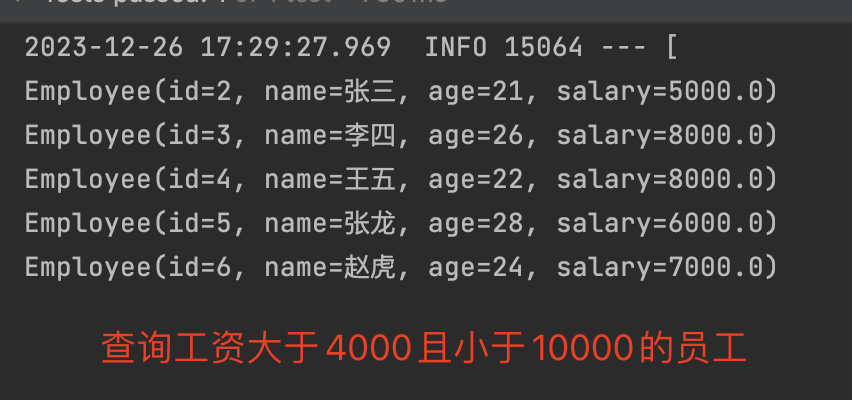
Query query = new Query(Criteria.where(“salary”).gt(4000).lt(10000));
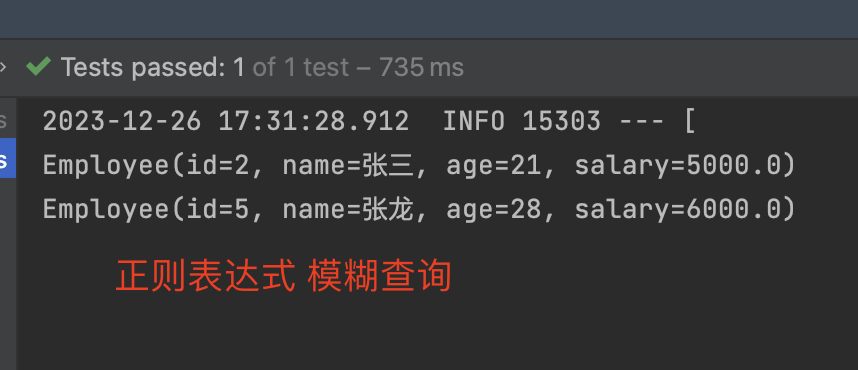
模糊查询
1 | .junit.Test |
and、or 多条件查询
如果查询的情况较为复杂的话,需要使用到and 或 or,可以创建Criteria 来实现多条件查询。
1 | .junit.Test |
- 先创建Criteria并设置 查询条件
- 创建Query,将Criteria 传入Query
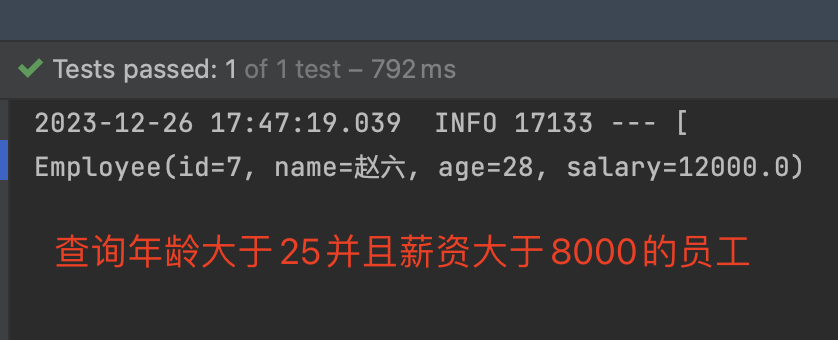
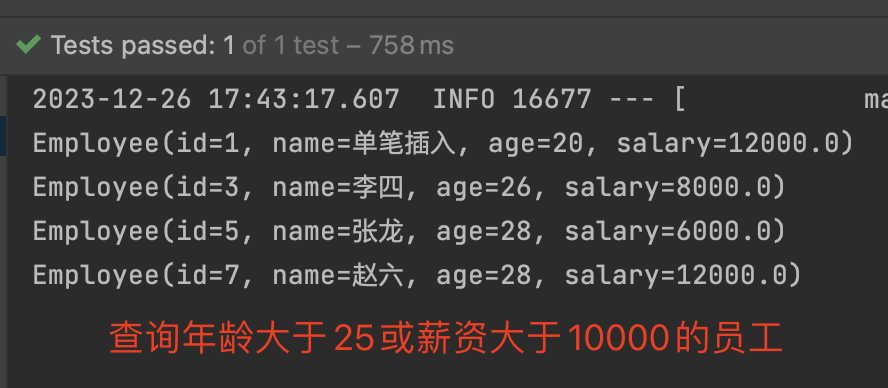
sort排序
1 | .junit.Test |
query.with(Sort.by(Sort.Order.desc(“salary”))); 根据salary工资字段 降序排序
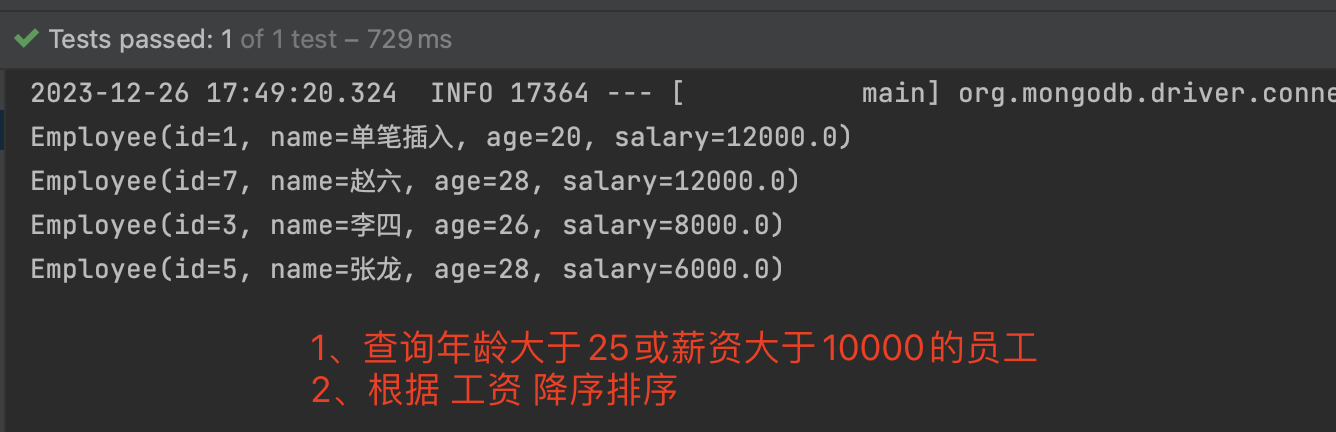
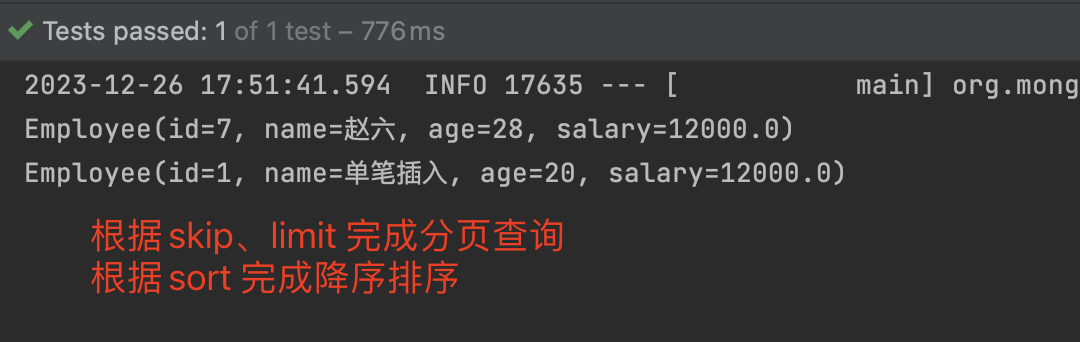
分页查询
1 | .junit.Test |
- skip 跳过的数量
- limit 每页显示数量
- 这里我们除了设置skip和limit外,还设置了sort 排序,他们是可以组合使用的。
通过JSON字符串查询
1 | .junit.Test |
更新文档
如果更新成功的话,会返回影响的行数。如果更新后和更新前的结果相同,则返回0。
- updateFirst() 只更新满足条件的第一条记录
- updateMulti() 更新所有满足条件的记录
- upsert() 没有符合条件的记录则插入数据
1 | .junit.Test |
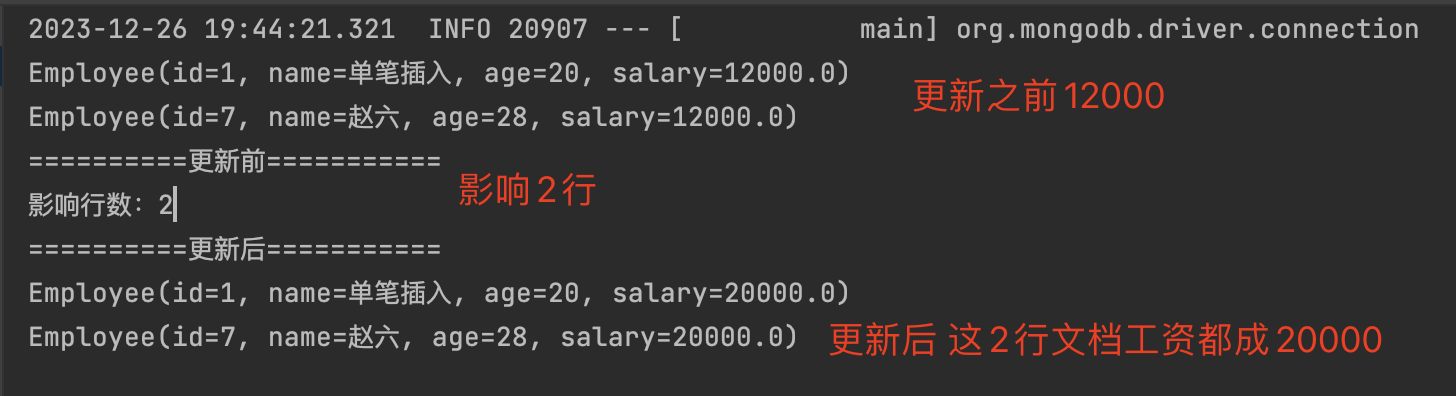
updateFirst() 只更新满足条件的第一条记录
1 | UpdateResult updateResult = mongoTemplate.updateFirst(query, update,Employee.class); |
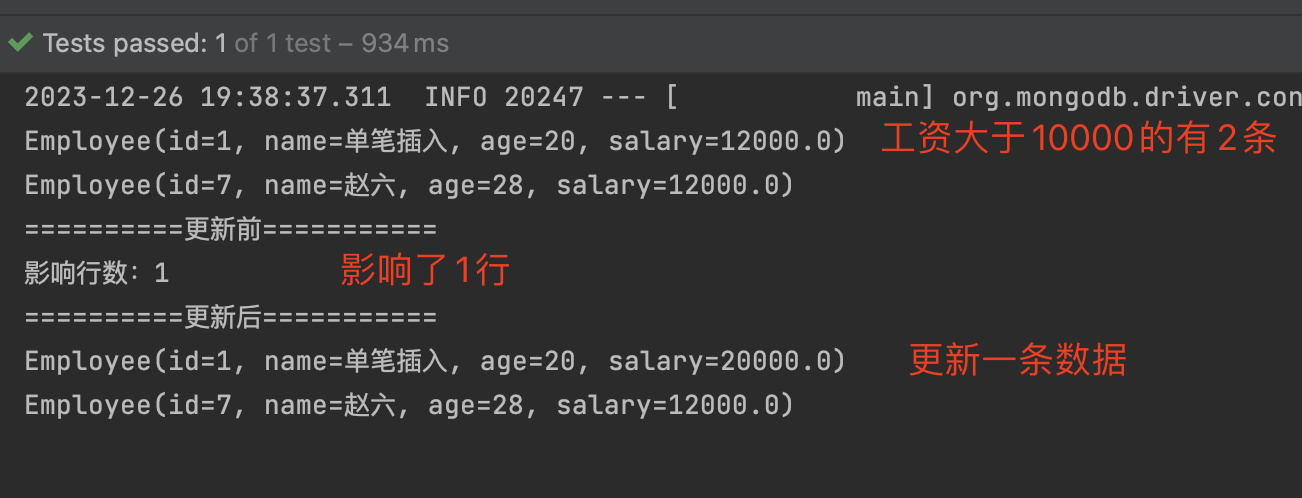
updateMulti() 更新满足条件的所有记录
1 | UpdateResult updateResult = mongoTemplate.updateMulti(query, update,Employee.class); |
upsert,没有符合条件的记录则插入数据
1 | UpdateResult updateResult = mongoTemplate.upsert(query, update,Employee.class); |
删除文档
1 | .junit.Test |
new Query() 如果查询条件为空,则代表 删除所有文档。如果要删除所有文档,建议使用dropCollection方法。
4)去掉_class 关键字
如果在大数据量的情况下,去掉_class属性后,可以明显的提高查询效率。写入数据时,也不会写入_class属性。
1 |
|





