RabbitMQ单机搭建和集群搭建
MQ介绍
MQ:MessageQueue,消息队列。 是一种FIFO 先进先出的数据结构。与之相反的栈 是先进后出的数据结构。
生产者发送消息到MQ队列中,消费者监听队列后取得消息并消费,消费成功后返回ack告知MQ队列。
1)MQ的作用
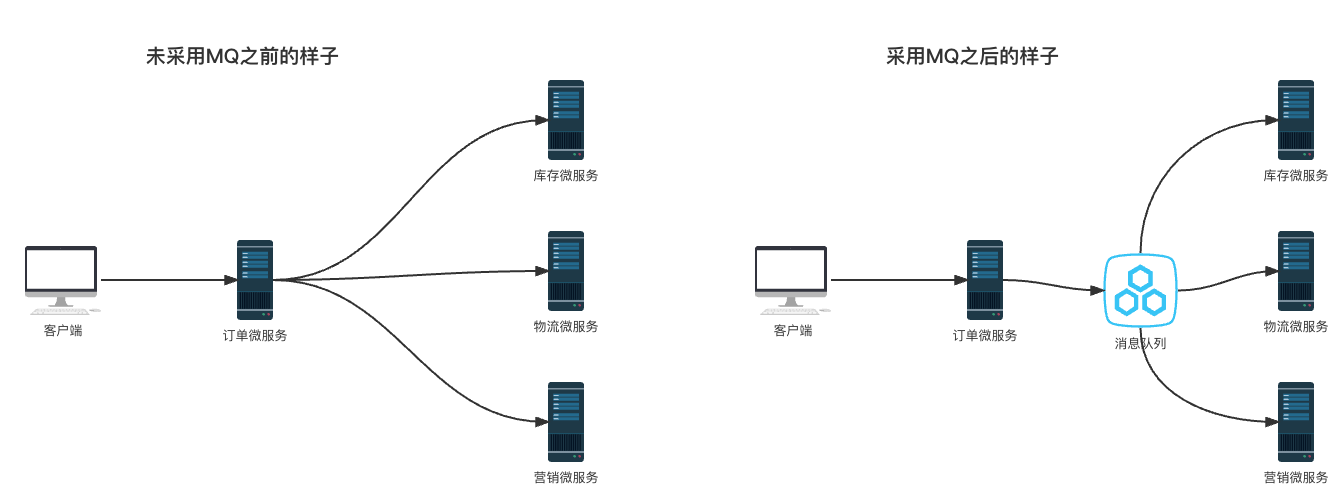
异步
- 未采用MQ
- 客户端下单后,订单服务需要发送open feign请求给库存微服务,并且得到响应后继续发送给物流微服务,以此类推。
- 采用MQ
- 客户端下单后,订单服务直接发送消息到MQ队列中就可以直接返回给客户端了,不需要在去执行下面的步骤,而监听MQ队列的微服务 获取到消息后就会开始消费并执行相应处理逻辑。
解耦
- 服务之间进行解耦,才可以减少服务之间的影响,提高系统整体的稳定性以及可扩展性。
- 由于消息队列中的消息可以由一个或者多个消费者进行消费,消费者的增加或者减少对生产者没有影响。
- 高内聚低耦合
- 高内聚:依赖的外部服务越少,说明内聚程度越高
- 低耦合:两个相关的服务尽可能的降低互相依赖
削峰
- 流量并发特别大时,服务端会因为巨大的流量扛不住而宕机。为此我们可以在服务端上层引入MQ进行削峰填谷,由于消息队列是单线程模型,所有请求进入队列中都会按照 先进先出原则执行,一定程度上的削减了流量,减少了服务端的压力。
三大MQ主流对比
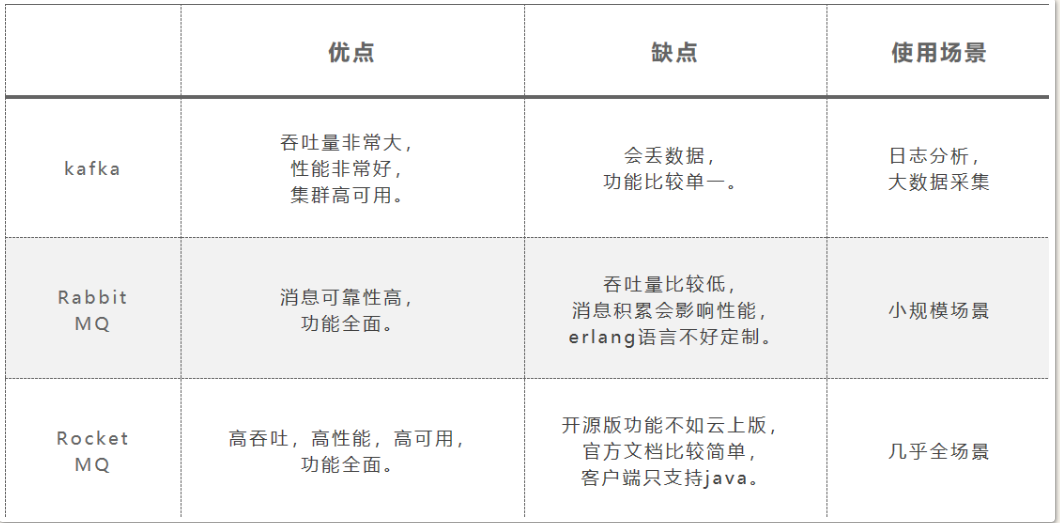
2)MQ的优缺点
系统可用性降低
- 随着引入的外部组件越多,系统的可靠性就越低,如果MQ宕机了,那么整个链路上的服务都会陷入瘫痪。
- 对于生产环境而言,就得考虑MQ的高可用性,避免MQ的宕机造成整个业务的瘫痪
- 随着引入的外部组件越多,系统的可靠性就越低,如果MQ宕机了,那么整个链路上的服务都会陷入瘫痪。
系统复杂度提高
- 引入MQ后系统会变得更复杂,服务之间的请求会从同步变成异步,对于订单服务而言,他只知道把请求发给了MQ,而MQ后续的操作,订单服务是无法追踪的,这也会带来一系列的问题
- 如何保证消费不会丢失?不会被重复调用?怎么保证消息的顺序性等问题
- 引入MQ后系统会变得更复杂,服务之间的请求会从同步变成异步,对于订单服务而言,他只知道把请求发给了MQ,而MQ后续的操作,订单服务是无法追踪的,这也会带来一系列的问题
消息一致性问题
- 订单服务发送消息给MQ,库存服务消费后返回ack,但是 物流服务消费的过程中出了异常,就会导致 多个服务之间的消息不一致。
RabbitMQ单机搭建
1)Linux版本
源码、安装包:
erlang:23.2 下载地址:https://files.javaxing.com/rabbitmq/erlang-23.2.7-1.el7.x86_64.rpm
rabbitMQ:3.9.15 下载地址:https://files.javaxing.com/rabbitmq/rabbitmq-server-3.9.15-1.el7.noarch.rpm
1.安装erlang
依赖环境:
1 | // 下载erlang |
2.安装RabbitMQ
下载安装包
1 | [root ~]# wget https://files.javaxing.com/rabbitmq/rabbitmq-server-3.9.15-1.el7.noarch.rpm |
安装rabbitMQ
1 | [root ~]# rpm -Uvh rabbitmq-server-3.9.15-1.el7.noarch.rpm |
启动RabbitMQ WebManage插件
1 | // 后台启动RabbitMQ服务 |
添加远程登录账号
1 | // 添加用户 admin 密码为 123456 |
开放端口
注意:可以选择关闭防火墙或开放RabbitMQ服务端口。
1 | // 15672 web管理端端口,5672 client端通信端口,4369 erlang发现端口,25672 server间内部通信口 |
登录rabbitMQ
访问地址: http://localhost:15672 ,使用 admin 密码 123456 进行登录
3.RabbitMQ维护命令
启动和停止
1 | // 后台启动 |
查看服务状态
1 | [root ~]#rabbitmqctl status |
2)Linux - ARM架构
源码、安装包:
erlang:22.0 下载地址:https://files.javaxing.com/otp_src_22.1.tar.gz
rabbitMQ:3.8.8 下载地址:https://files.javaxing.com/rabbitmq-server-generic-unix-3.8.8.tar.xz
注意:ARM架构的MQ安装包和的Linux X86架构不太一样,别弄错了
1.安装erlang
依赖环境:
1 | [root ~]#yum install ncurses ncurses-devel java-devel -y |
解压目录并编译:
1 | [root ~]#tar -zxf otp_src_22.1.tar.gz |
配置环境变量:
1 | [root otp_src_22.1]# vim /etc/profile |
2.安装RabbitMQ
下载安装包
1 | [root ~]#wget https://files.javaxing.com/rabbitmq-server-generic-unix-3.8.8.tar.xz |
解压并设置环境变量
1 | // 解压文件 |
启动RabbitMQ WebManage插件
1 | // 启动web管理插件 |
添加远程登录账号
1 | // 添加用户 admin 密码为 123456 |
开放端口
注意:可以选择关闭防火墙或开放RabbitMQ服务端口。
1 | // 15672 web管理端端口,5672 client端通信端口,4369 erlang发现端口,25672 server间内部通信口 |
登录rabbitMQ
访问地址: http://localhost:15672 ,使用 admin 密码 123456 进行登录

3.RabbitMQ维护命令
启动和停止
1 | // 后台启动 |
查看服务状态
1 | [root ~]#rabbitmqctl status |


列出/启动插件
1 | // 列出插件列表 |
RabbitMQ集群搭建
1)实验环境
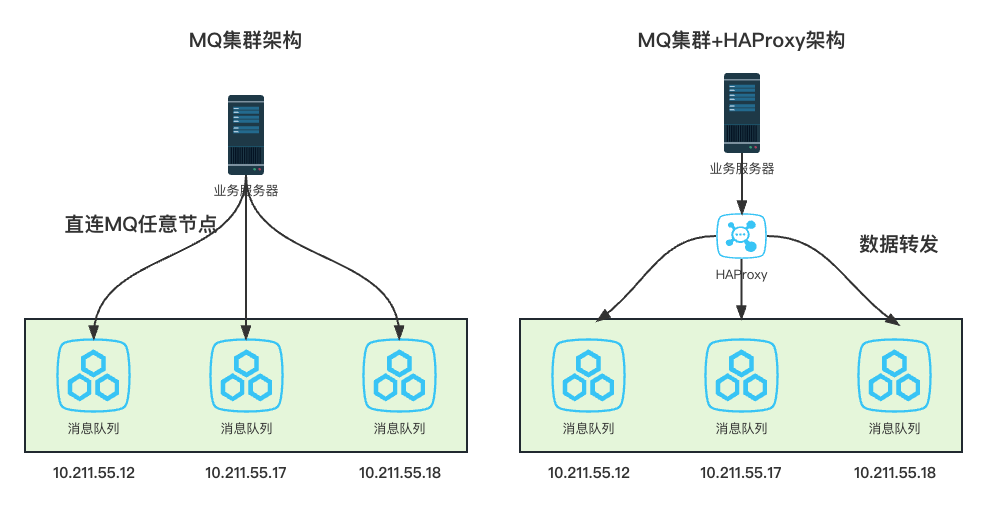
集群架构也分很多种,这里我们介绍其中比较常见的两种:
左边的架构由服务端连接MQ中的任意节点,而MQ的节点都可以提供服务
右边的架构多了一个HAProxy(负载均衡器),起到了消息分发和负载均衡的功能
- 服务端发送消息给HAProxy,HAProxy根据负载均衡策略转发到相应的MQ中
HAProxy并不能保证集群高可用,只是起到了消息分发和负载均衡的作用,为了确保集群高可用,通常集群会配合Keepalived组件来保证服务高可用。
Keepalived:
- keepalived保证每个RabbitMQ的稳定性,当某一个节点上的RabbitMQ服务崩溃时,可以及时重新启动起来。
实验设备
这里我们准备了3台虚拟机,分别为10.211.55.12、17、18,并且关闭防火墙(或者开放RabbitMQ端口:5672(amqp端口)、15672(http Api端口)、25672(集群通信端口))。
2)集群模式
在RabbitMQ中的集群有两种数据模式:
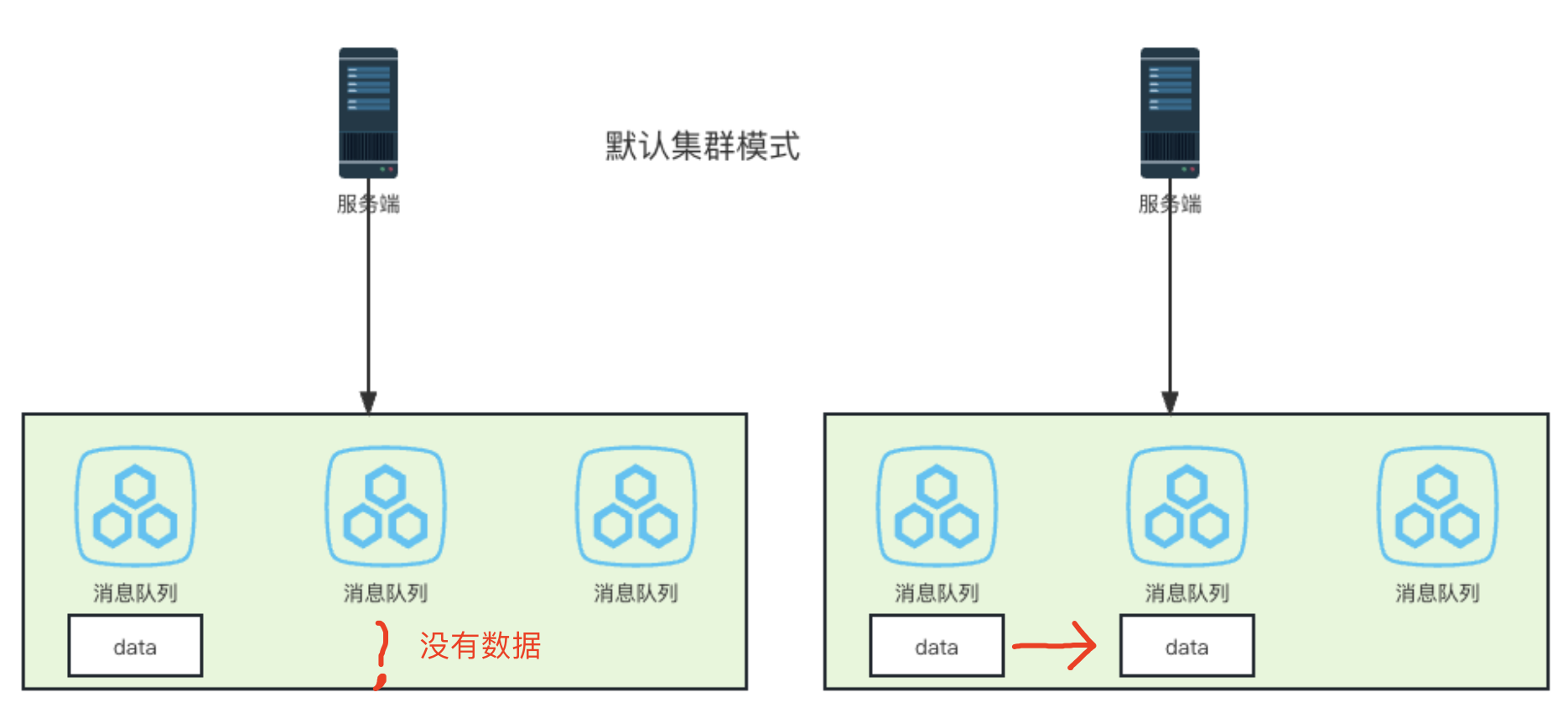
集群各个节点之间只会同步队列结构、交换机等(元数据),消息只会存储在各自节点,不会同步消息。
由于消息只会存储在各自节点,节点之间并不会同步,当消费者开始消费数据时,集群中的某个节点收到消费请求后,该节点如果没有消息数据,就会去找集群中其他有数据的节点,同步一份返回给消费者。
缺点:
集群可靠性很差,如果存储数据的节点宕机了,而因为节点只会存储各自的消息,宕机节点的消息就无法对外提供消费服务
节点宕机期间,消费者无法正确的给ACK确认,导致 节点恢复后可能出现 消息重复消费的情况
如果没有做持久化(disk),重启后节点上的消息会丢失
镜像模式
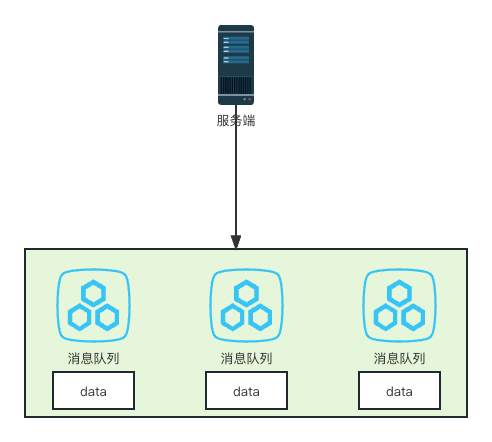
该模式是对普通模式的一种增强,在普通模式的基础之上的高可用方案,它会在所有集群节点之间主动进行消息同步。
优点:可靠性高,每个集群节点都有全量消息,不存在丢失消息的情况
缺点:集群节点进行同步会大量的消耗网络带宽,进而降低整个集群的性能
3)搭建普通集群
1.同步集群中所有节点的cookie
erlang.cookie是erlang实现集群必要的文件,每个节点上.erlang.cookie必须保证相同。
如何找到.erlang.cookie文件?
.erlang.cookie一般会存在这两个地址:第一个是$home/.erlang.cookie;第二个地方就是/var/lib/rabbitmq/.erlang.cookie
- 如果我们使用解压缩方式安装部署的rabbitmq,那么这个文件会在
${home}目录下,也就是$home/.erlang.cookie,也就是/root/.erlang.cookie。 - 如果我们使用rpm等安装包方式进行安装的,那么这个文件会在/var/lib/rabbitmq目录下。
我们需要通过命令,确保集群上所有节点的文件都一致,可以通过下面的命令实现:
1 | // 通过scp命令,把S1的文件同步到 S2、S3 |
2.加入到S1的集群
S2要加入S1集群的话,要先确保S2当前节点RabbitMQ处于正常运行状态,才可以执行下面的加入集群操作。
查看RabbitMQ是否正常运行
1 | [root ~]# rabbitmqctl status |

如果出现上图所示,我们需要先启动RabbitMQ,启动命令:rabbitmq-server -detached,启动后,我们在执行 以下命令。
停止RabbitMQ
1 | [root ~]# rabbitmqctl stop_app |
设置hosts
我们需要为本机设置hosts映射,如:10.211.55.12 S1 ,这样我们下面在加入集群的时候,才可以直接通过指向S1,rabbitMQ服务端会直接找到10.211.55.12这台服务器,这很重要。
1 | [root@s2 ~]# vim /etc/hosts |
连通性测试
想要加入集群的机器,我们先ping 一下,看是否能正常连通 集群中的机器,如果不能连通就要检查网络配置和防火墙。
1 | [root ~]# ping S1 |
加入集群
1 | // --ram 表示以Ram模式加入集群,rabbit@ 是固定格式 S1是要加入的集群中master主节点 |
disc节点会将元数据保存到硬盘当中,持久化保存,重启数据依然存在
ram节点只是在内存中保存元数据,非持久化,重启后数据就会丢失
元数据:仅只包含交换机、队列等,而不包含具体的消息。因此,ram节点的性能提升,仅仅体现在对元数据进行管理时,比如修改队列queue,交换机exchange,虚拟机vhosts等时,与消息的生产和消费速度无关。
风险注意
如果一个集群中,全部都是ram节点,那么元数据就有可能丢失,所以集群中至少保证一个disk节点。实际上,官方并不推荐集群中使用RAM节点,为了确保高可用性,建议节点都使用disk模式。
3.启动节点
刚加入集群后,如果没有启动rabbitMQ,在S1的管理后台可以看到 新的节点是没有运行的。
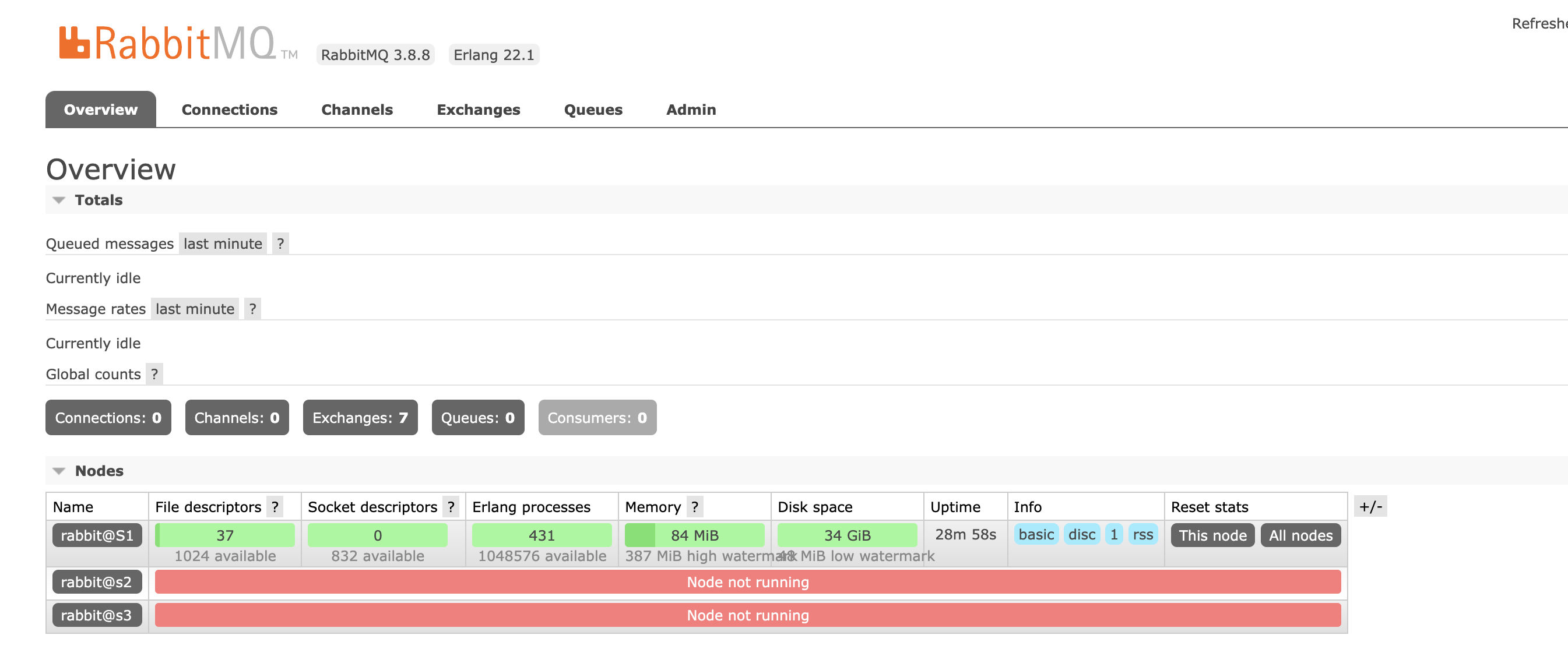
启动节点
1 | [root ~]# rabbitmqctl start_app |
查询启动后的状态
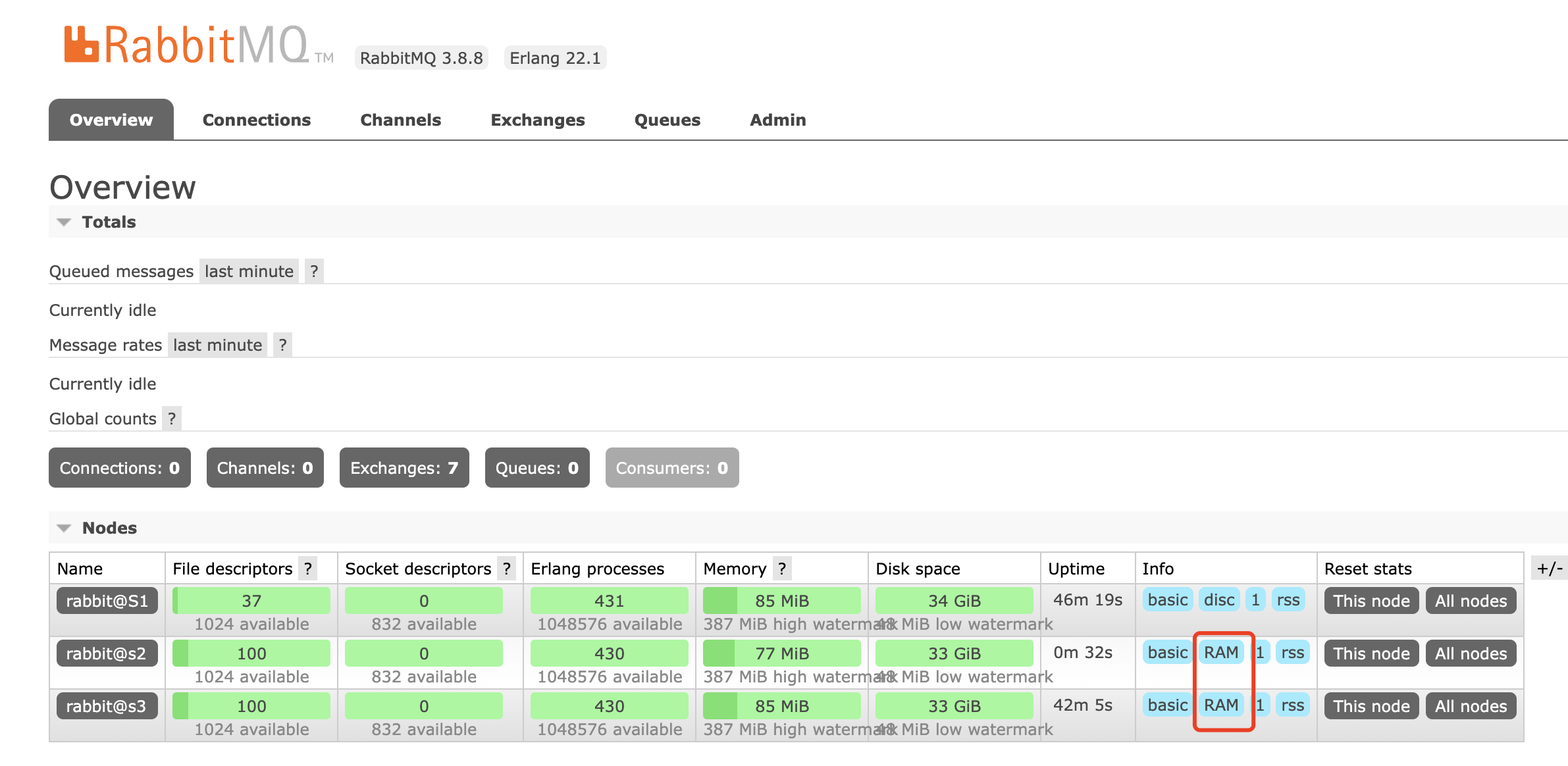
4.查看集群状态
1 | [root ~]# rabbitmqctl cluster_status |

4)搭建镜像集群
镜像集群是在建立在普通集群模式之上的,所以要先搭建好普通集群后,我们在通过命令修改成 镜像集群。
为了减少RabbitMQ集群中之前的数据传输,我们镜像集群一般都会建立在固定的virtual host(虚拟主机)上,而并非直接建立到根节点虚拟主机,这样只会在固定的虚拟主机下的集群节点进行数据同步。
1.创建virtual host 虚拟主机
1 | [root ~]# rabbitmqctl add_vhost /mirror |
虚拟主机起到了一个逻辑隔离的作用,不同的虚拟主机之间的节点、元数据、消息 都互不干涉。
2.设置镜像策略
- 在集群中master节点(S1)上执行 镜像策略命令,其他的节点会自动取同步该节点的元数据
1 | // 设置镜像策略 |
HA mode:可选值 all , exactly, nodes。生产环境通常为了保证高可用都会选 all
pattern是队列的匹配规则, ^表示全部匹配,如果^ha 开头,则代表匹配ha开头的队列,一般情况下如果用虚拟主机隔离开后,就很少在执行匹配规则了。
在Web管理端也是可以创建镜像策略的,并且在管理端可以清晰的看到镜像策略参数:
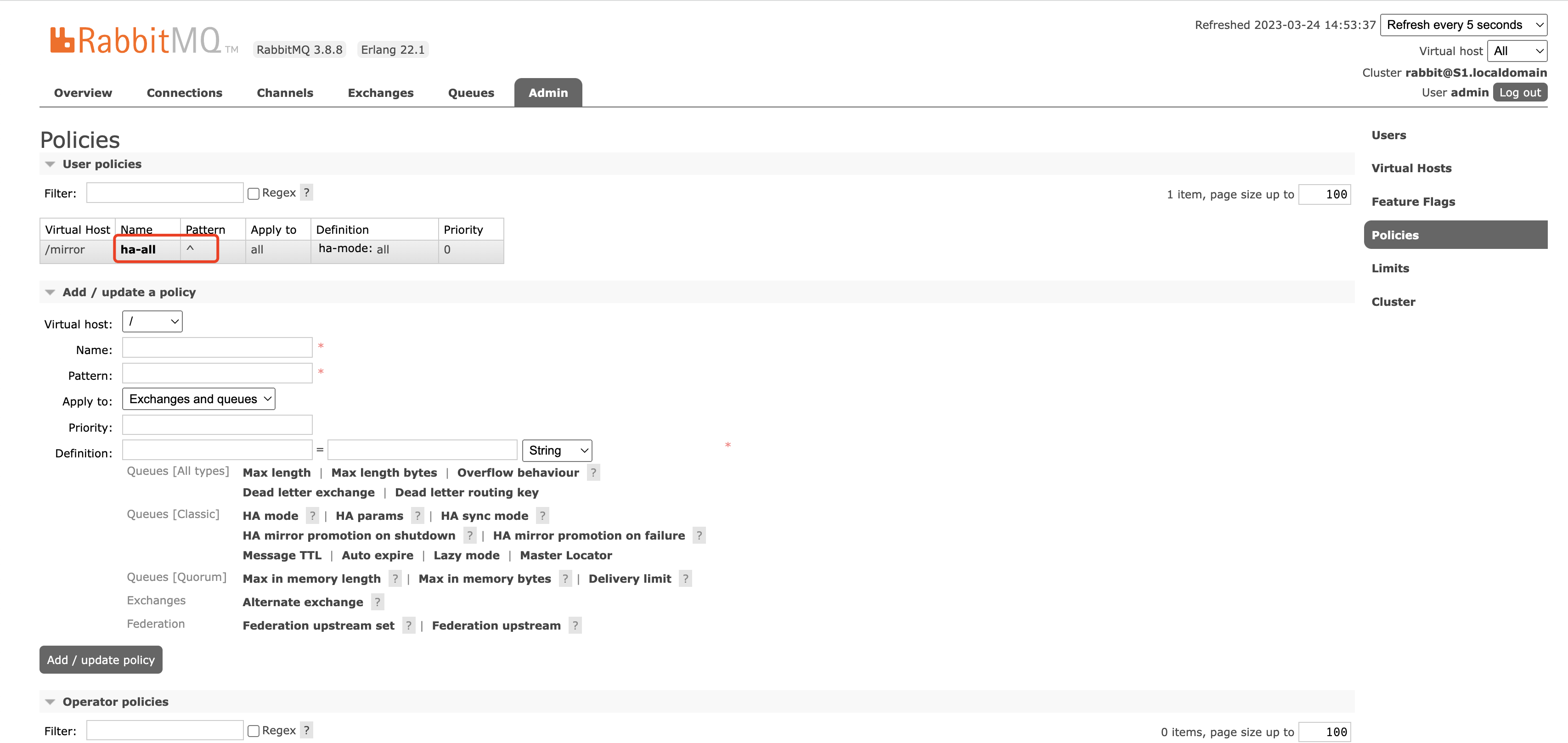
使用镜像模式的注意事项
1、由于镜像模式很消耗服务器资源,所以需要预留一些服务器资源 如 内存、硬盘空间
2、RabbitMQ中的队列不要创建太多,并且不要堆积大量的消息,避免占用过多的资源,导致服务器内存溢出
5)删除集群节点
如果想要在集群中把某个节点删除,可以通过以下2种方式。
1.从集群中踢出某节点
1 | 在需要退出集群的节点上,停止rabbitMQ服务 |
forget_cluster_node:从集群中踢出该节点并告知其他集群节点
加上
-offline参数,它允许节点在自身没有启动的情况下将其他节点剔除。
2.主动退出集群
1 | 在需要退出集群的节点上,停止rabbitMQ服务 |
rabbitmqctl reset:清空该节点上所有历史数据,并主动通知集群中其它节点它将要离开集群。
6)集群重启和关闭
没有一个直接的命令可以关闭整个集群,需要逐一进行关闭。但是需要保证在重启时,最后关闭的节点最先被启动。如果第一个启动的不是最后关闭的节点,那么这个节点会等待最后关闭的那个节点启动,默认进行 10 次连接尝试,超时时间为 30 秒,如果依然没有等到,则该节点启动失败。





