Redis高并发分布式锁实战及源码分析
重现高并发下库存超卖
1、单机架构库存超卖
Pom.xml
1 | <dependency> |
Controller:
1 | @RestController |
这是一个库存扣减的Demo,每次访问接口时会从redis中取出库存数量,如果库存大于0 则库存减1,否则就提示库存不足,如果是在单机节点中,这个接口如果出现高并发访问,就会出现超卖问题。
模拟高并发
使用JMeter创建线程组进行压测
先创建线程组,线程数300,在创建HTTP请求,然后添加聚合报告,这里不多描述,有兴趣可以去看我另外一个文章《JMeter压力测试》
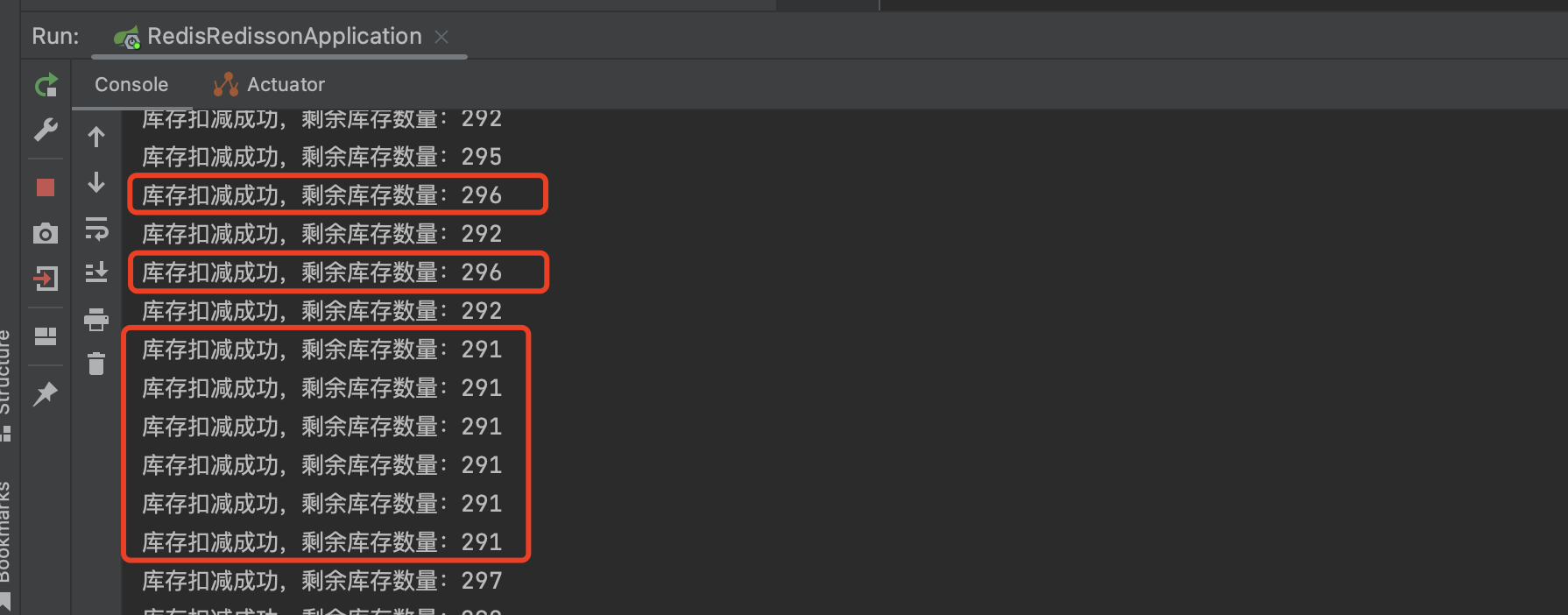
我们上面模拟了300个并发请求同时访问,发现代码马上就出问题了。

出现了超卖现象,库存被减了好多次,第一个请求还没处理完,第二个第三个…请求就进来了,导致获取到的库存数量是不正确的,并且其他请求也操作库存数。
并发产生的问题:
1、因为有300个并发请求同时访问,拿到的stock可能都是一样的,但是多个请求set redis时 却是299,可是库存的事务都会减1。
2、A接口获取到的库存是280,set redis时 是279,但是当A接口set成功后,B接口可能set 275,redis最终数据会错乱。
…. 并发产生的问题很多,这里不细说,总之得解决 并发产生的超卖现象。
解决方案:同步锁
1 | /** |
为代码加上同步锁(synchronized)就可以解决超卖问题,但是该方案进对于单机架构有效果,如果是集群或分布式,一样会出现问题。
2、集群架构库存超卖
如果是分布式架构或集群架构,在代码块上加了同步锁也无法解决超卖现象,因为同步锁只针对单机起作用,集群的其他机器不受约束。
模拟高并发
此时我们启动了2个服务点,端口为:8080、8081 ,并且通过nginx网关 做了负载均衡。
Nginx.conf:
1 | upstream tomcats{ |
此时,我们可以通过nginx进行访问,并通过负载均衡 同时请求到2台服务器。这里我们开始做压测。
压测结果:
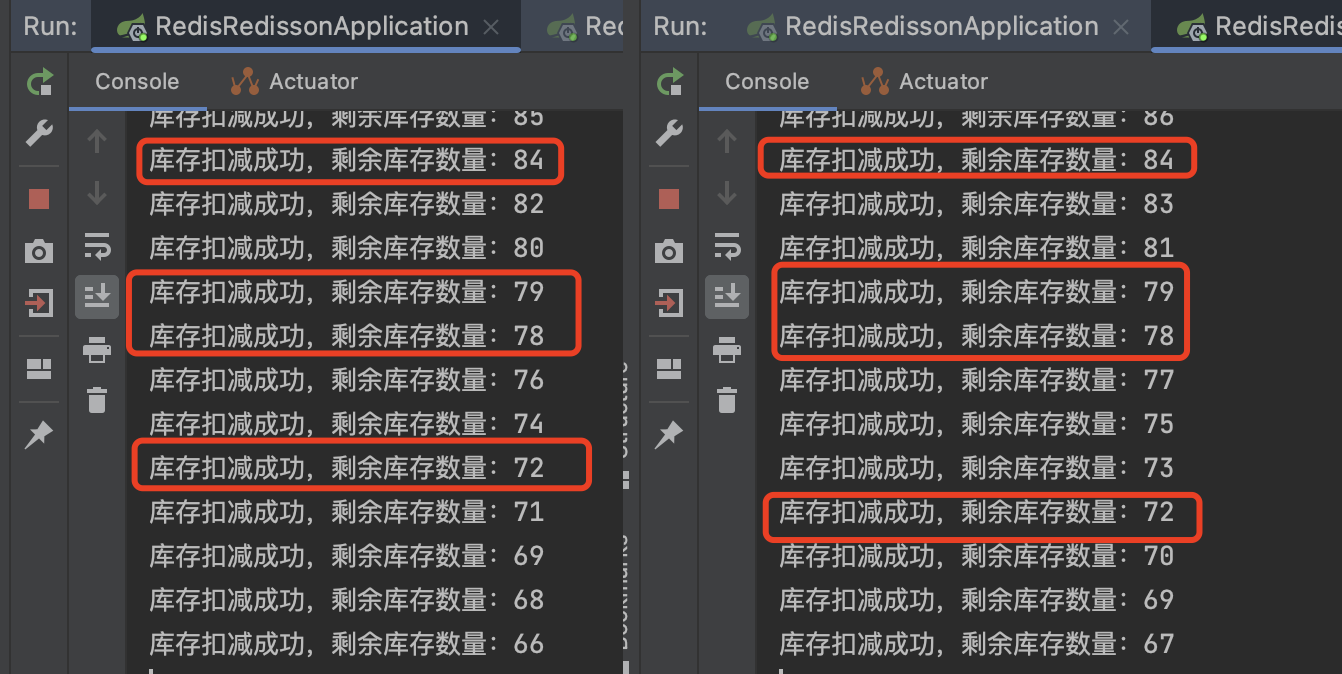
从结果可以明显的看出,因为并发请求导致经出现了超卖现象,2个节点之间互相干扰,set redis的数据也是错的。
总结:在分布式、集群架构下,在高并发场景下,通过synchronized 同步锁是无法解决超卖问题的。
分布式锁的方案有很多,redis是入侵程度最小(大部分公司都会用到redis,所以不需要部署其他中间件)且最常见的解决方案。
redis作为分布式锁的最核心思想:由于redis是单线程模型,所有多线程请求会变成单线程串行化执行。
但是这是有些违背 高并发、高性能初衷的,哪怕redis确实性能很高,基于这点我们需要单独对redis分布锁进行优化,在下面的章节会描述,我们且先来看一下 常见的分布式锁的解决方案。
常见分布式锁解决方案
不太谨慎的解决方案
setnx:set key的value的时候,如果key已经不存在则返回1(true),如果key存在返回0(false)
我们可以通过redis中的setnx命令,来实现分布式锁,在执行业务逻辑之前,我们先去redis中取一把锁(setnx一个key,一般是以 lock开头,加上商品ID作为锁的key),如果返回true,则成功拿到锁,如果false 则key已经存在(被别人拿到锁),我们就返回失败。
因为redis是单线程模型,多个线程同时访问该接口时,只有一个线程可以成功拿到锁,其他线程都会 进入其他的处理逻辑,可以是等待,可以是返回错误。
1 | /** |
注意细节:
- 我们在set key时,给他增加了一个超时时间,避免redis死锁,如果死锁的话会导致其他线程都进不来(拿不到锁)
- 为了保证原子性(一次操作、多次操作要嘛都成功,要嘛都失败),我们尽量把 set key 和设置超时时间放在一个命令上。
- 如果分成2条命令,会有一定的安全隐患,如:set key后突然出现异常代码执行不下去,超时时间没设置上导致死锁
- 为了保证原子性(一次操作、多次操作要嘛都成功,要嘛都失败),我们尽量把 set key 和设置超时时间放在一个命令上。
- 为了避免代码异常出现死锁的情况,这里我们用了try 异常捕获,让他最后都要释放掉锁(del key)
- 如果是机器突然挂了导致的死锁,那就没得办法咯,只能依靠redis自动删除掉过期的key
高并发下锁失效的问题
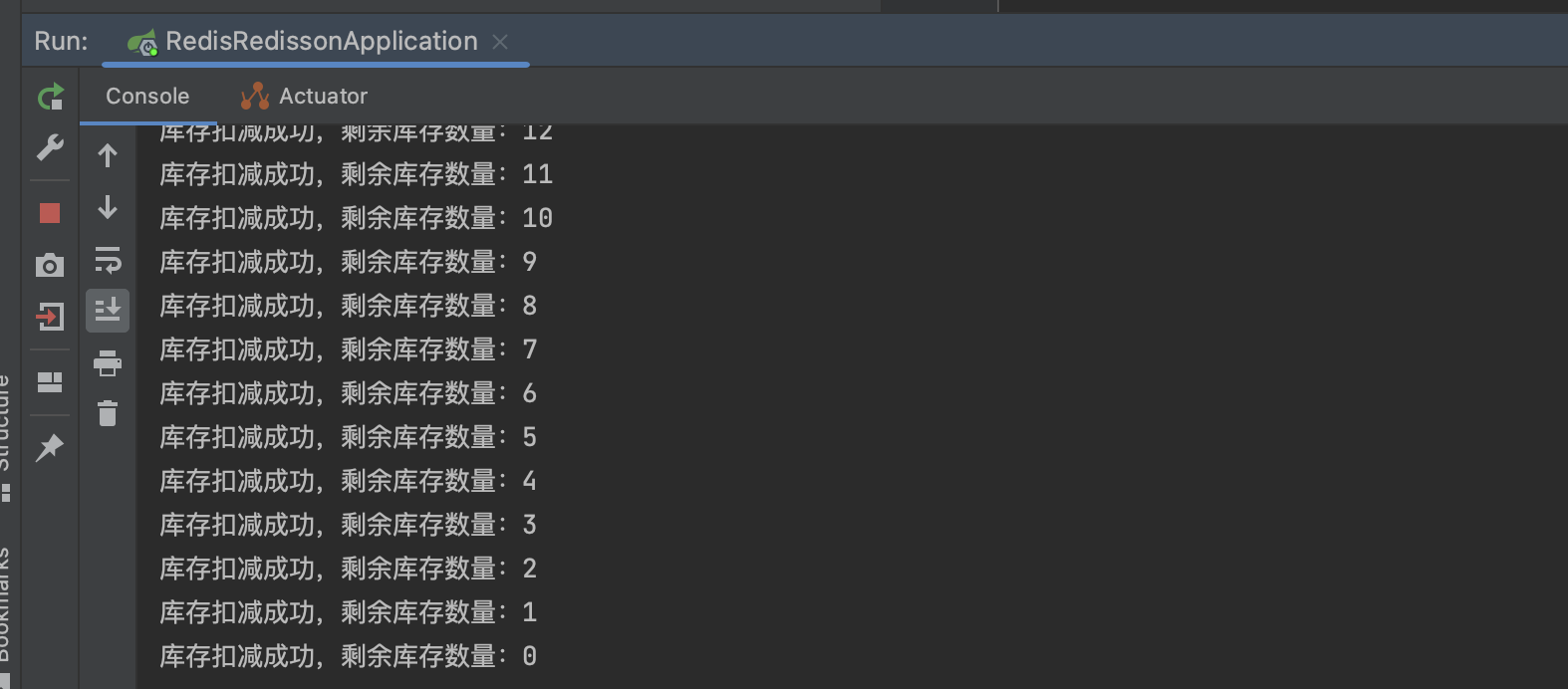
该方案是可以解决分布式下的超卖问题,但是如果是在高并发场景下,很可能锁会一直处于失效状态。
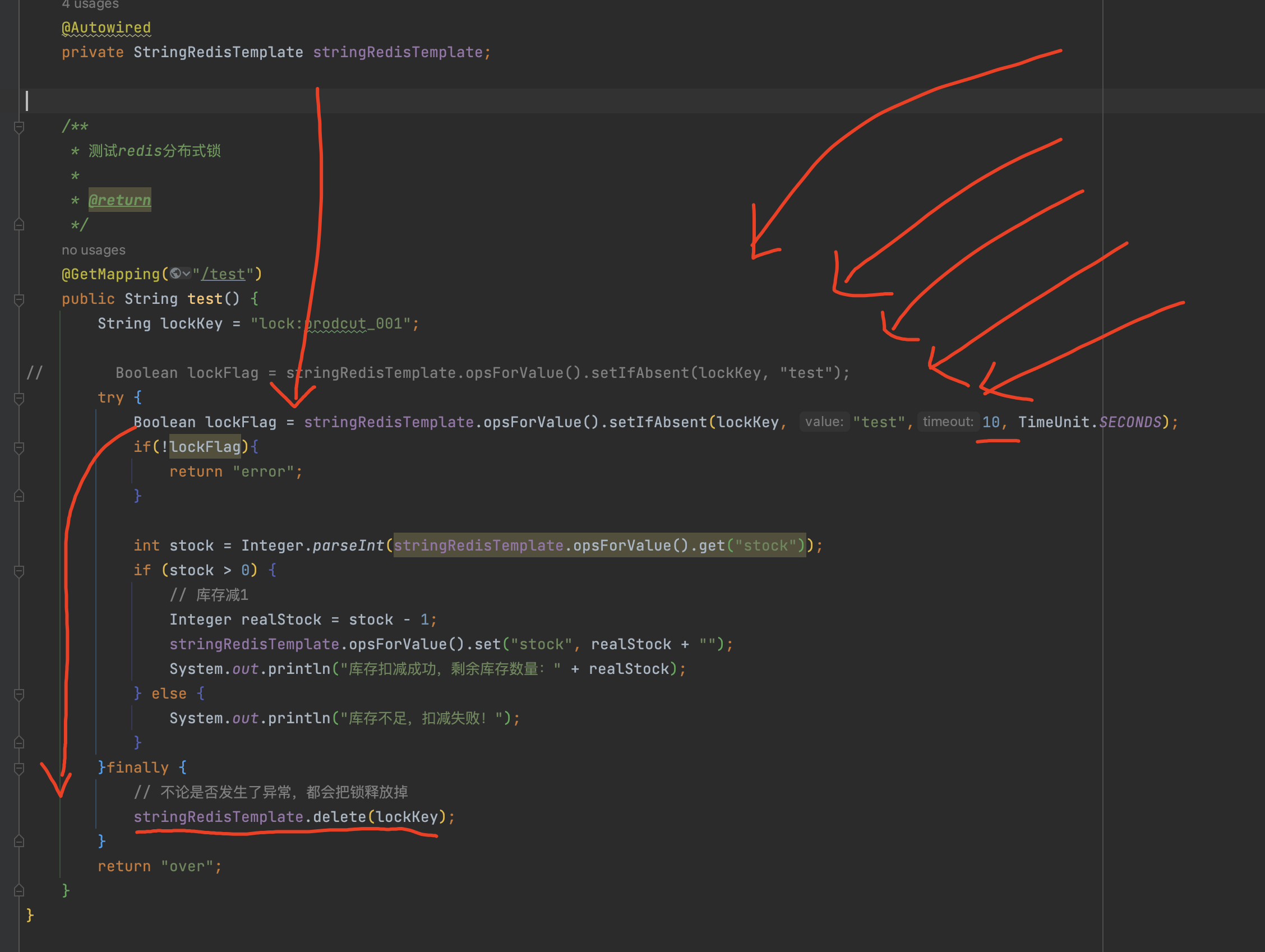
如图所示,假设我们第一个线程拿到锁后执行下面的业务逻辑,在高并发场景下接口反应会比较慢且业务逻辑较为复杂(或业务处理超时),处理时间超过了10秒,redis自动释放掉了这把锁,第二个线程进入接口时成功取到了锁后就会执行业务逻辑,此时第一个线程执行业务逻辑结束后,又会把锁删除掉,导致第三线程进入接口又取到锁,以此类推。
高并发压测,演示我们上面说的情况:
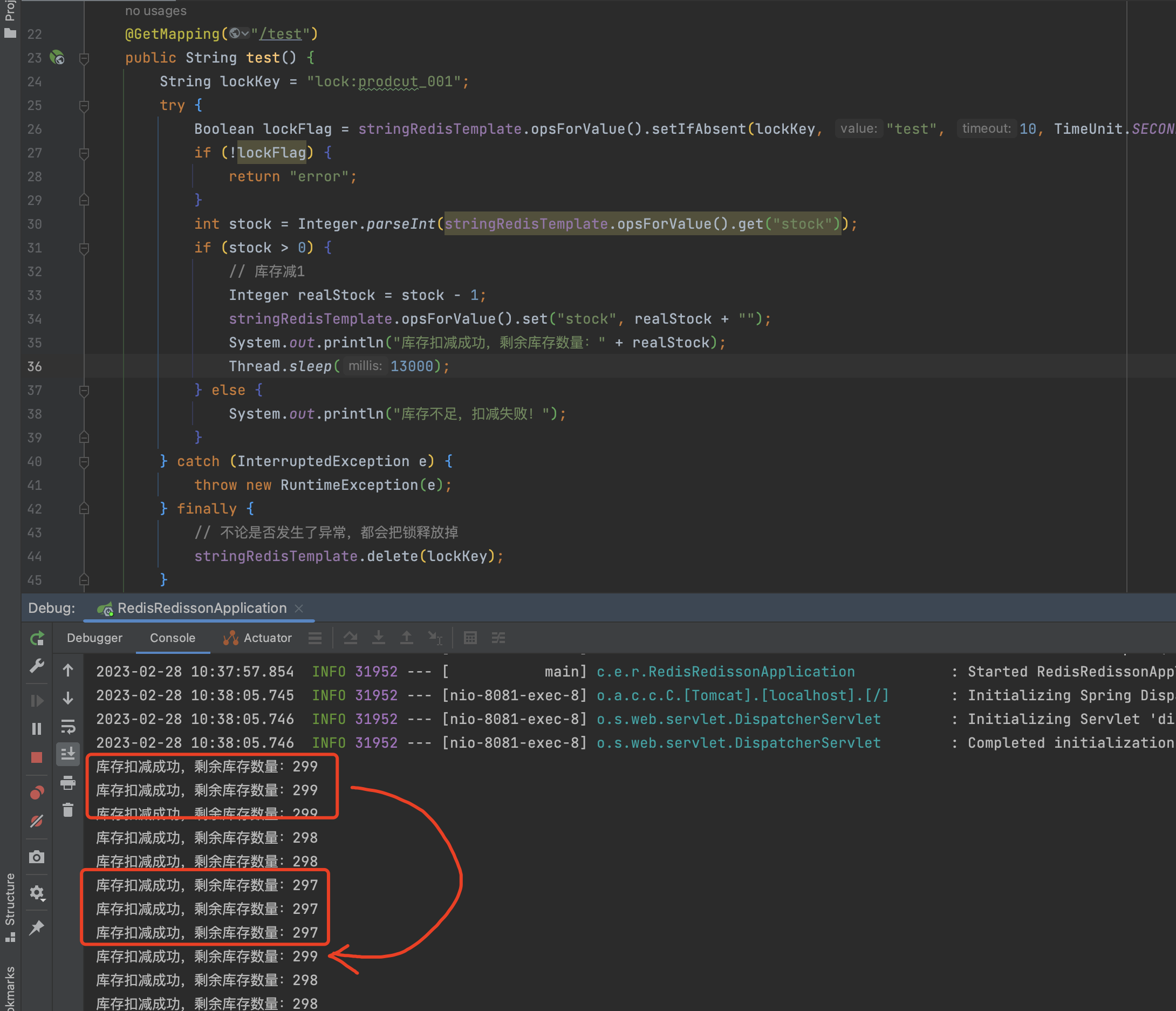
临界点锁失效的问题
1 | /** |
相较之前的Demo,我们做了一些调整,生成了UUID作为线程唯一标识并传入了锁的value中,用于表明这个锁是哪个线程拿到的,最后在释放锁的时候,判断这个锁是不是当前线程的,如果是则释放锁。
目的是为了确保其他线程不要来释放我线程拿到的锁。
临界点问题:
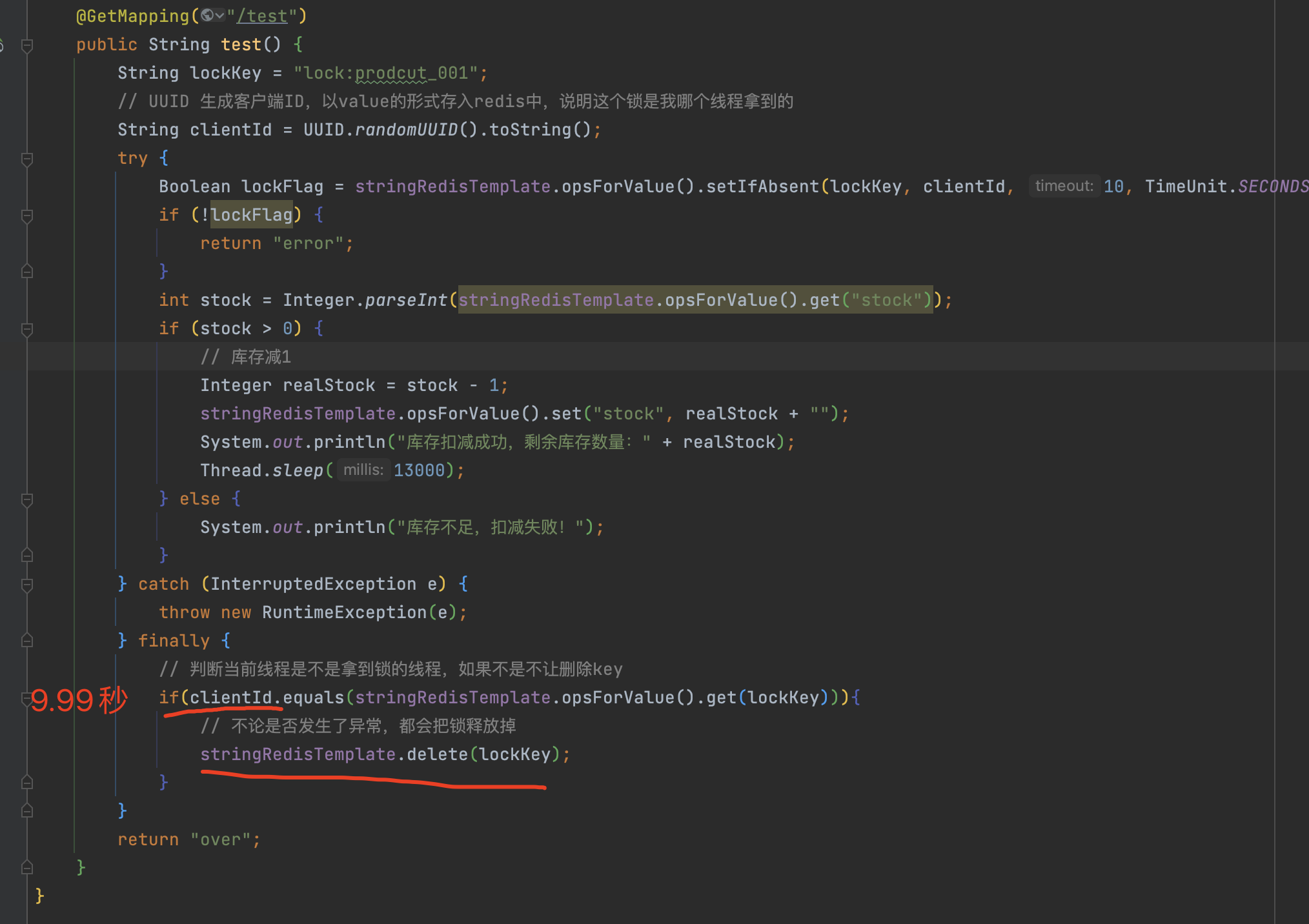
但是即便是这样,还是会存在临界点问题,比较极端,但是高并发场景下还是可能会出现。
当A线程执行到图中位置,超时时间已经9.99秒,此时锁还是没有超时的,所以A线程会执行if里面的方法,当A线程准备执行delete之时,锁超时被释放了,B线程进入了接口后 拿到了锁后,A线程执行了delete命令,把锁又给删除了,C线程就又进入接口拿到新的锁,以此类推,又并发执行了。
锁续命原理(重要)
上面我们一些锁失效的问题,都是基于 redis 锁超时导致的,我们可以通过另外一种方式来解决锁超时的问题,从而解决锁失效问题。
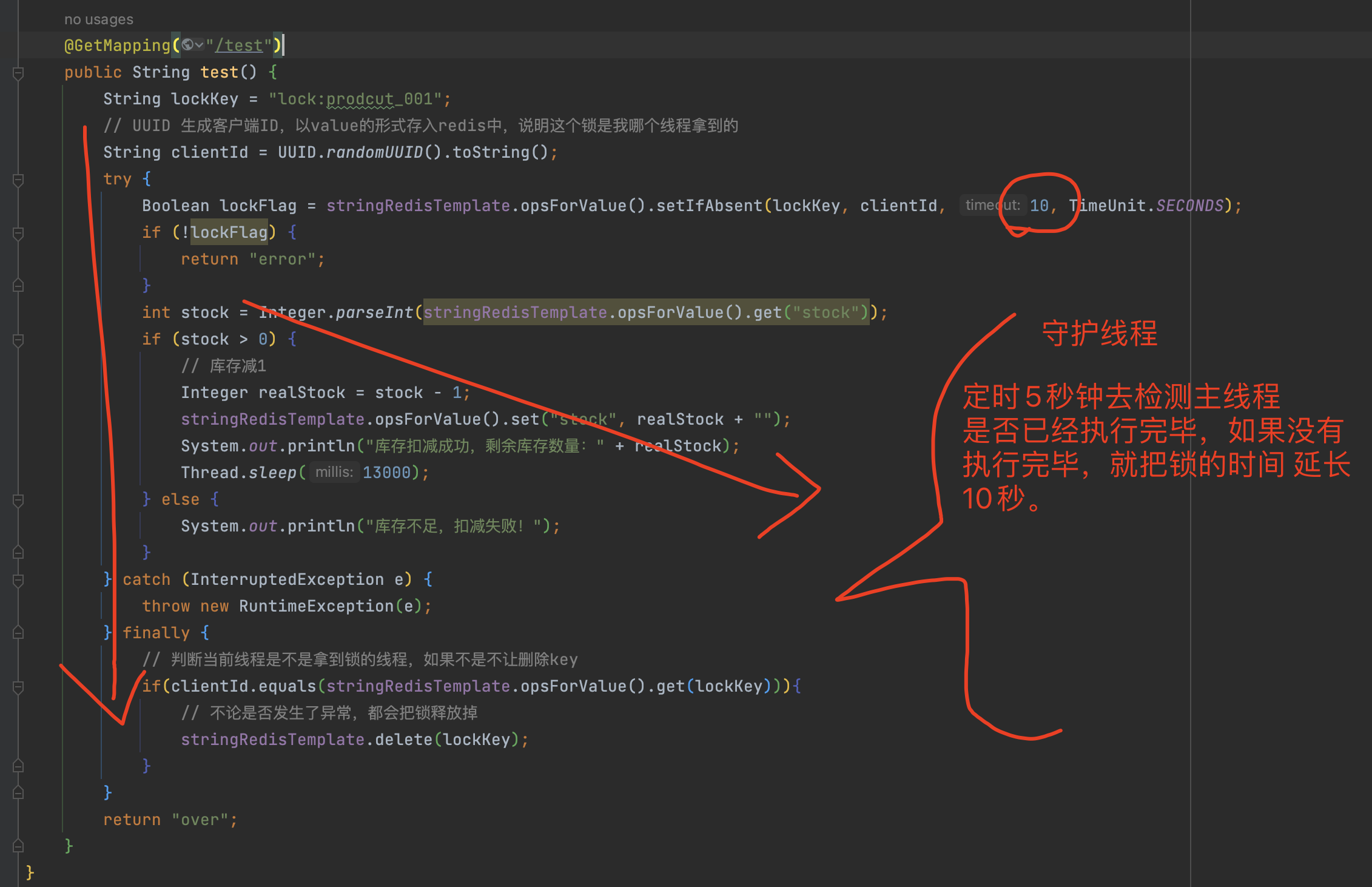
当主线程拿到锁后,就会立即开启守护线程,守护线程会定时(小于超时时间)去检测主线程是否执行完毕,如果还没有执行完毕的话,就把锁的超时时间在延长10秒。
好处:在主线程没有结束之前,锁就不会到期,这样就可以解决很多锁失效的问题 。
Redisson实现分布式锁
Redisson是一款具有诸多高性能功能的综合类开源中间件,我们可以通过这个工具包来快速的实现分布式锁,而不是自己造轮子,不然会浪费很多时间以及踩很多坑 。
Redisson 代码实现
pom.xml
1 | <dependency> |
Controller:
1 | /** |
Redisson分布式锁原理
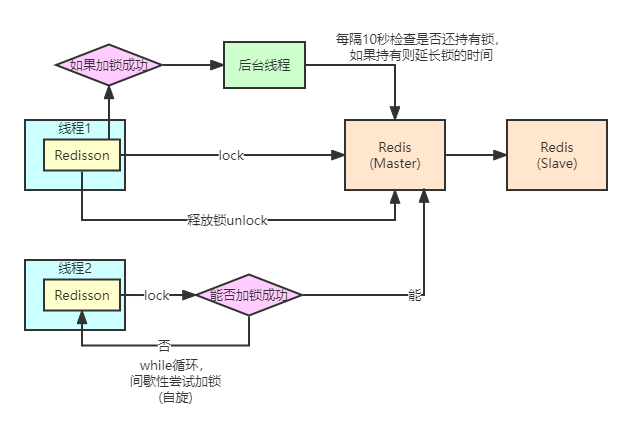
- 线程1取到锁后进行加锁,加锁成功后创建后台线程(守护线程),每隔10秒检查是否还持有锁,如果持有则延长锁的时间,等到线程1执行结束后会释放锁
- 线程2取到锁后尝试加锁,加锁成功后和第一步一样。如果没有成功加锁,会进行while循环,循环期间 间歇性尝试加锁。
Lua脚本基本知识
分析Redisson源码之前,要先对lua脚本有一个基本知识有个大致的理解,下面将简单的讲述一下lua脚本。
在redis2.6后兼容了lua脚本功能,允许开发者使用lua脚本传到redis中执行。
使用脚本的好处:
- 减少网络开销
- 原本需要5次的网络请求,可以放在lua脚本里面一起执行,只需要一次网络请求,减少了网络开销,类似于管道
- 原子操作
- redis会将脚本作为一个整体一起执行,在没有执行结束之前,其他客户端是无法插队的,必须等待脚本全部执行结束
- 因为redis是单线程模型,如果redis在执行某lua脚本时,必须得全部执行结束之后,才会去执行其他客户端的命令
- 值得注意的是,管道并不保证原子性,而lua脚本可以保证
- redis会将脚本作为一个整体一起执行,在没有执行结束之前,其他客户端是无法插队的,必须等待脚本全部执行结束
- 替代redis的事务功能
- redis自带的事务功能很鸡肋,一般不会使用,通过lua脚本可以实现常规的事务功能,redis官方也推荐使用lua来实现事务功能。
redis中执行lua脚本

1 | // 2 代表有2个key |
{KEYS[1]} ,{KEYS[2]} 是占位符,占位符和key 是一一对应的,ARGV[1]是指取出 test1的value值,ARGV[2]是指取出 test2的value值。
jedis执行lua脚本
1 | public static void main(String[] args) { |
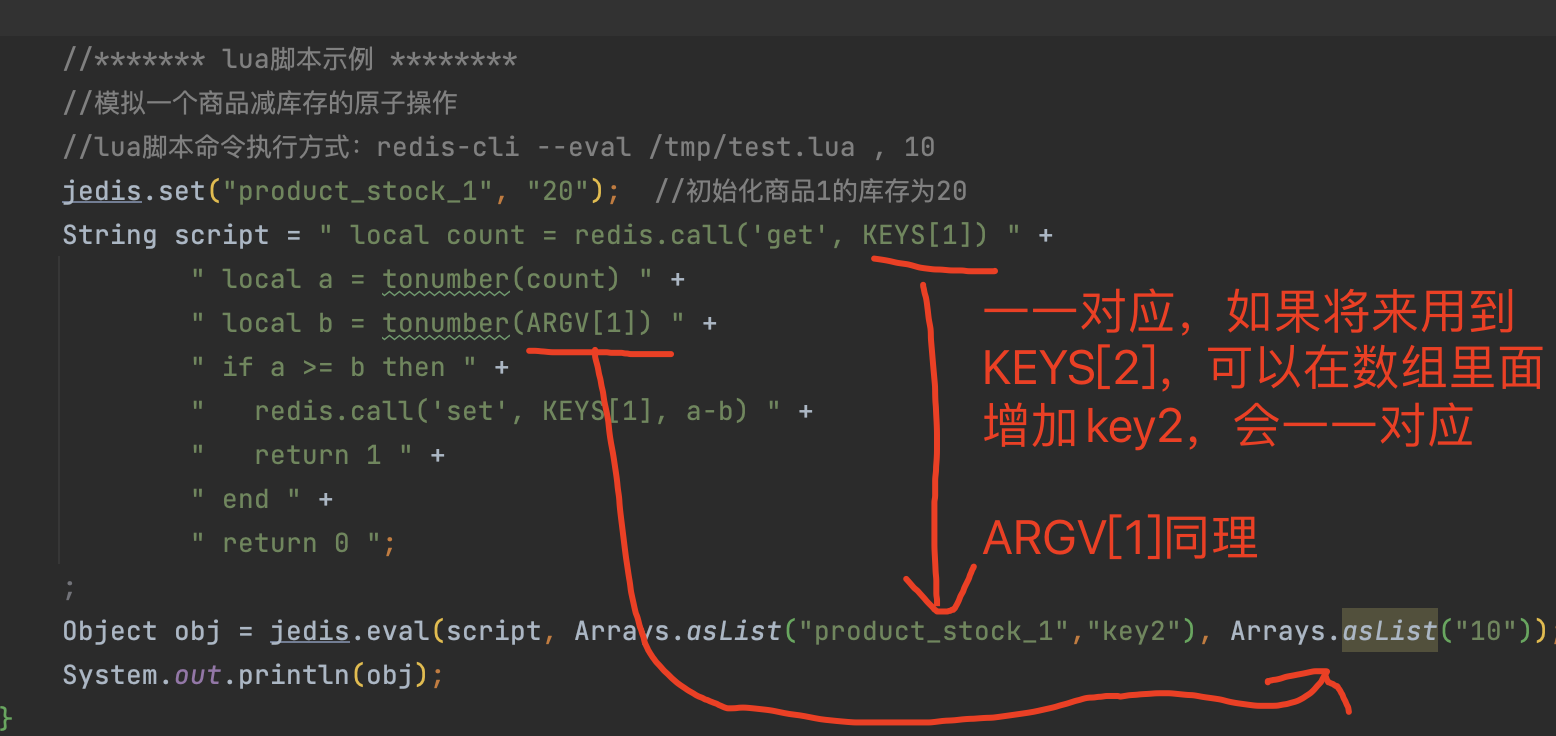
在这里我们通过jedis客户端来实现编写lua脚本并上传到redis中运行,基于lua脚本在redis中的原子性,就不会出现超卖问题。
KEYS[1] 和 eval的数组四一一对应的,ARGV[1]同理,如果需要多增加key,直接可以在数组后面增加新的key就行。
分析Redisson源码
我们来分析Redisson底层源码,明白Redisson是如何实现redis中的分布式锁。
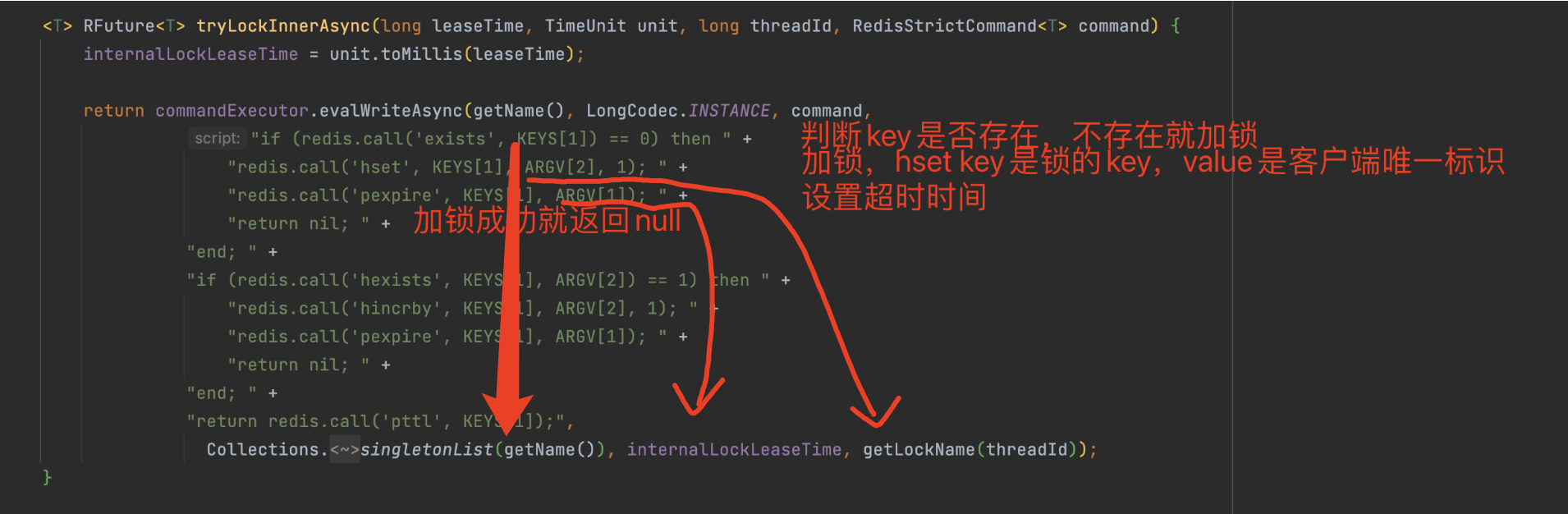
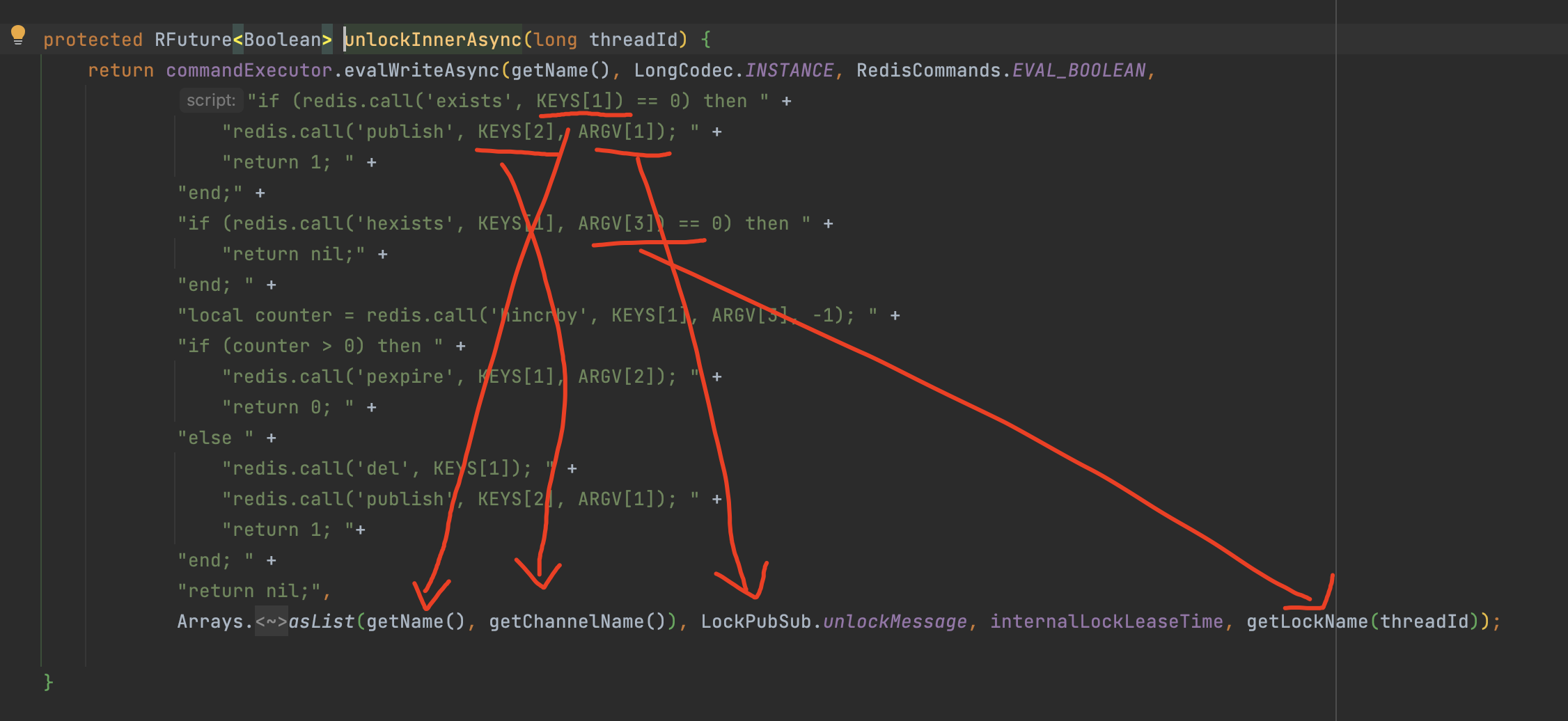
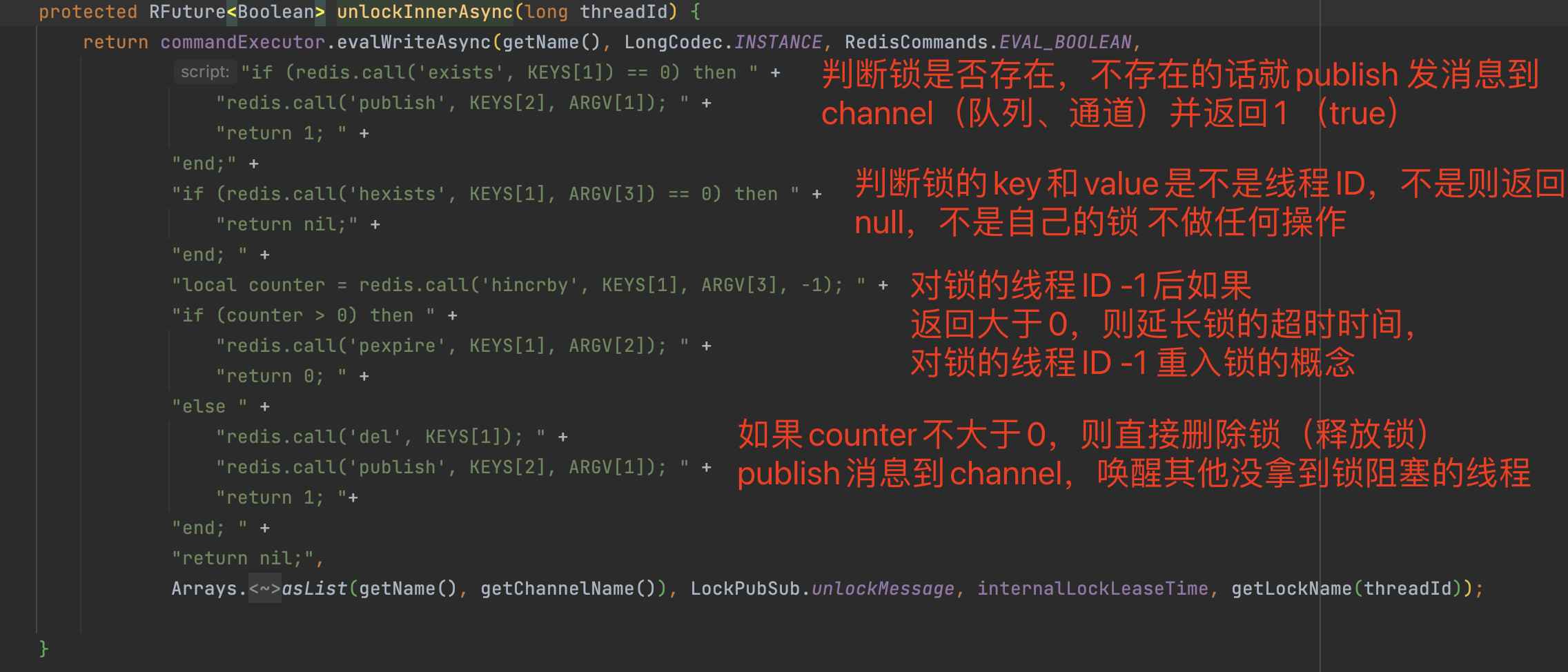
lua脚本实现分布式锁

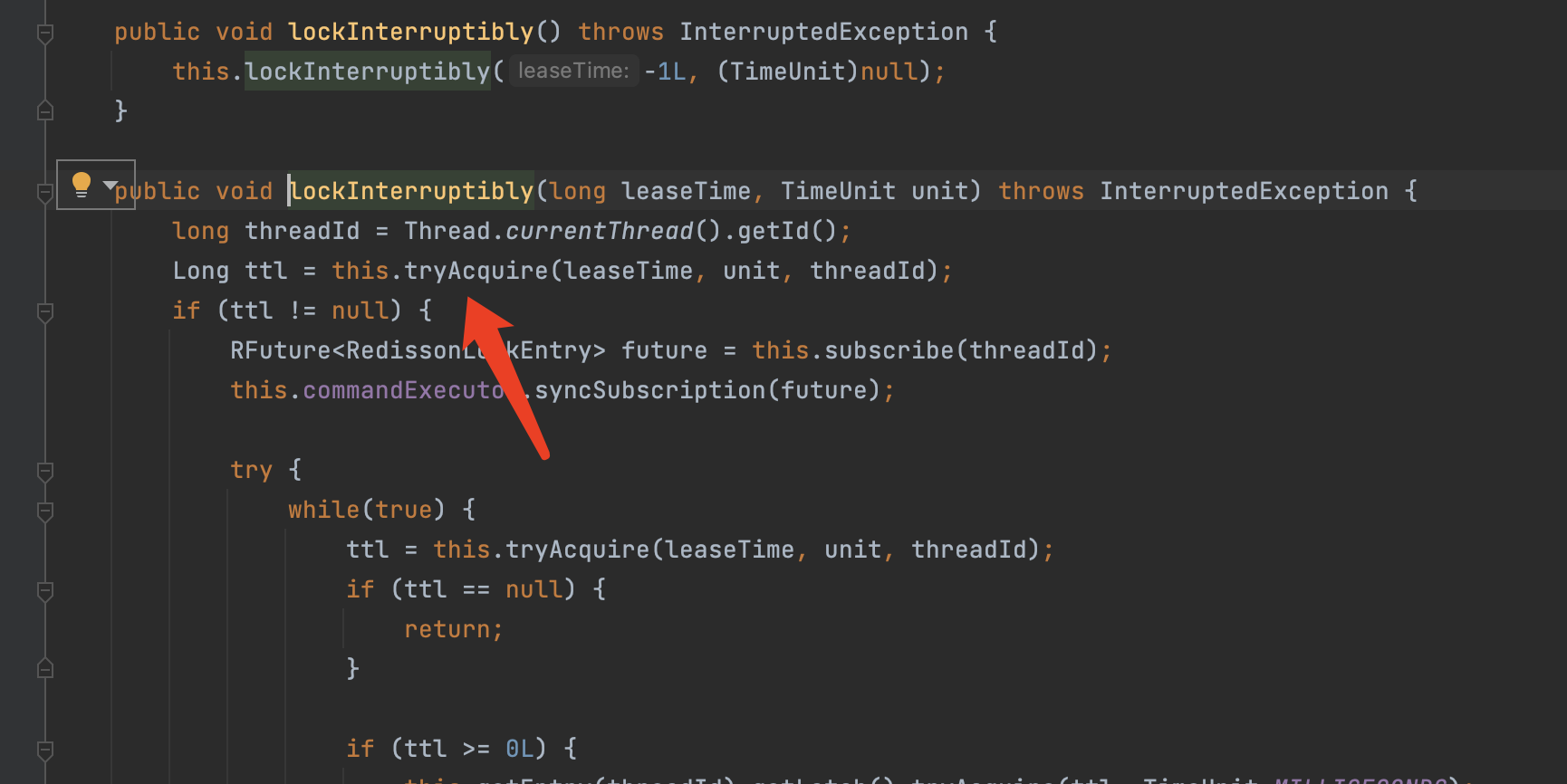

这里通过一段lua脚本来实现了redis的分布式锁,接下来我们来分析一下lua脚本都干了什么。
1 | // |
传入的key:
- 锁的Key名称,由我们定义然后创建锁的时候传入

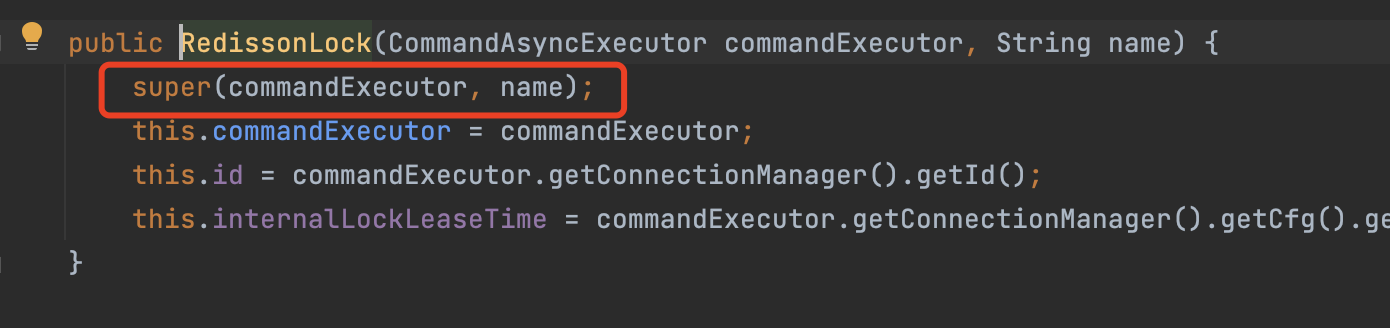


传入的参数:
- 超时时间(看门狗超时时间)
- 默认超时时间:30秒,如果不满意超时时间,可以在初始化redisson时调整,但是不建议修改,30秒大部分业务场景刚刚好。

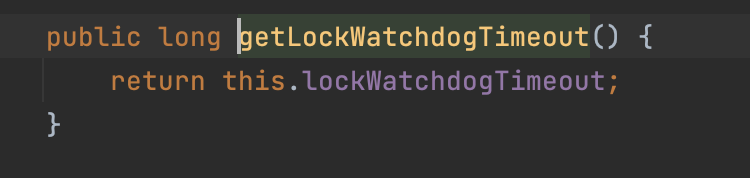
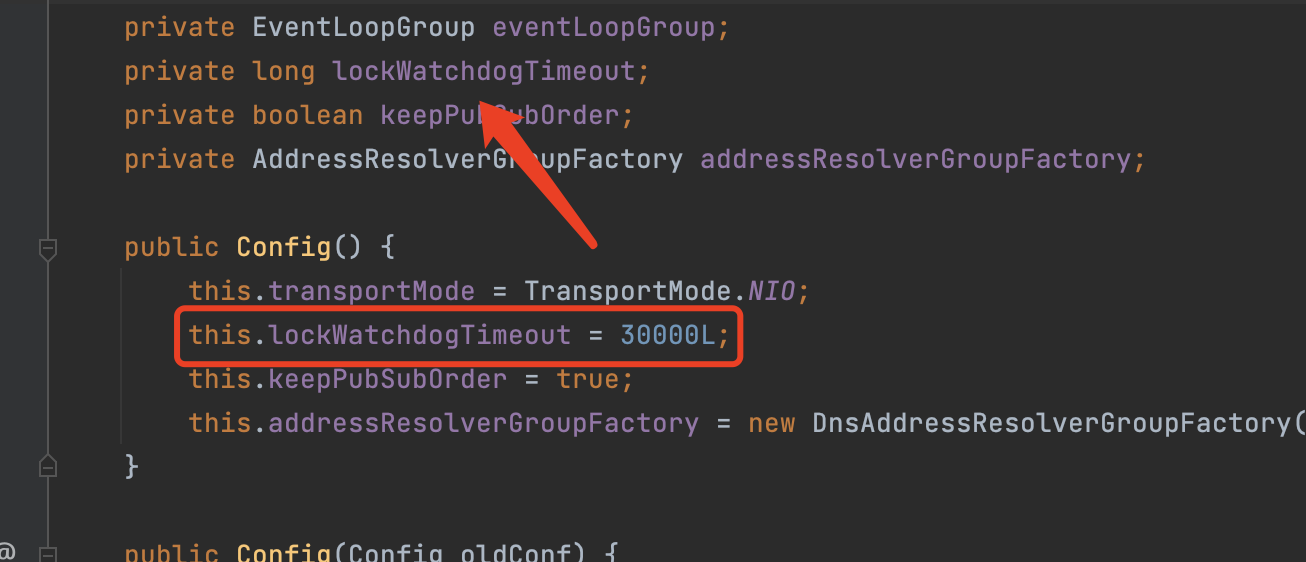
- 手动修改看门狗超时时间
- 客户端唯一标识,由UUID + 线程ThreadID组成
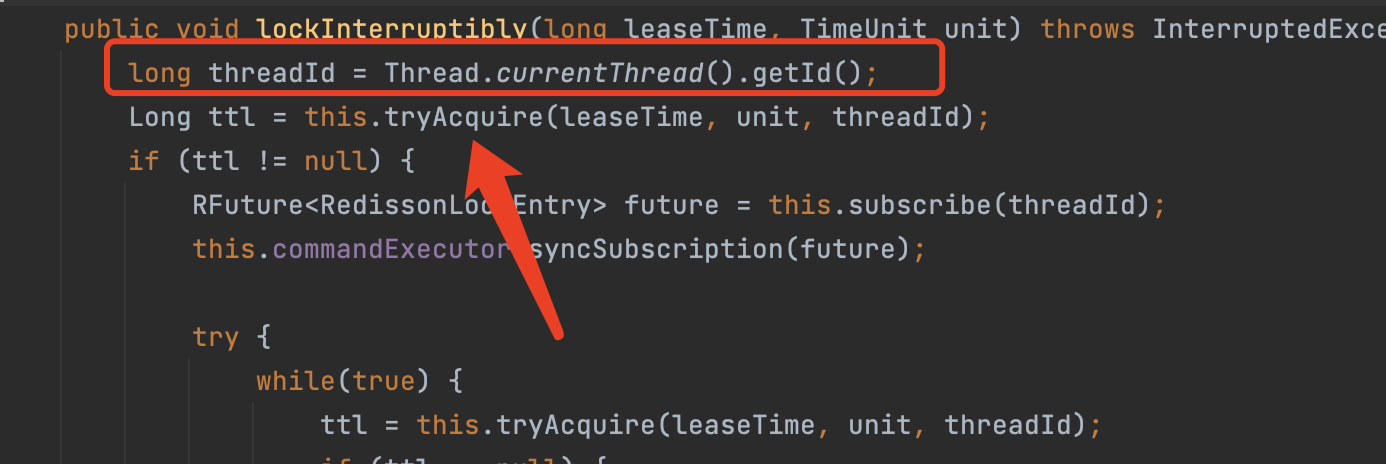

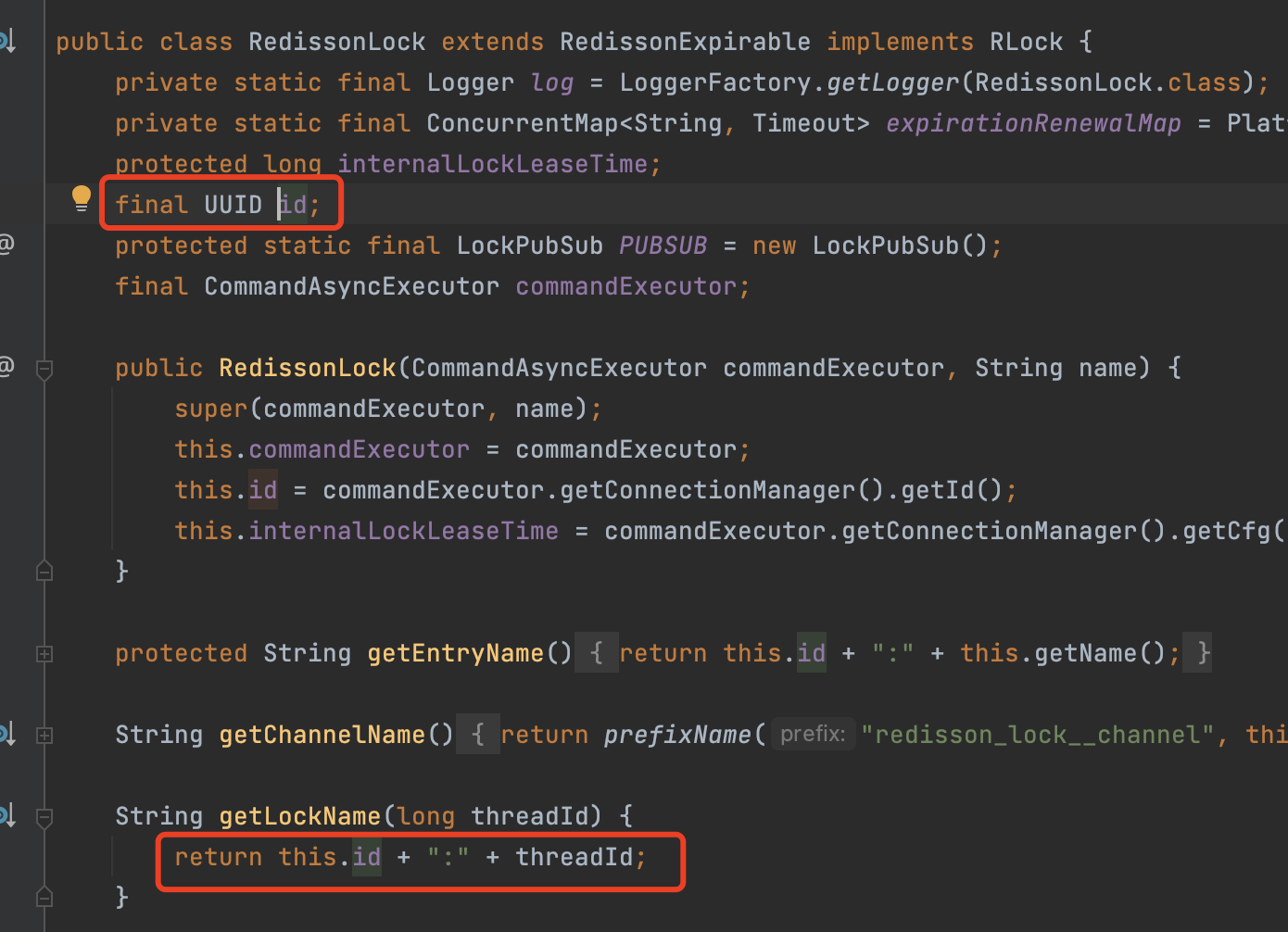
分布式锁守护线程
上面说分布式原理的时候有说过,redisson主线程在加锁成功后会开启守护线程,来循环判断主线程是否持有锁,保证主线程锁不过期。
接下来我们来阅读并分析一下,他的源代码是如何实现的守护线程。
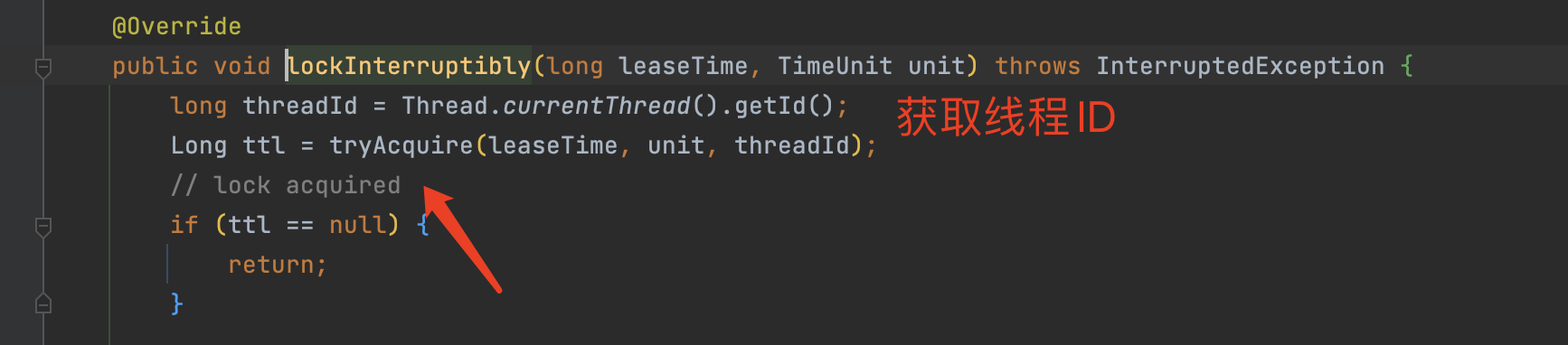
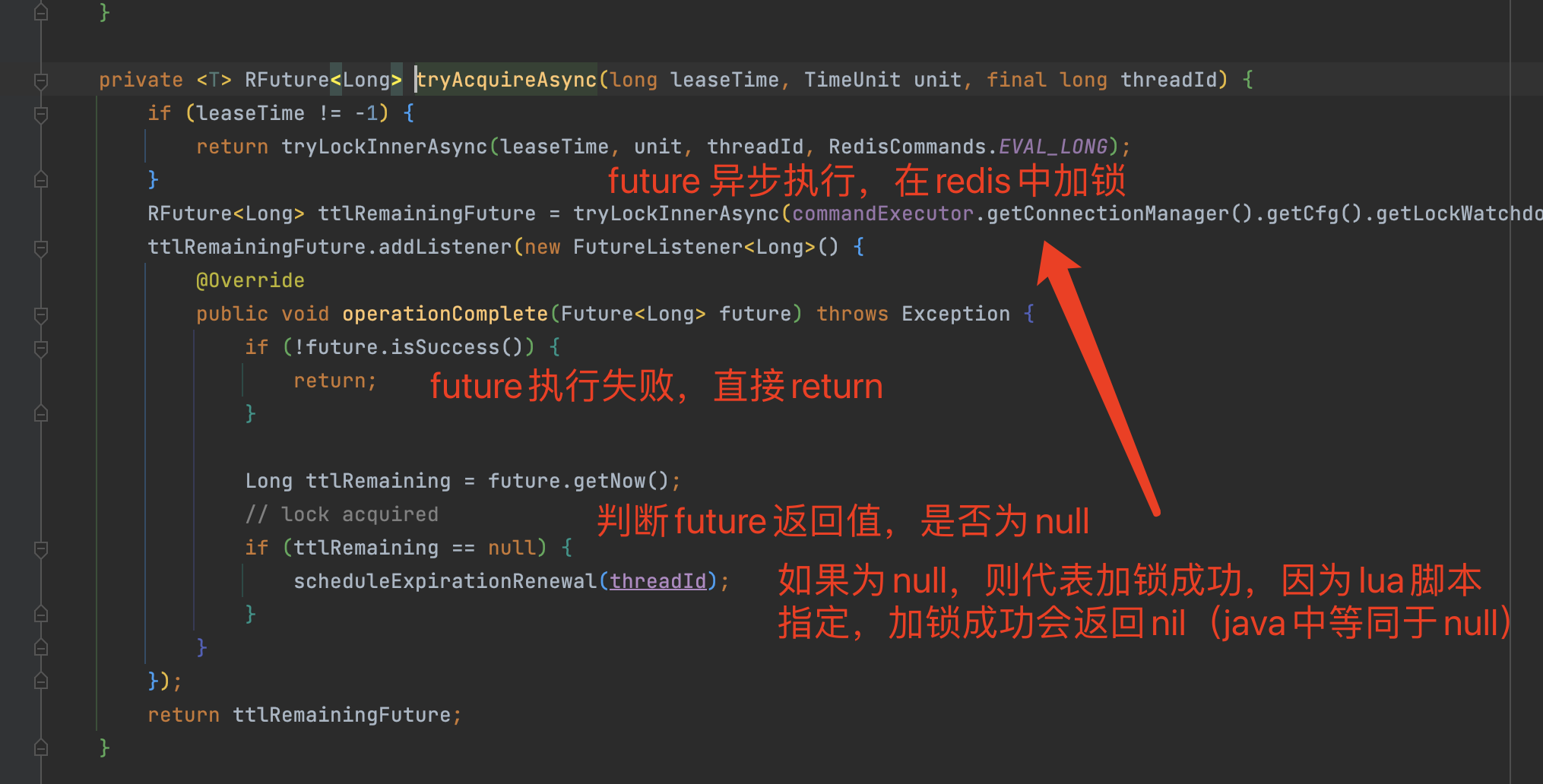
加锁的lua脚本命令:
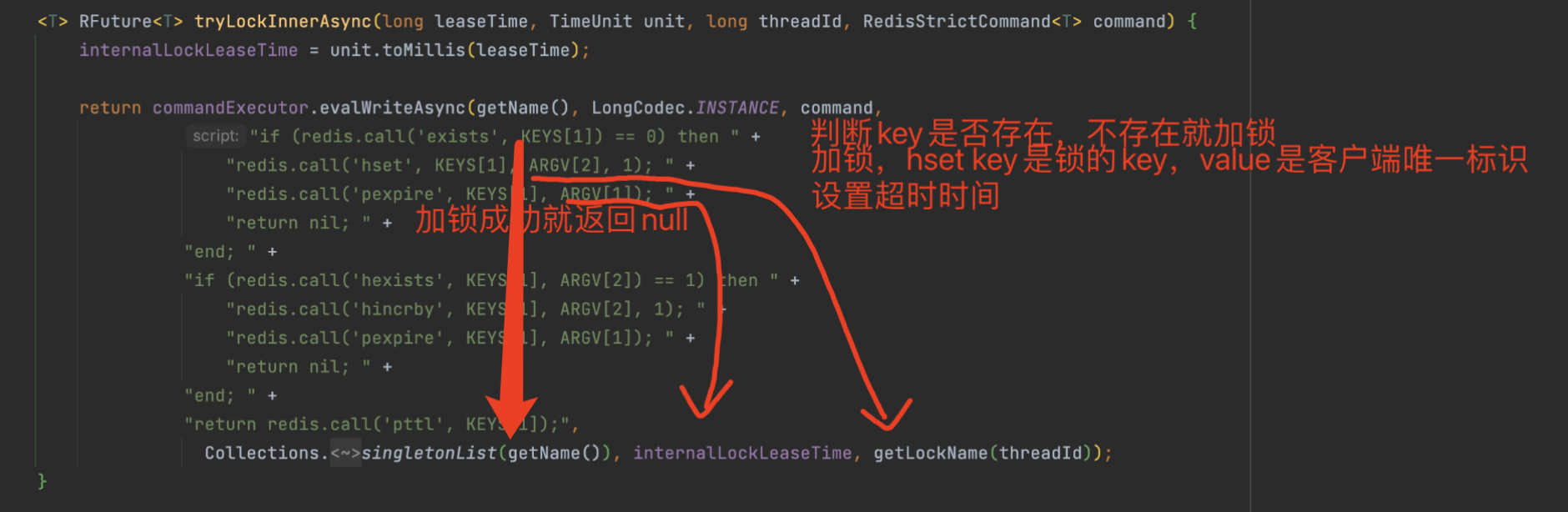
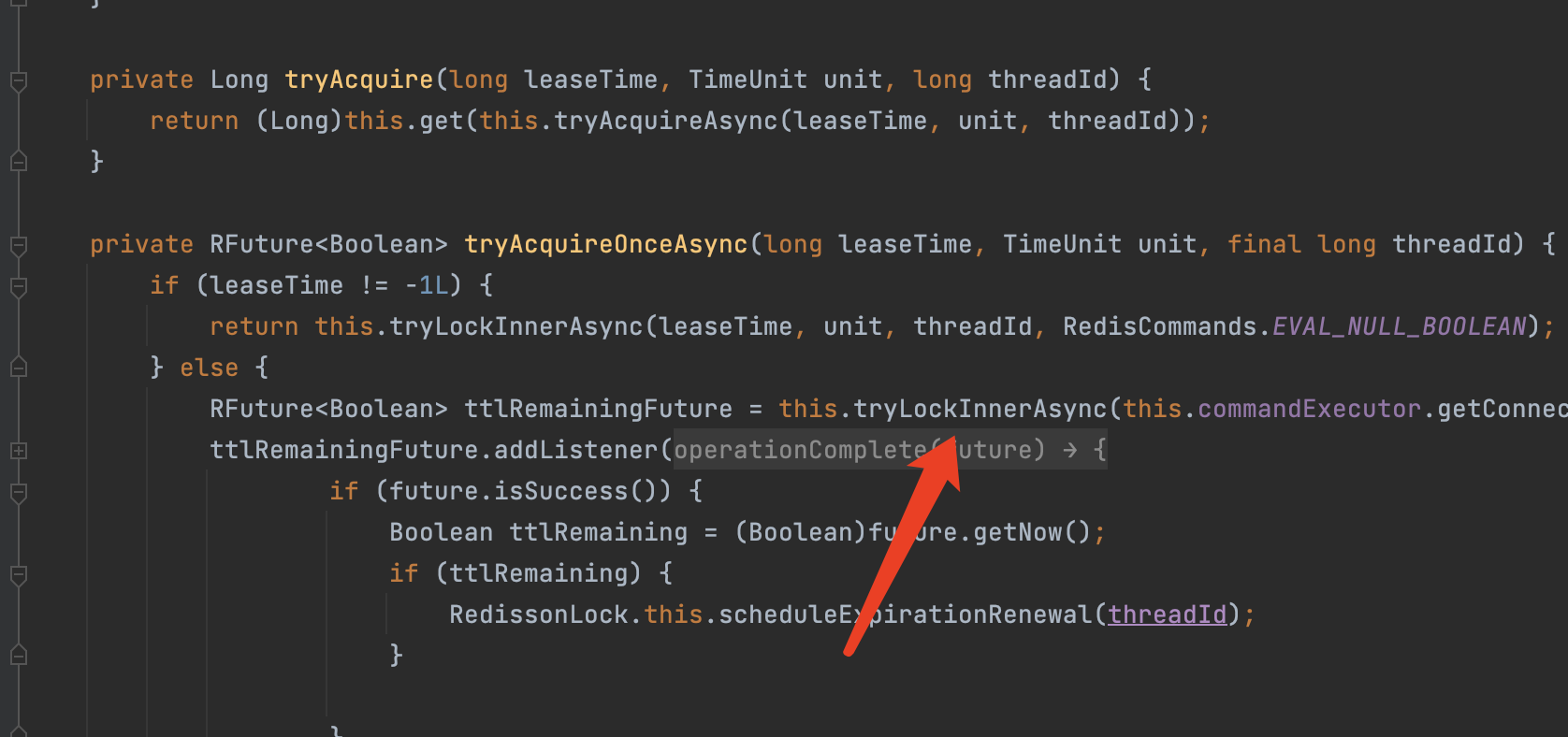
scheduleExpirationRenewal(核心,守护进程)方法:
- 循环时间内检测 主线程是否还持有锁(是否执行结束),如果还存在代表没有结束,则 延长超时时间,如果不存在则直接返回。
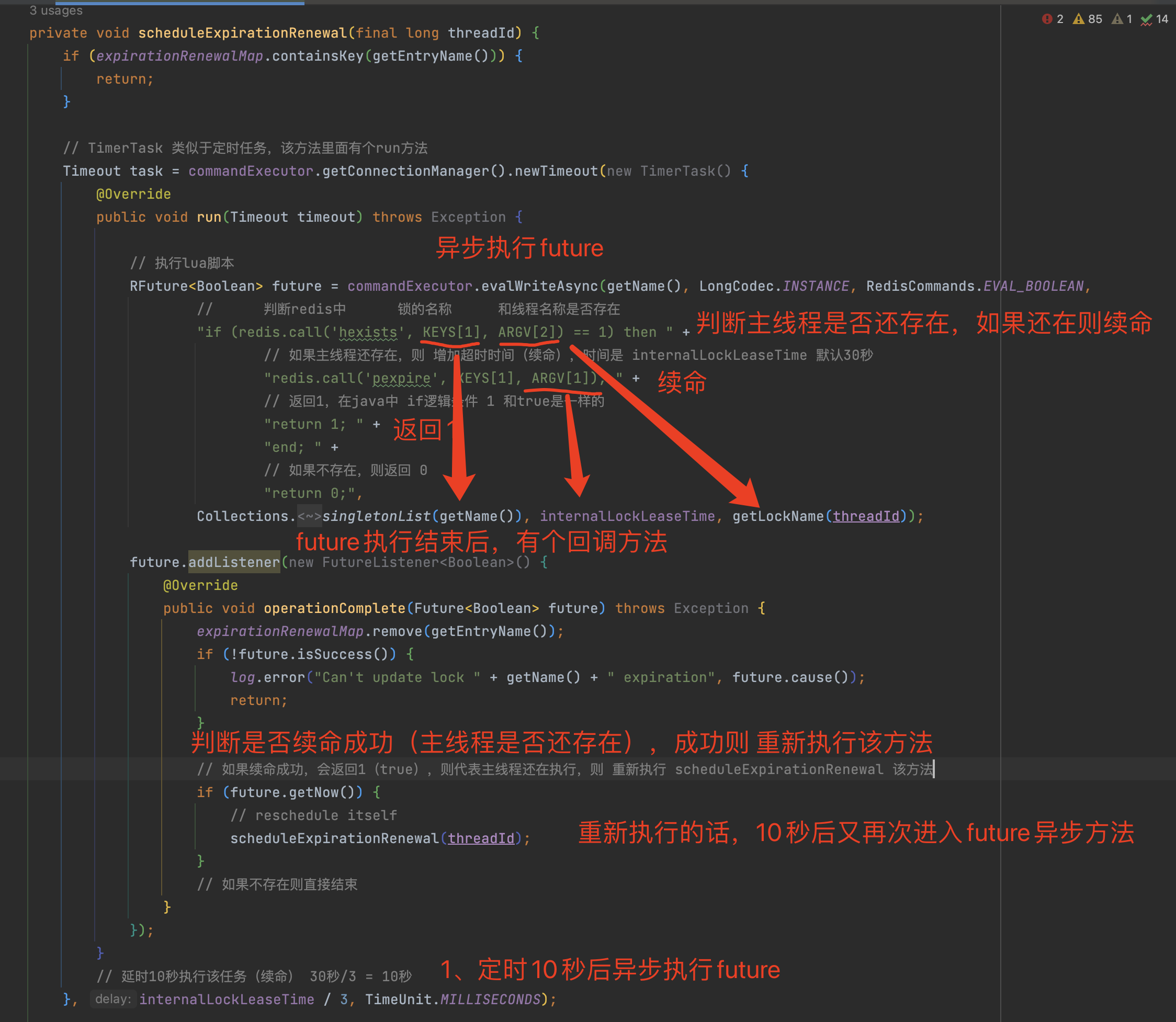
10秒后执行TimerTask(类似于定时任务)
- 看门狗时间 默认30秒,30秒/3 = 10秒,就是定时任务的时间
异步执行future,向redis发送lua脚本命令(续命)
判断redis中 锁的key和线程唯一标识是否还存在
如果存在代表主线程还没执行结束,继续为主线程的锁 增加超时时间(续命)
如果不存在,则代表主线程执行结束,返回0(false)
1
2
3
4
5
6
7
8
9
10
11RFuture<Boolean> future = commandExecutor.evalWriteAsync(getName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN,
// 判断redis中 锁的名称 和线程唯一标识是否存在
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
// 如果主线程还存在,则 增加超时时间(续命),时间是 internalLockLeaseTime 默认30秒
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
// 返回1,在java中 if逻辑条件 1 和true是一样的
"return 1; " +
"end; " +
// 如果不存在,则返回 0
"return 0;",
Collections.<Object>singletonList(getName()), internalLockLeaseTime, getLockName(threadId));
异步执行结束后,future有一个回调方法(listener)可以监听到 异步执行结果
- 判断异步执行结果是否为1(true)
- 如果为true,则代表 续命成功,主线程还没执行结束还持有锁,继续执行 scheduleExpirationRenewal(threadId)方法,继续下一轮的检测(检测主线程是否持有锁,持有锁代表 主线程没有执行结束),直到锁释放为止
- 如果为false,则结束守护进程
- 判断异步执行结果是否为1(true)
while自循环加锁

我们第一次尝试加锁时,加锁成功返回null,加锁失败则返回 锁的剩余超时时间。
- 加锁失败进入while循环
- 尝试再次加锁,加锁成功则退出循环
- 加锁失败,则判断剩余超时时间 ttl是否大于等于0,如果大于等于,就把线程进行阻塞,阻塞时间是 锁的剩余超时时间
- 该阻塞并不会占用CPU线程和资源,不影响CPU的其他操作。
- 阻塞时间后,方法结束 再次进入while循环
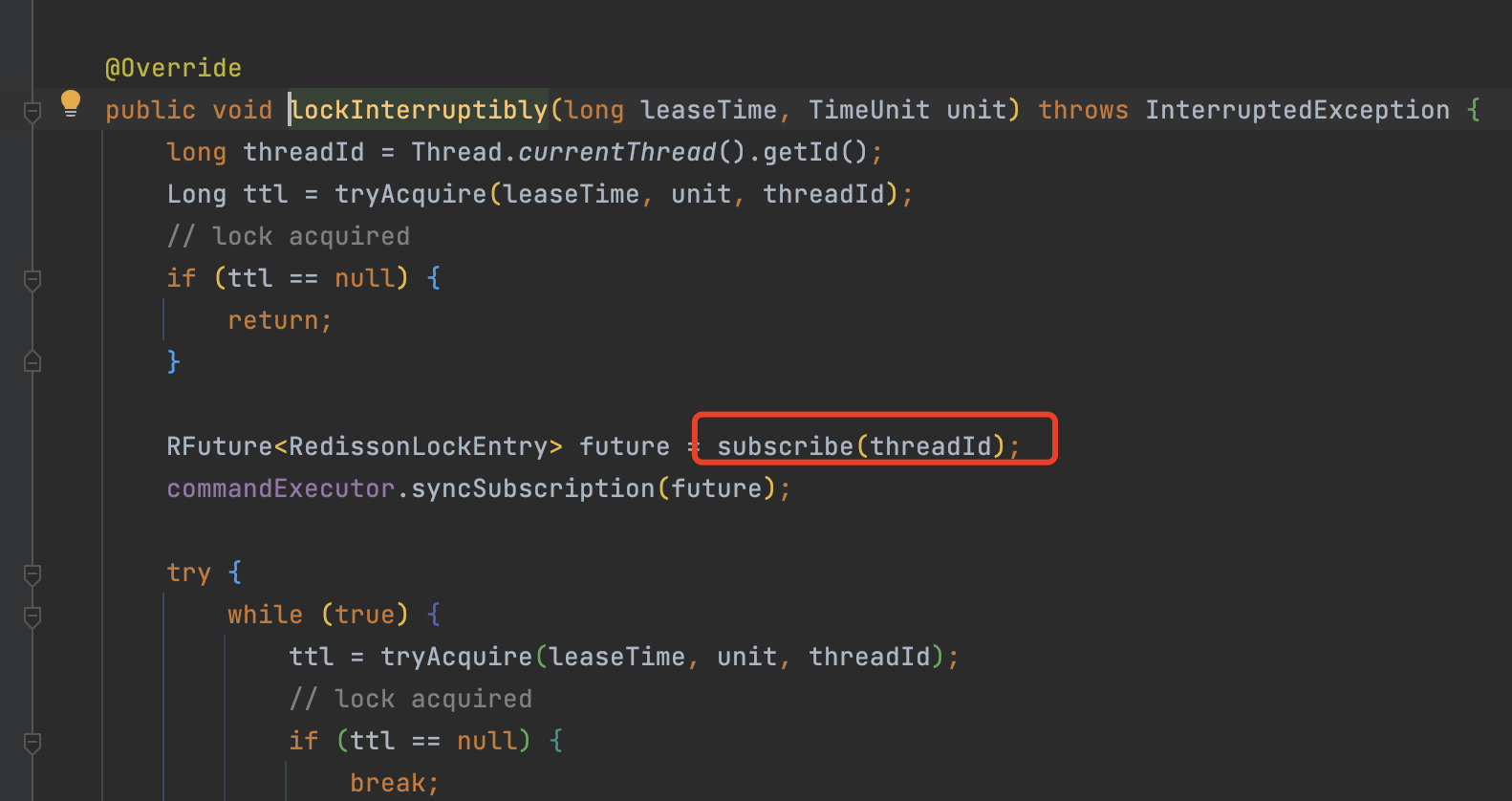
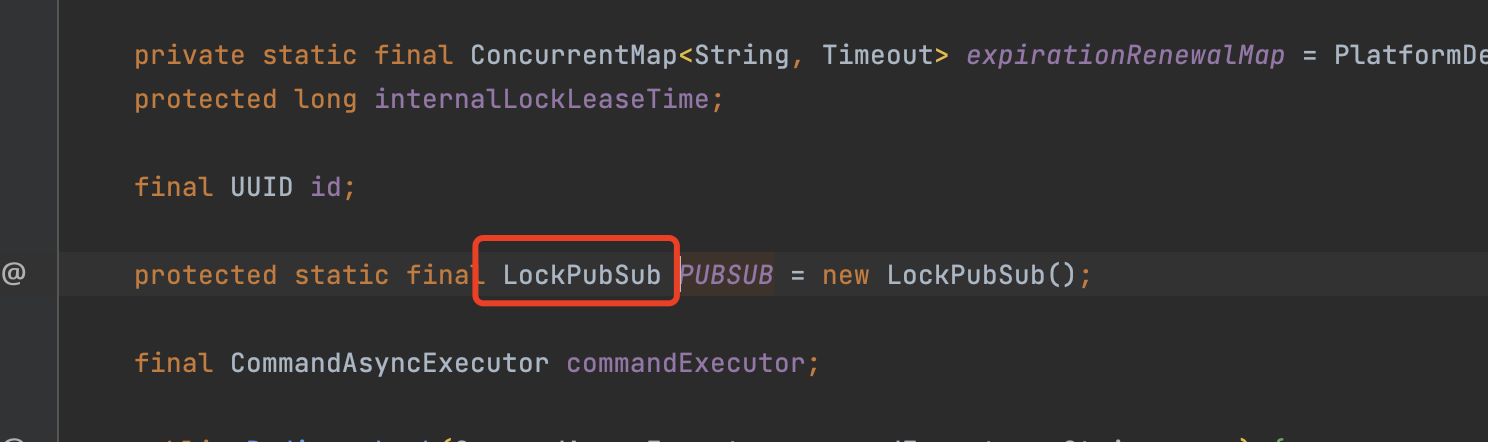
订阅channel
问题:此时线程A拿到了锁,线程B没拿到锁进入while循环尝试拿锁失败等待TTL剩余超时时间(假设是25秒),但是线程A 用了不到5秒就执行结束了方法并释放了锁,线程B就要一直等到超时时间25秒到了才会再次执行while循环 拿锁吗?
这明显设计是不合理的,白白等待那么长的时间,为了解决这个问题,redisson对于没抢到锁的线程会订阅一个channel通道,等线程A执行结束后释放了锁时,会发送释放锁的msg给channel,没抢到锁的线程会在第一时间收到消息,收到消息后马上恢复阻塞的线程,继续while循环拿锁。

channel名称:固定前缀:redisson_lock__channel + 锁key 作为channel的名称。

释放锁源码分析
释放锁lua脚本:
接收channel 唤醒线程
唤醒机制
- 没有抢到锁的线程会去订阅锁的channel后阻塞线程,等其他线程释放锁后会发送msg到channel,唤醒其他没抢到锁而阻塞的线程。
源码分析
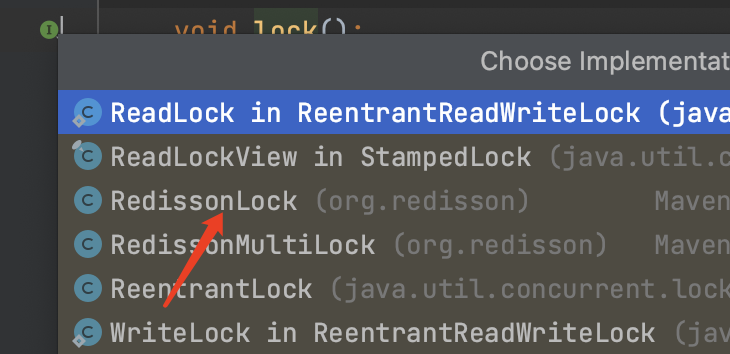
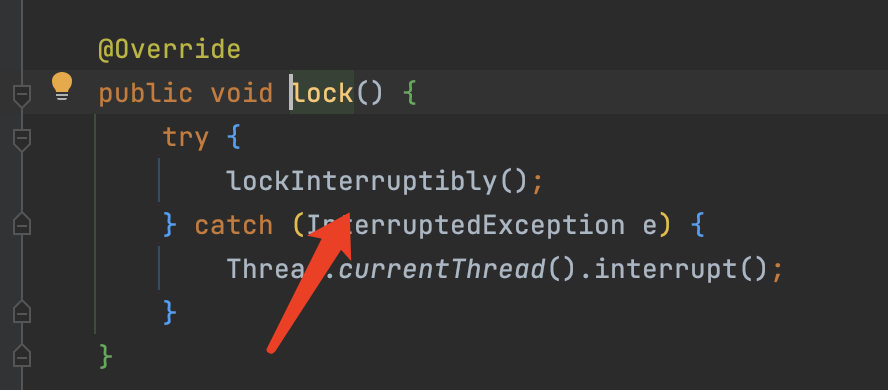


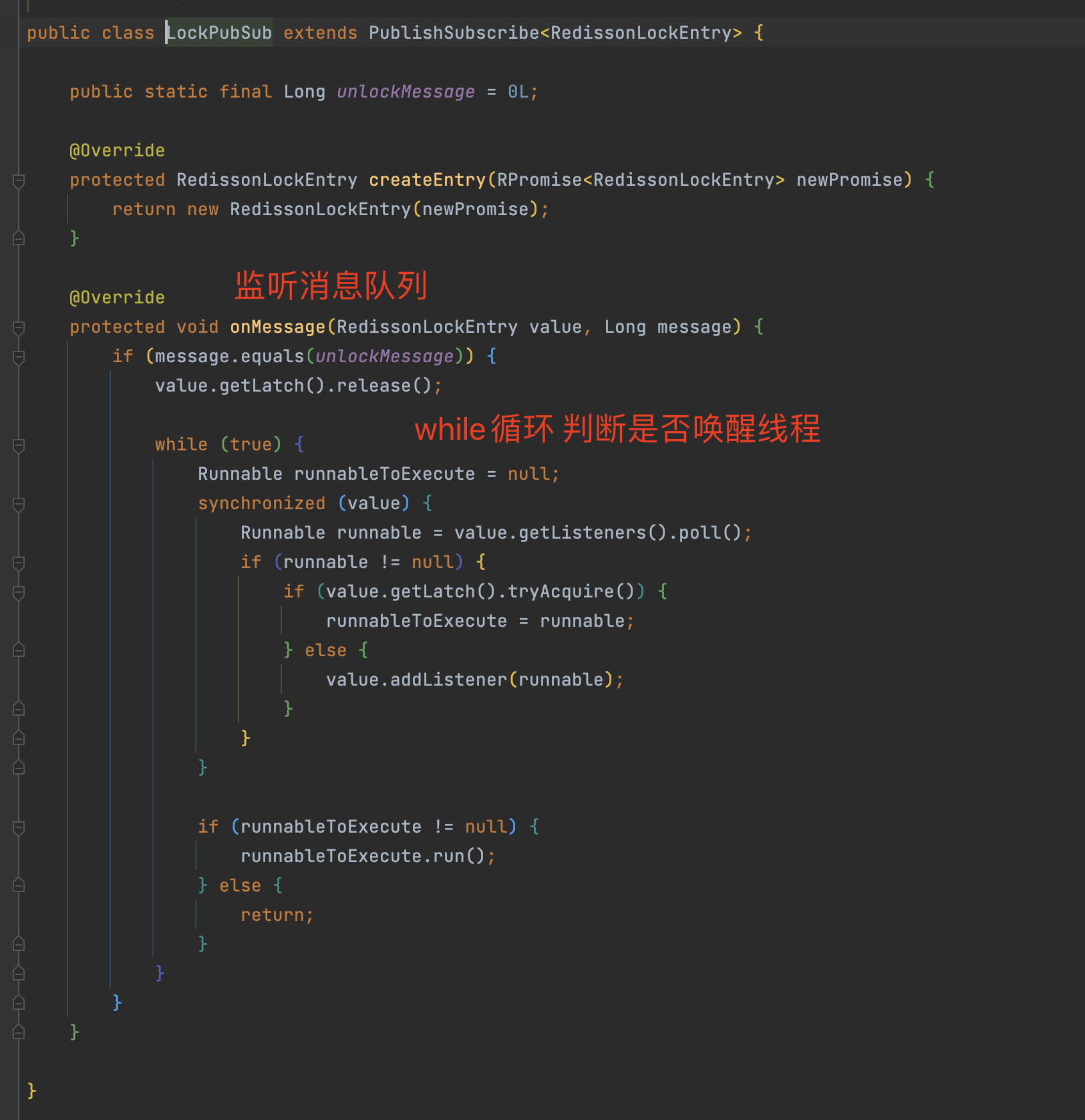
tryLock(不等待自循环加锁)
- tryLock该方法和while自循环加锁相反,tryLock没有看门狗的逻辑。
- 看门狗自循环机制:抢不到锁的线程会while自循环阻塞线程,而tryLock会在等待时间内(waitTime)尝试加锁,时间到期后还没有加锁成功直接返回false。


waitTime等待时间
- 在等待时间内,假设10秒钟,在10秒内还没有加锁成功,就会直接返回faluse,如果加锁成功就返回true
leaseTime 最长过期时间
- 如果加锁成功的话,leaseTime 就是最长的过期时间
分析源码

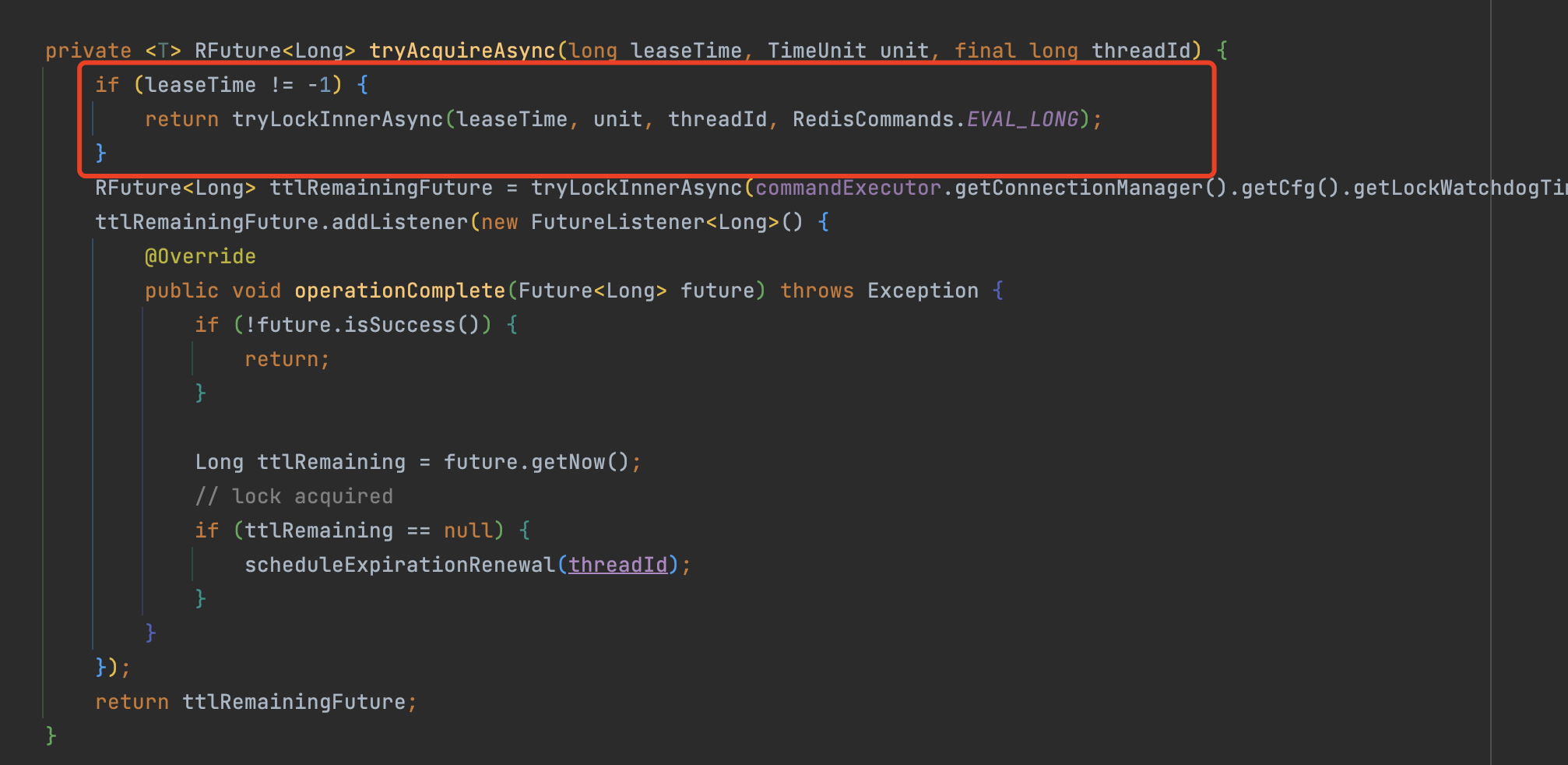
之前leaseTime 为1,所以就会走下面的逻辑(Future异步执行 看门狗LockWatchdogTimeout逻辑 ),但是tryLock 的leaseTime使我们传入的参数,该参数是加锁成功后的 最长过期时间,该值不可能是-1,所以不会走下面的看门狗逻辑(LockWatchdogTimeout)。
重入锁
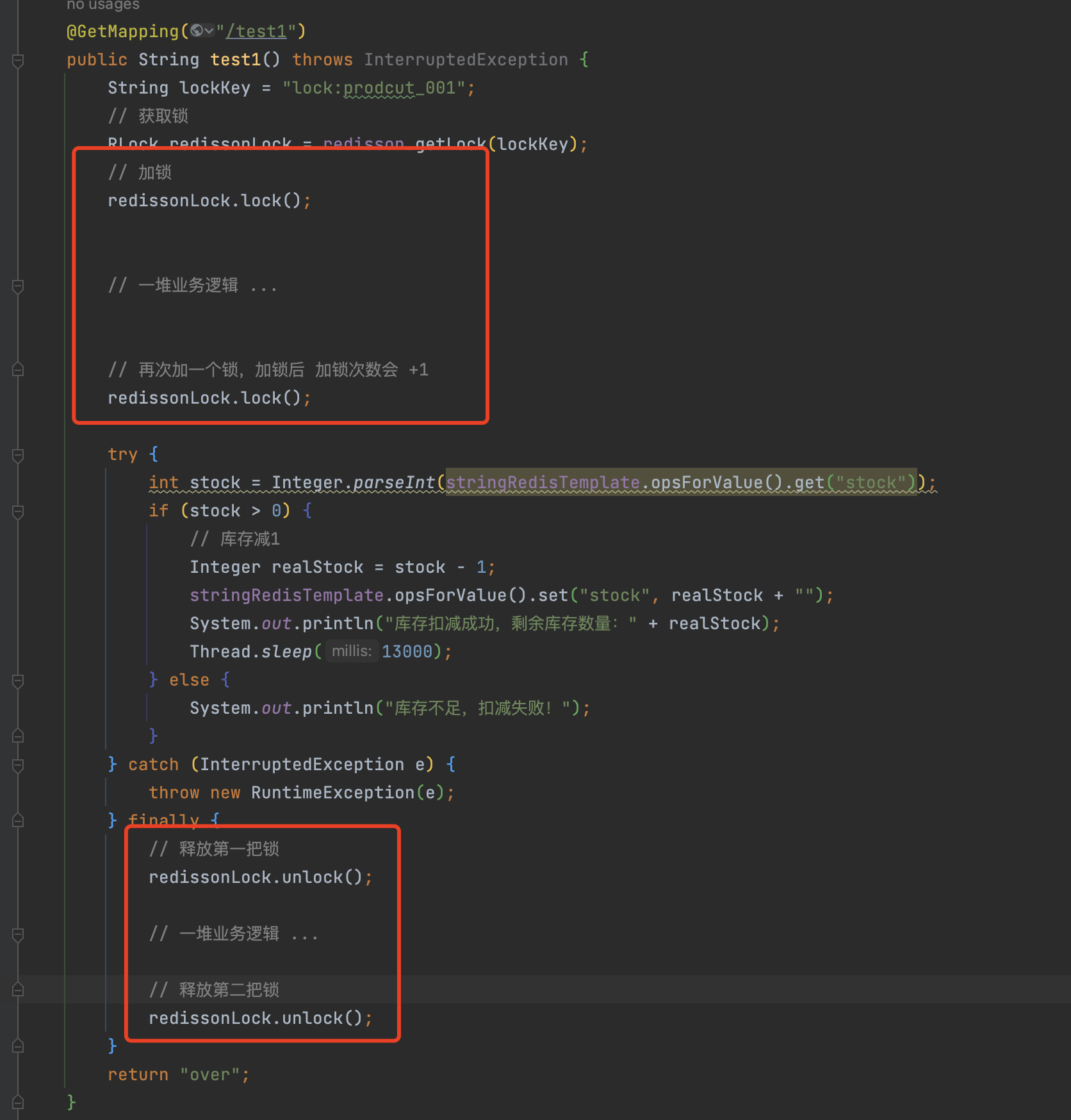
重入锁:在已经加锁的情况下,再次加一把锁,此时加锁的次数会从1变成2。
当我们释放锁时,需要对加锁次数减少1后,判断释放后的加锁次数是否小于0
- 如果小于0 则该线程的所有锁都释放成功就释放锁(删除key),并发送通知到redis channel,返回true
- 如果大于0则代表该线程重入锁过,线程还有其他的锁,就对该锁延长超时时间 并返回false
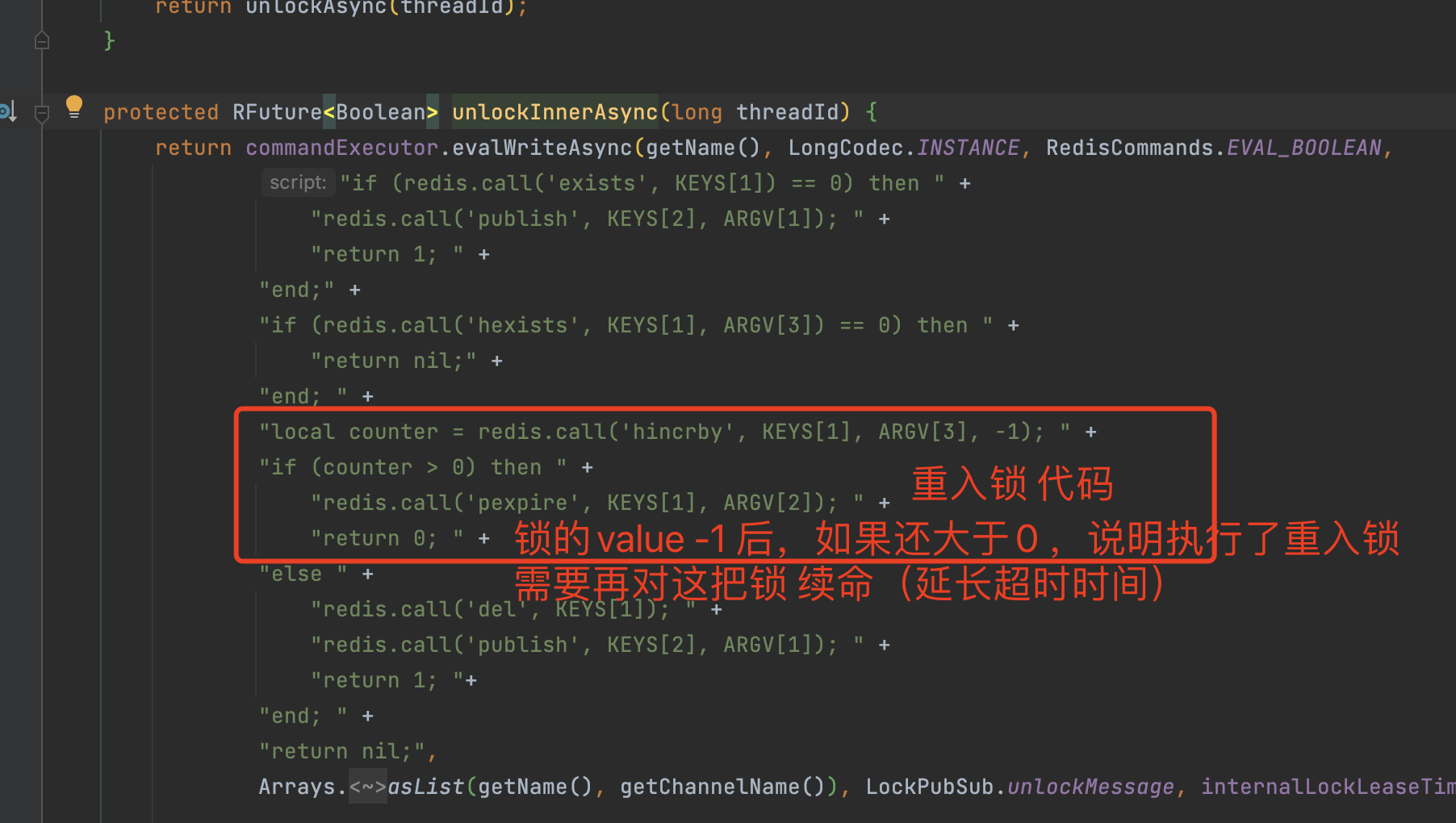
重入锁的场景非常少见,基本遇不到,所以不深究。
Redisson 主从架构下锁失效问题
出现锁失效的原因:
当线程1在master节点拿到锁后,master需要同步给slave,但是同步的过程中 master挂了(宕机),slave没有同步到这把锁。此时slave根据选举原则变成了master对外提供服务,此时新的master是没有线程1的锁的,线程2在来加锁肯定会加锁成功,这就会出现 锁失效的情况。
RedLock 红锁
网上有些文章描述 RedLock实现分布式锁可以解决主从切换时导致的分布式锁丢失问题,实际上RedLock并不能百分百解决该问题。
RedLock 原理
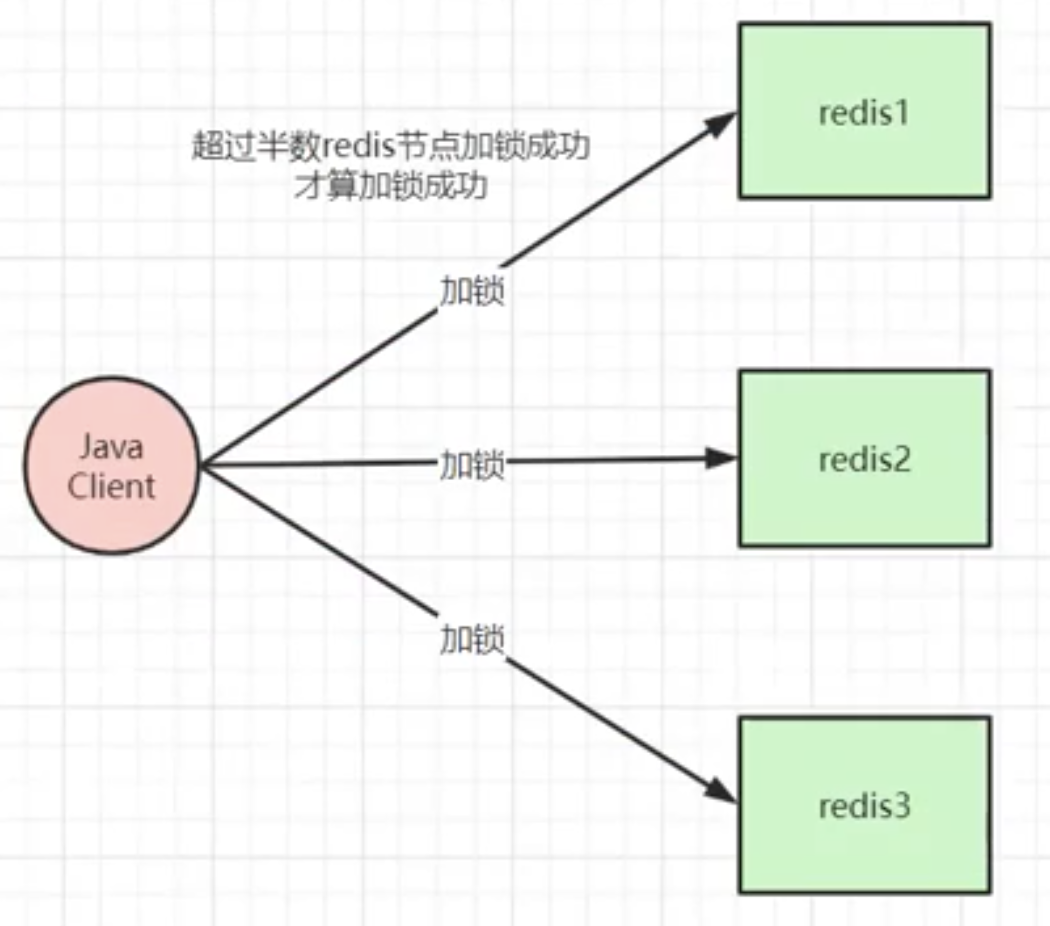
前置条件:我们需要准备至少3个以上的redis节点,节点与节点之前是没有任何关系的,如 主从,集群关系,就是纯粹的3台redis节点。
client进行加锁时,client会往所有个redis节点 都写入数据(加锁),必须超过半数节点加锁成功,client才认为加锁成功。
该方案相较于 普通的分布式锁,性能比较差,但是安全性更高,但也不是百分百解决了 分布式锁丢失问题。
RedLock 存在的问题(1)
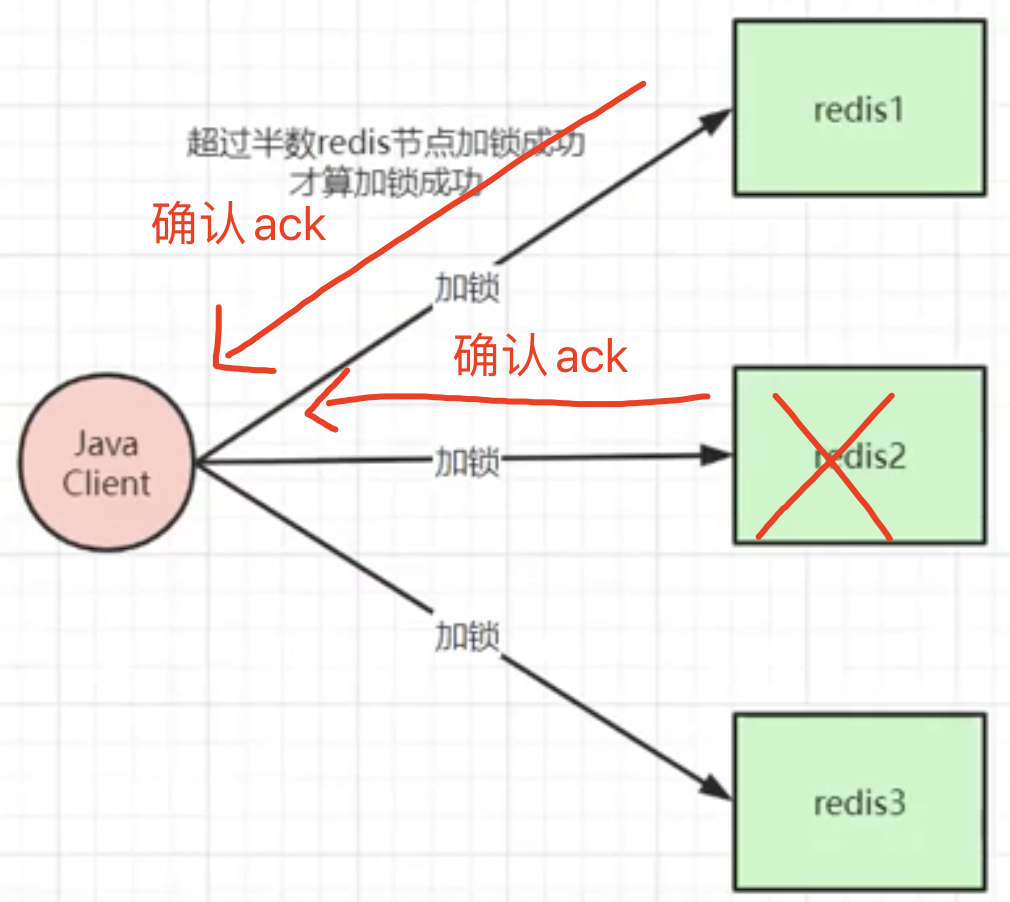
如图所示,client发送加锁命令给redis1,redis1 返回ack,client也发送加锁命令给redis2,redis2 返回ack后,client收到的ack已经超过半数了,认为加锁成功,但是redis2还没有来得及持久化就重启了,重启之后redis2是不存在这个锁的记录的。
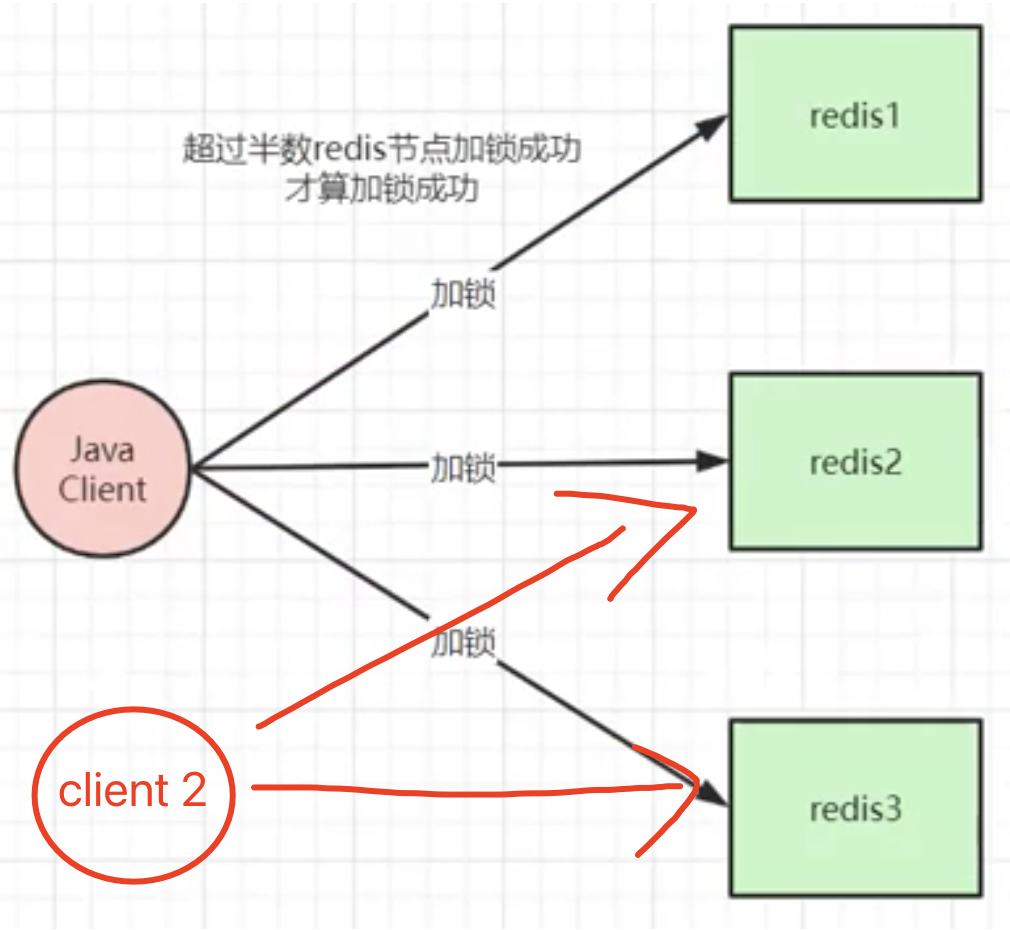
此时 client2 在对redis2和redis2进行加锁,是可以加锁成功的。因为redis2和redis3 都没有该锁的记录,并且client2 收到了超过一半以上的ack,就认为加锁成功。
RedLock 存在的问题(2)
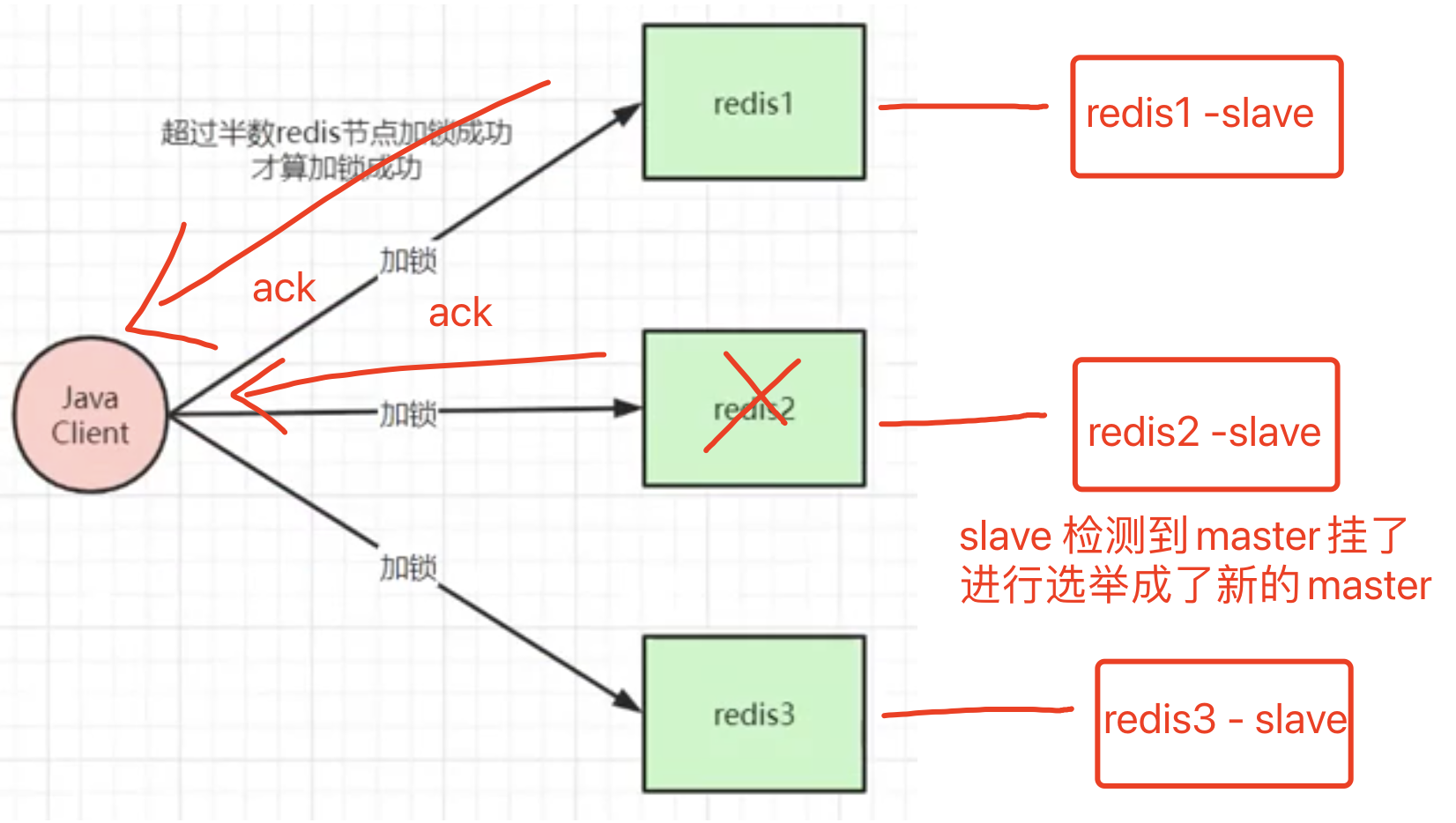
如图所示,client发送加锁命令给redis1,redis1 返回ack,client也发送加锁命令给redis2,redis2 返回ack后,client收到的ack已经超过半数了,认为加锁成功,但是redis2还没有来得及同步给slave后就挂了,slave通过选举成了新的master,但是新的master并没有client1 的锁。
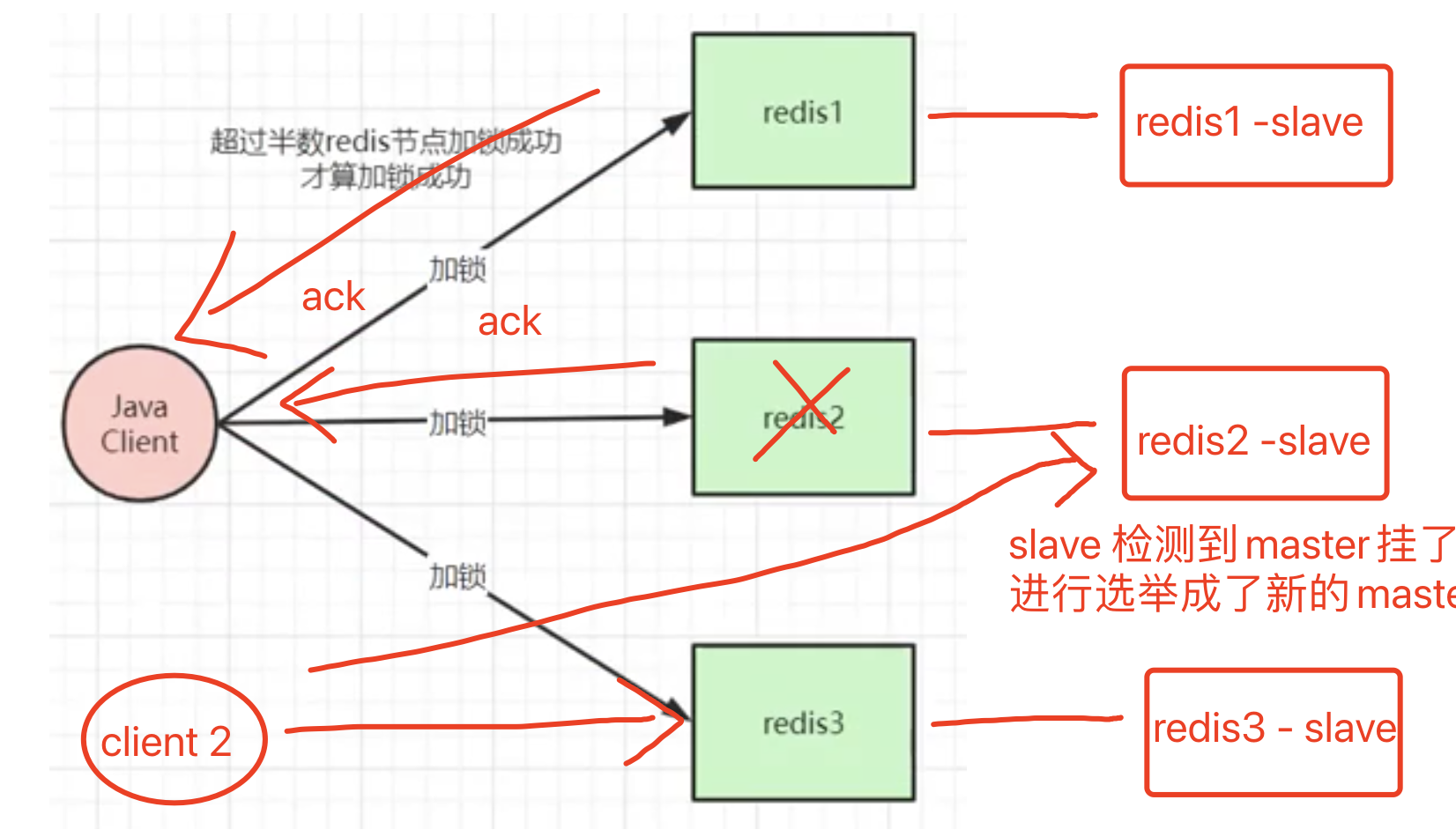
此时如果client 2 对新的master进行加锁操作,新的master是会返回ack的,因为他本地并没有这把锁的记录。redis3 也会返回ack,那么client2 收到了超出一半的ack,就认为加锁成功。
Redis 分布式锁优化 - 分段锁
redis分布式锁核心思想:由于redis是单线程模型,所有多线程请求会变成单线程串行化执行。
但是这是有些违背 高并发、高性能初衷的,哪怕redis确实性能很高,基于这点我们需要单独对redis分布锁进行优化,经过优化后性能可以无限的提升,可以是十倍、百倍、千倍,取决于你要拆分成多少个小key。

前置条件:商品ID 10001,分布式锁key:product_10001_stock 库存:800
优化思路:
- 将一个key 拆分成多个小key,把总库存分配到小key里面
- 做一个分段锁池,把这些key都存入池子中,当多线程并发访问时,我们进行轮询、权重、随机 等多种方式(看你需求)获取池子中的key,并进行库存的业务逻辑。
优点:我们把原本的一个锁拆分成了多个锁,当接口收到高并发请求时,其他线程就不需要等待同一个锁,也不需要去争夺同一个锁,有些类似于《MySQL索引底层结构及索引优化实战》中,我提到的一个细节:写热点分散。




