RabbitMQRabbitMQ生产环境常见问题
RabbitMQ如何保障消息不丢失
这个问题是所有MQ的共性问题,所有MQ都会面临 数据丢失的情况,但是不同的MQ产品有不同的解决方案,这里只描述 RabbitMQ。
1)可能丢失消息的环节
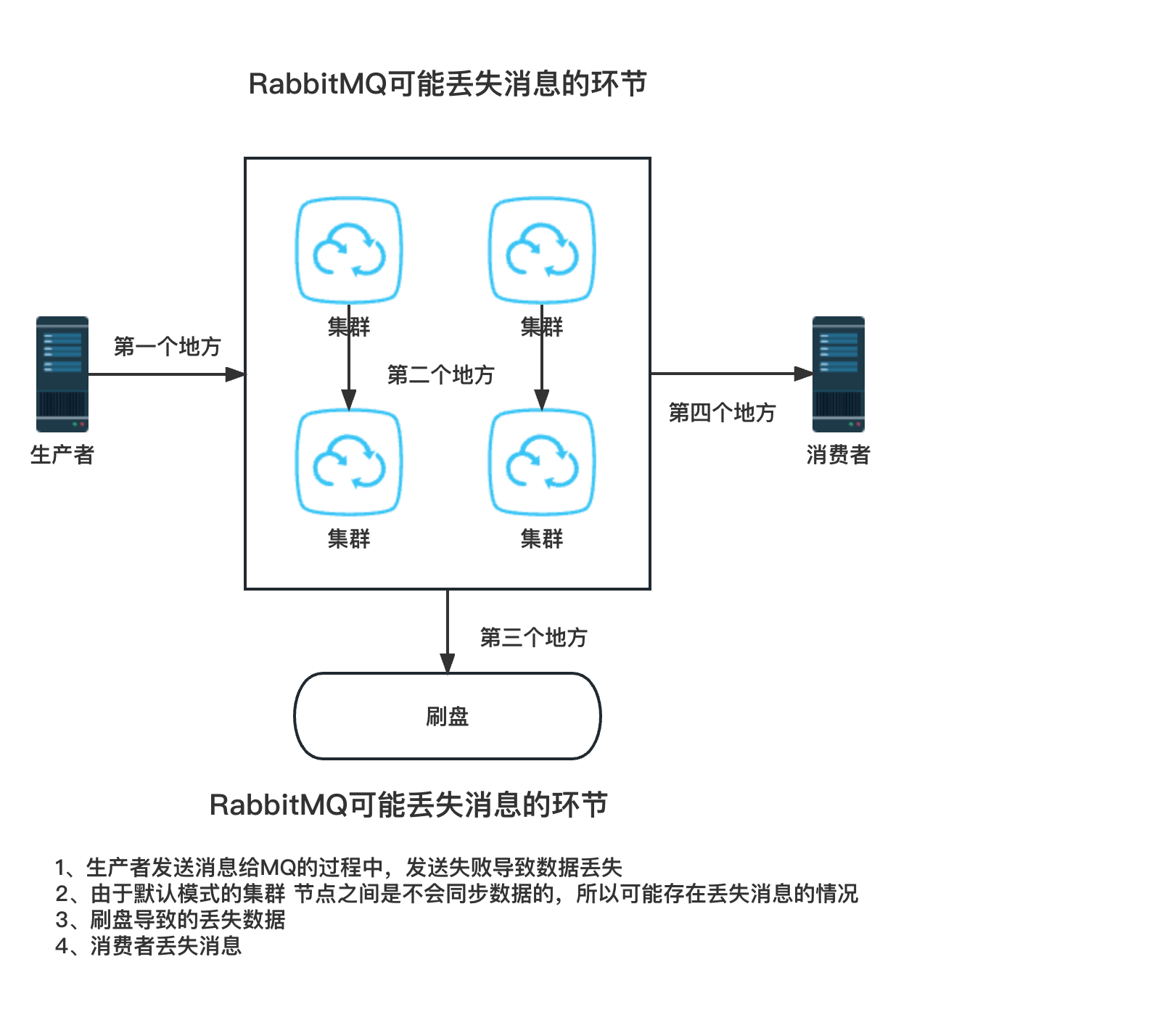
1.生产者发送消息
生产者在发送消息给MQ时,可能因为网络问题等情况,导致 消息发送失败,那么我们可以通过 生产者确认机制,来确保消息成功到达RabbitMQ。
生产者确认机制分为 同步确认和异步确认。
同步确认
同步确认主要是通过在生产者端使用Channel.waitForConfirmsOrDie()指定一个等待确认的完成时间。
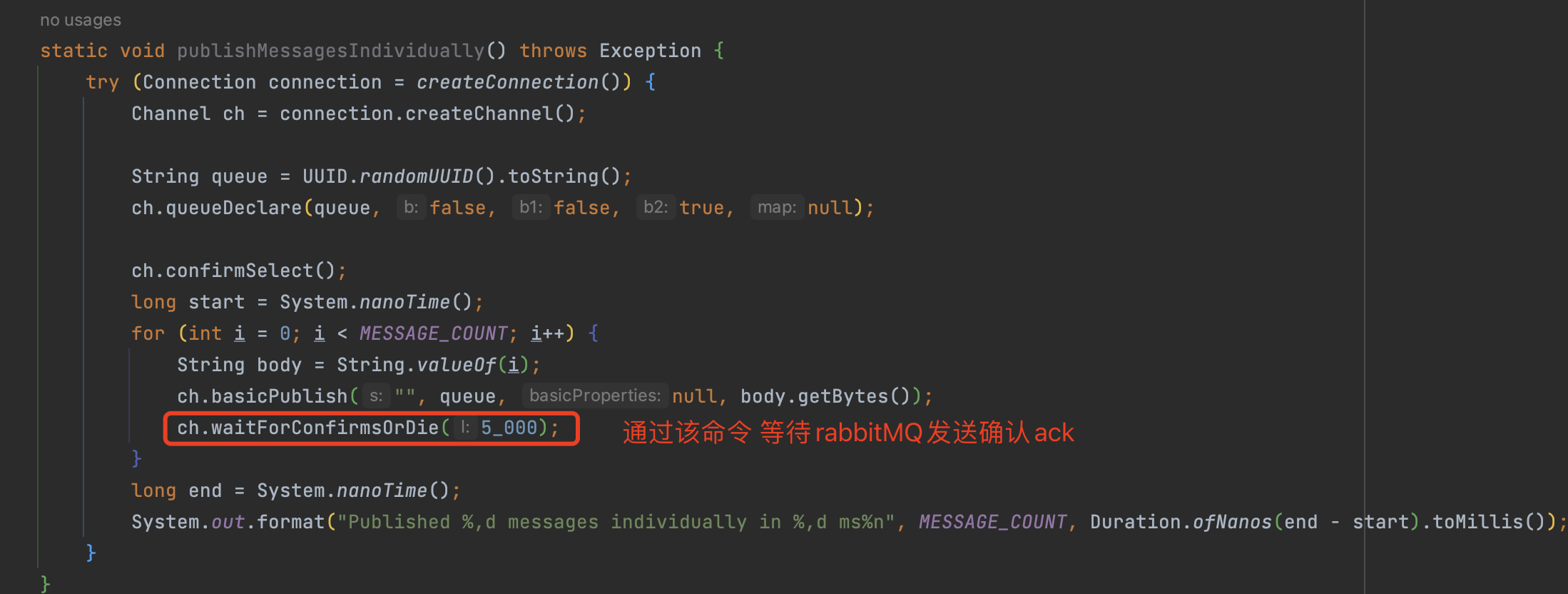
异步确认
异步确认机制则是通过channel.addConfirmListener(ConfirmCallback var1, ConfirmCallback var2)在生产者端注入两个回调确认函数。
channel.addConfirmListener(ConfirmCallback var1, ConfirmCallback var2);
这里注册了2个监听器,发送者在发送完消息后,就会执行第一个监听器callback1,然后等服务端发过来的反馈后,再执行第二个监听器callback2。
sequenceNumber的生成方式需要通过channel的序列获取。int sequenceNumber = channel.getNextPublishSeqNo();
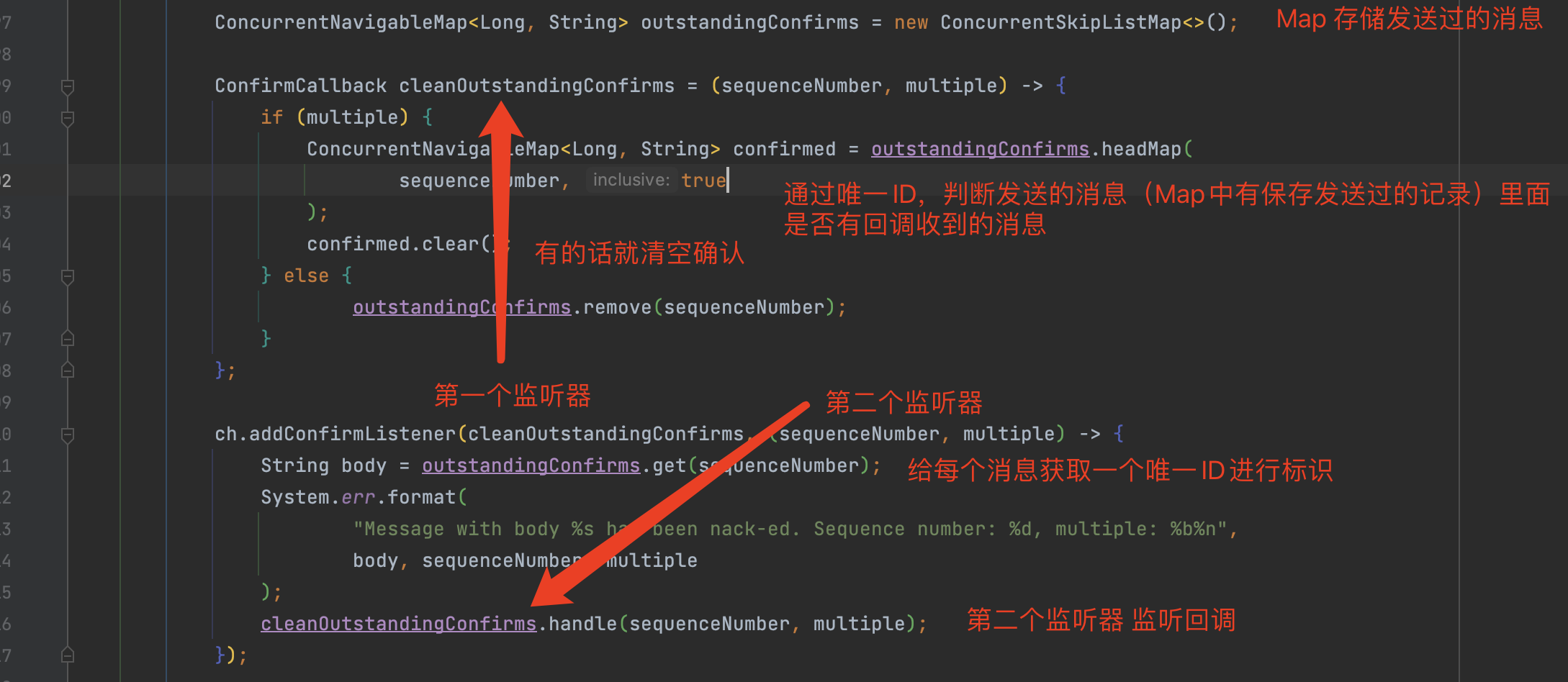
如果我们要在第二个监听器的回调方法里面做校验,确保消息是否发送成功,我们需要自行记录消息ID到Map中,并在回调函数中 进行匹配,如果发送失败则考虑 管理员警报还是补发。
2.集群节点丢失消息
因为默认的集群模式 ,消息只会存在各自的节点上,节点之间并不会主动进行消息同步,所以当节点宕机后,就会存在丢失消息的可能性。
为此,我们可以把模式改成 镜像模式,这样的话数据就会在每个节点之间同步,确保集群消息的可靠性。
3.刷盘(存盘)问题
当消息进入MQ后会先保存到内存的page cache缓存区,然后再由操作系统写入到硬盘中。但是如果在写入硬盘的过程中服务器宕机了,就会出现消息丢失的情况。
为了解决这个问题,Classic队列就一定要设置成持久化队列,这样消息会直接存入到硬盘,丢失消息的概率就不高。
4.消费者消费数据时丢失数据
消费者消费消息时,是可以指定 是否要自动应答还是 手动应答,我们可以给他切换成手动应答,如果业务逻辑处理失败了,则可以考虑是否要通知管理员,还是继续尝试,但是按照我的经验来看,如果第一次处理失败了,再次去处理也还是会失败。
所以我的建议是 做一个try cache ,如果业务处理处了问题,就通知管理员,并且把数据发送到其他的队列进行保存,但是依旧告知MQ处理成功,否则很可能会一直不停的处理失败,陷入死循环。
在生产环境中一旦陷入死循环,日志文件就会变得非常大,随后就导致服务器硬盘溢出,并且会阻塞线程,导致后续的消息无法被正常消费。
如何保证消息幂等性
1)为什么会产生消息幂等性问题
因为RabbitMQ有一个重试机制,如果消费者消费的过程中抛出异常,或者不向MQ返回响应,MQ就会进行无限次的重试,确保消息的可靠性。
但是正因为这个重试机制,导致可能出现多个消费者收到同样的消息。
举个例子:客户在下单后,服务器发送给了MQ一条订单信息,库存服务器(消费者)收到后,在处理的过程中抛了异常,但是没有进行数据回滚,库存已经减1了,而MQ没有收到正确响应就进行重试,库存服务器再次收到这条消息又进行库存操作,以此往复…
2)解决方案
1.设置重试次数
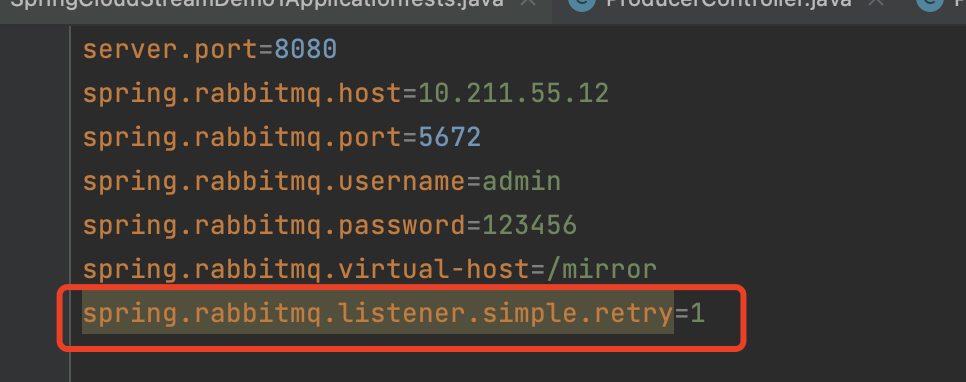
我们可以在SpringBoot集成rabbitMQ时,通过一条命令 设置RabbitMQ 重试次数,避免重试次数太多导致的幂等性问题。
1 | spring.rabbitmq.listener.simple.retry=1 |
2.设置消息唯一标识
在生产者发送消息时,在消息上面指定一个全局唯一的Message ID,消费者收到消息后判断该Message ID是否已经消费过,如果没有消费过的话就进行消费,消费成功后把Message ID存入到redis中,消费过的话就返回正确应答。
1 | /** |
消费者接收时,通过获取消息ID并在redis中查询
1 |
|
3.业务代码自行判断
在做业务操作之前我们需要先判断消息对应的状态,如订单支付状态,订单发货状态等。
例如:我们通过获取订单ID去数据库或缓存中查询是否已经成功支付,或做了某些相应操作,如果做了就不进行业务操作,但是返回正确响应,如果没有做就继续往下执行业务逻辑。
如何保证消息的顺序
在rabbitMQ中很难保证消息的顺序,如果要保证消息的顺序的话就会影响到MQ的吞吐量,这是一个取舍的问题。
只有先进先出的队列,并且缩小消费者消费次数,才可以保证 消息的顺序。
注意:这里的顺序指的并不是MQ所有队列消息的顺序,而是局部的有序。
举个例子:
客户下单后,服务器需要进行 计算优惠券、支付系统、库存、通知快递发货等操作,这种必须保证顺序有序,否则就会出现问题。
1)解决方案 - 单队列单消费模式
一组希望有序的消息,我们只发送到一个队列中,并且保证一个消费者进行消费,并且保证一次只读取一条消息。
因为队列先进先出的原则,可以确保消息在队列中百分百是有序的,但是消费者一次都是获取很多数据然后进行处理的,在消费者这段就会出现 乱序的情况,所以我们要确保只有一个消费者处理,并且消费者一次只能获取一条消息。
2)配置参数
1 | spring.rabbitmq.listener.simple.prefetch=1 |
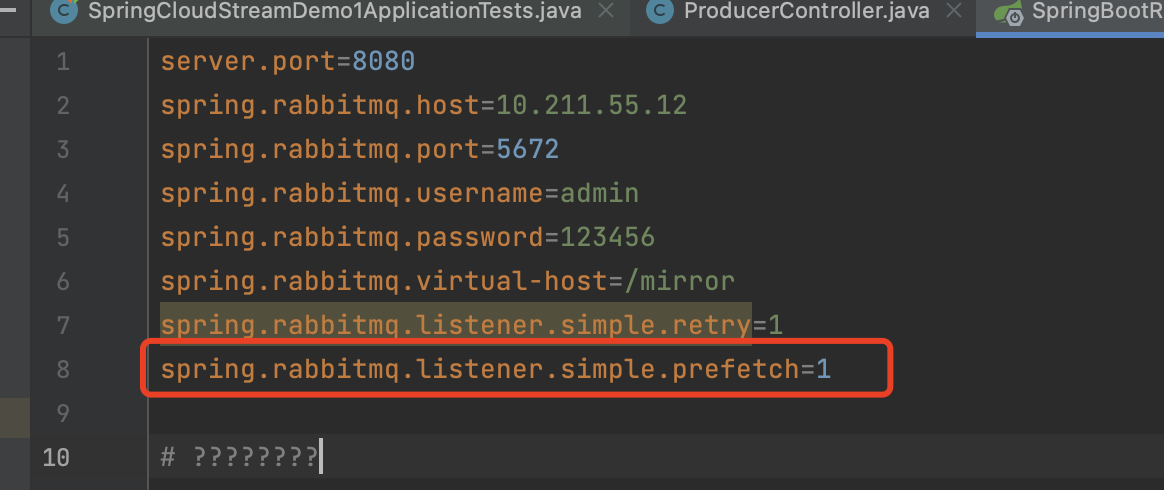
该参数主要作用是确保每次消费者只会获取一条消息进行消费
如何避免数据堆积
由于RabbitMQ消息大量堆积会导致性能下降,所以RabbitMQ新推出了Quorum和Stream队列来解决这个问题。
除此之外,我们也可以通过其他的手段来限制消息堆积,手段都是来自于消费者这边的优化,因为你很难去优化生产者,更不可能去限流。
1)消费者优化手段
1.设置单次消费数量和线程
对于单个消费者,我们可以提高单次消费数量以及消费现场,来提高消费者的处理并发能力。
1 | # 单次推送消息数量 |
2.增加消费者数量
当消费端的服务器出现了故障导致大量消息堆积的话,就要立即增加消费端服务器,来加速消费掉积压的消息。
RabbitMQ的备份与恢复
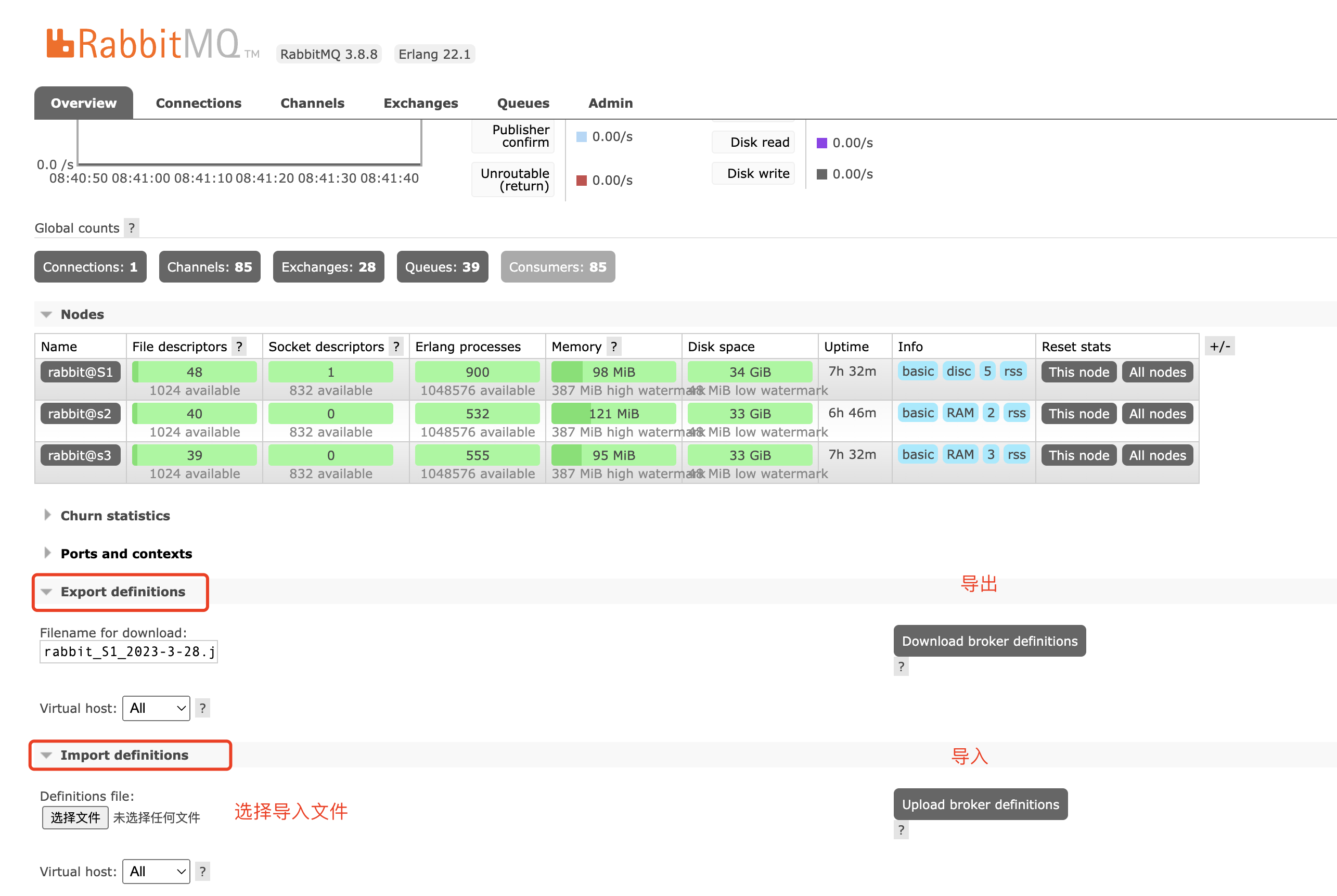
我们可以通过RabbitMQ web管理端自带的导入导出功能,来完成数据备份。
但是值得注意的是,这种方式 只能备份、恢复 元数据(队列、交换机、虚拟机等不包含具体消息)。
1)元数据备份恢复
2)消息数据备份和恢复
实际上并不建议来备份和恢复数据,会造成不可预料的后果,如 数据重复消费等问题。
备份
但是如果我们实在需要备份消息数据,可以通过 备份以下目录即可。
RabbitMQ有一个data目录会保存该节点的所有消息,目录地址:/var/lib/rabbitmq/mnesia
恢复
如果需要恢复的话,只需要将整个文件夹复制到新的服务中即可。





