MySQL数据库高性能建库原则
高性能建库原则
范式
范式(NF):MySQL是关系型数据库,想设计—个好的关系,必须满足一定的约束条件。
目前关系数据库有六种范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、 巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF,又称完美范式),我们需要重点关注的 只有 第一第二第三范式,其他可以不管,约束过于苛刻,开发用不到。
第一范式
定义:属于第一范式关系的所有属性不可在分裂。
优化前:
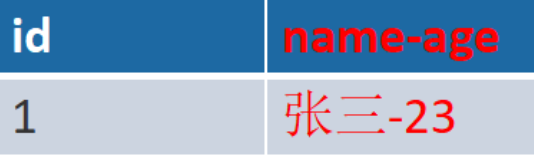
name-age 1个列具有2个属性,一个name,一个age,这样是不满足第一范式的,所以要给他拆分成 2个列。
优化后:

仅仅通过第一范式来约束数据库关系是不够的,所以需要引入 第二范式。
第二范式
定义:需要为表加上一列,作为唯一标识,这一列 称为 主键。
例:员工信息表,加上一列 employee_id ,因为员工编号是唯一的,因此可以被唯一区分。
注意:联合主键中属于部分主键的列,应该拆分出去形成以部分主键为主键的表。
第三范式
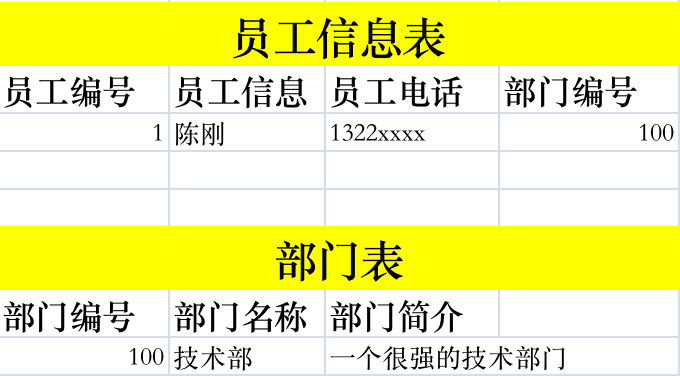
案例1:

如图所示,如果在员工表上,加了 部门编号这一列,则不可以在后面再加上 部门名称和部门简介。
优化方案:
- 应当拆分成 2个表,一个员工表,一个部门信息表,在通过 部门编号进行关联。
案例2:
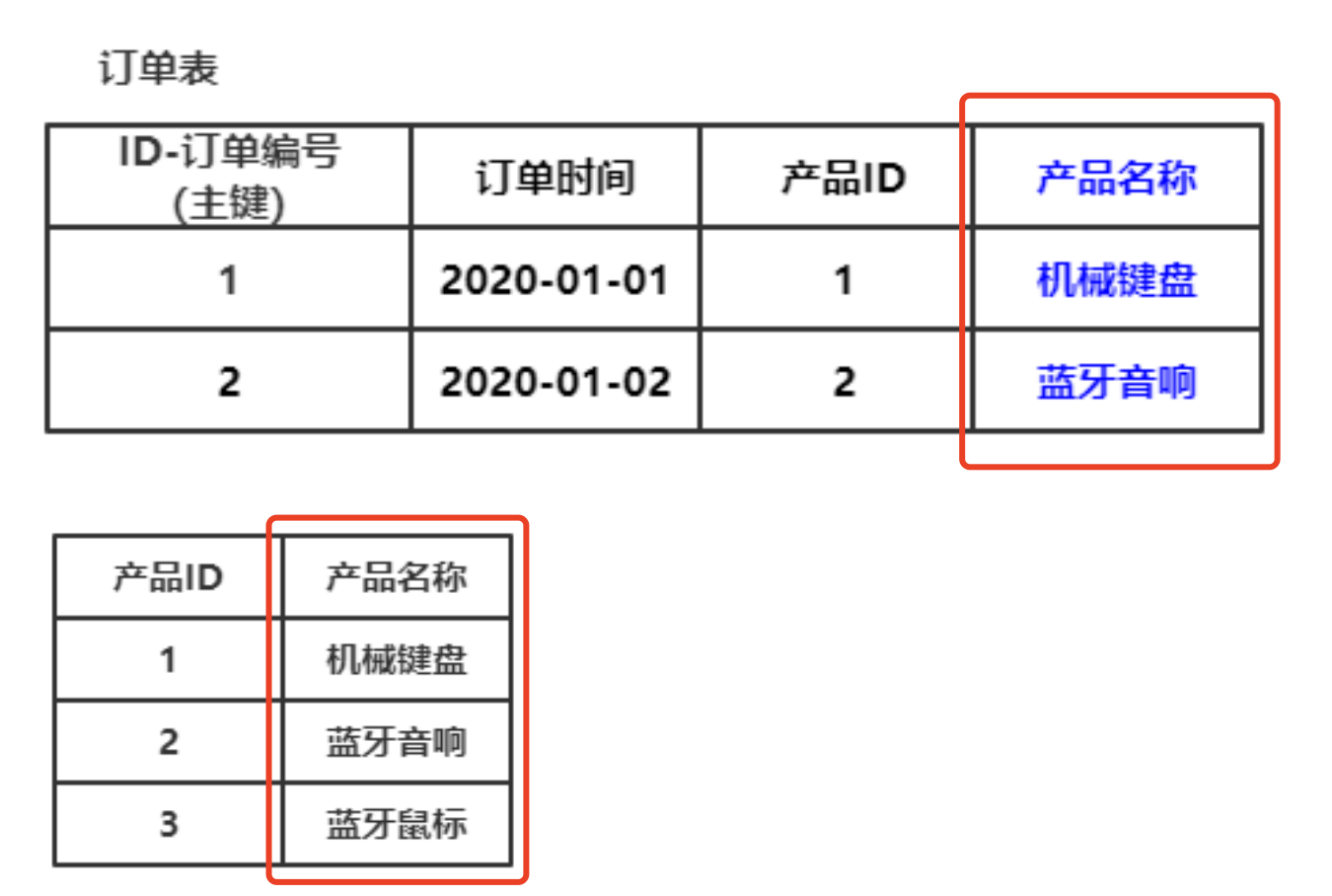
如图所示,订单表 与 产品ID表关联,订单表与 产品名称关联,产品名称与产品ID关联。
此时订单表如果订单ID发生了改变,订单表内的产品名称也要相应改变,否则数据就会不一致,这种是不符合第三范式。
反范式化设计
完全符合范式化的设计并非完美,在实际业务查询中 会大量存在 关联表查询,而关联的表越多 就越影响性能。
符合第三范式:

3张表,1张商品信息表,1张分类信息表,1张 商品和分类对应关系表。
反范式化:

查询商品信息时,会经常查询分类名称,所以这里我们就增加 分类名称做冗余字段,存于 商品信息表。
范式化和反范式化设计优缺点
范式化优点
范式化设计的数据库 更新数据方便,如下图,如果我们需要修改 分类名称,只需要在 分类信息表修改即可。如果是反范式化设计,除了要更新分类信息表,还需要更新 商品信息表冗余字段的内容,更新信息需要更多成本。

范式化缺点:
- 范式化设计 通常很需要进行关联表查询,如果数据量较大,关联表查询的效率是非常低的。
反范式化优点
- 良好的反范式化设计可以减少 表关联,提高查询效率。
反范式化缺点
- 更新数据时,同时也要更新冗余字段数据,更新信息需要更多成本,很难保证数据一致性。
总结
- 尽可能的满足 范式化约束 来设计表结构。
- 当范式化约束影响到了 数据库性能,就使用 反范式化设计。
实际开发中反范式化
应当根据实际情况,酌情考虑 如何进行反范式化,而不是完全遵循 第三范式,也不是一股脑的瞎折腾反范式化。
本来就没有 谁对谁错,只是权衡利弊罢了。
反范式化最常见的就是 冗余字段和缓存,在不同的表中存储相同的列(冗余字段)。
计数器优化
常规做法
如果需要统计 每个帖子多少个收藏,我们可以使用select count(1), 来查询,但是如果数据表的数据量很大时,即便select count(1),查询起来也是比较耗费时间的。
因此我们可以用一张表来存储计数器,一个帖子被收藏,则计数器加1 (或在帖子表新建一个 收藏字段)。
高性能做法
计数器在互联网应用中很常见,如 点赞,收藏,下载次数等。对于高并发的场景,我们可以创建一张 表来存储计数器。
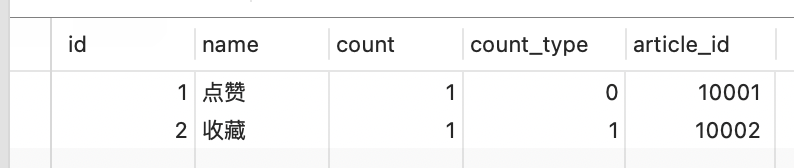
count_type: 0 点赞,1 收藏 , 2 打赏
article_id:帖子(文章)ID
count:计时器
互斥锁导致的性能问题:
在高并发的请求下,大量的事务请求去写入 ID为1的计数器,由于 MySQL存在 全局互斥锁(mutex),导致这些事务只能串行执行,非常影响系统并发能力。
串行:一次只能执行一个事务,需要等待上一个事务执行结束后 解开互斥锁,下一个事务才能执行。
解决方案:写热点分散
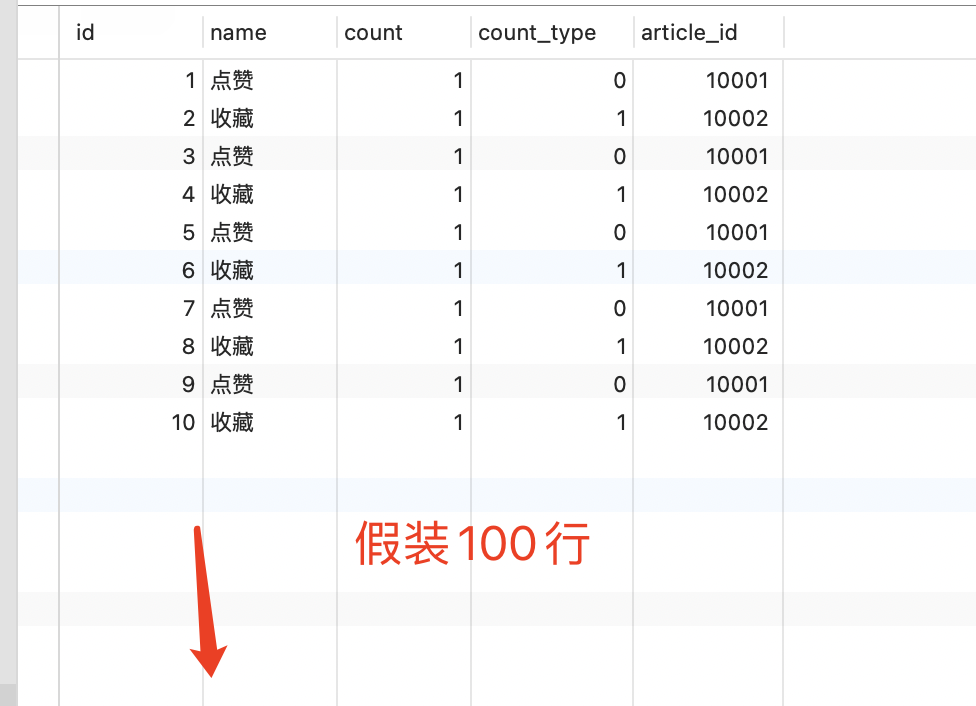
我们可以将计时器保存成多行(假设先创建出100行)的形式,通过count_type来区分 计时器的类型,每次都按 文章ID和计时器类型(count_type)随机更新计数器(count)。
此时我们需要 统计某文章的点赞的总次数时,只需要 根据文章ID和类型(count_type)为0 查询,求出count 字段的总和,就可以统计出来了。
数据库建表原则
- 数据库名称(长度不可超过30个字符)、表名、字段名 见名知义
- 字段名要根据业务起,要做到见名知义,不要乱起 更不要中文、拼音
- 数据库的列要控制好,字段数建议在20个内,要符合《数据库设计第三范式》
- 适当进行表字段的冗余,可以减少表之间的join,提高查询效率(以空间换时间)
- 设计表字段时,合理分配数值类型,合适的字段类型可节约空间
- 一个表 最好是在2-7个索引,索引越多意味着 维护的索引树就越多,会在一定程度上影响查询效率
- 慎用text类型
- 为提升查询效率,尽量使用varchar字段代替text字段
- innodb模式的MySQL 推荐使用整型的自增主键
- 为什么推荐 整型
- 【效率问题】当MySQL从根节点开始查找数据时,索引是整型的明显比字符串(UUID等其他)比较的速度更快,效率更高
- 【空间问题】数据库的硬盘空间非常宝贵且硬盘价格昂贵,索引占用越小,越能节约磁盘空间,一页可以存放的索引越多。
- 为什么推荐 自增主键
- 区间访问速度、查找速度更快
- 叶子节点除了索引和磁盘地址外,还存放了一个左右两边 节点的地址,方便我们快速找到他相邻的节点。
- 如果我们是自增主键,那么叶子节点的索引则是有顺序,从小到大的排序。那么我们在进行范围查找,如:a > 20 and a < 50 ,我们找到了20的节点后,可以根据 他指向右边附近结点的地址,快速地定位到第三个节点(49,50)

- 避免索引移位
- 因为插入的时候是按顺序插入的,如果不是自增主键,插入其他类型的主键,很可能造成已有的索引进行移位,效率降低。
- 区间访问速度、查找速度更快
- 为什么推荐 整型
- 在MySQL中,对于不同的字段选择正确的数据类型 尤为重要,合理的选择数据类型,可以提升MySQL的执行效率。
- 根据业务需求,合理并正确的选择列对应的数据类型,如:开关状态,能用TINYINT则不用INT。
- 好处
- 提升查询速度,类型占用越小,相对的在索引树的查询就越快
- 数据类型越小,占用的存储空间越少,一个叶子节点能存放的索引就更多
单机架构瓶颈
- 如果硬件和IOS系统一旦确定,单机MySQL就一定会存在性能上限
- IOPS
- 每秒处理 I/O 的请求次数,一般:每秒支持 读2000次,写600Q次
- QPS
- 每秒请求、查询次数,一般:每秒支持 3500-4500QPS
- TPS
- 每秒事务产生(增删改),一般:每秒支持 261次
- 我们只能在该上限之下进行一定的优化(SQL、索引),争取达到最大上限
- IOPS
- 可通过 系统架构 进行优化,提升MySQL的性能,不在受制于 单机MySQL性能限制
- 如 读写分类,主从复制,分库分表等
单节点(服务器、数据库)的架构,无论如何调优,机器的瓶颈始终在这摆着,不可能达到百万并发的需求,因为单机MySQL最多也只能承载3500-4500QPS。
最底层的一个逻辑,所有的性能问题归根结底都是解决IO的读写性能问题,从一开始的BIO到NIO,从reactor到proactor,这些模板本质上都是不断对IO性能的优化。
那么如果MySQL的并发上来后,MySQL就会触发警报,此时我们应该如何抉择:
- 读IO:把频繁访问的热门数据存放到内存数据库(逻辑io,数据库有:redis、memcached等 ),在高并发场景下访问该数据时候走redis,这样减轻了数据库的负担。
- 写IO:我们可以在MySQL写入之前先把数据传递给MQ(消息队列),然后通过队列依次写入数据,减轻了数据库的一个写压力
对于此时的架构而言,如果体量上来了,不论是redis还是MQ还是MySQL,我们都可以通过集群的形式横向扩展我们的设备,提高系统的QPS吞吐量,这样我们就可以解决并发带来的问题,达到百万千万并发都是可以的。
[image-1]: https://image.javaxing.com/document/image-20230113194152318.png




