Redis持久化和主从架构、哨兵模式
Redis持久化
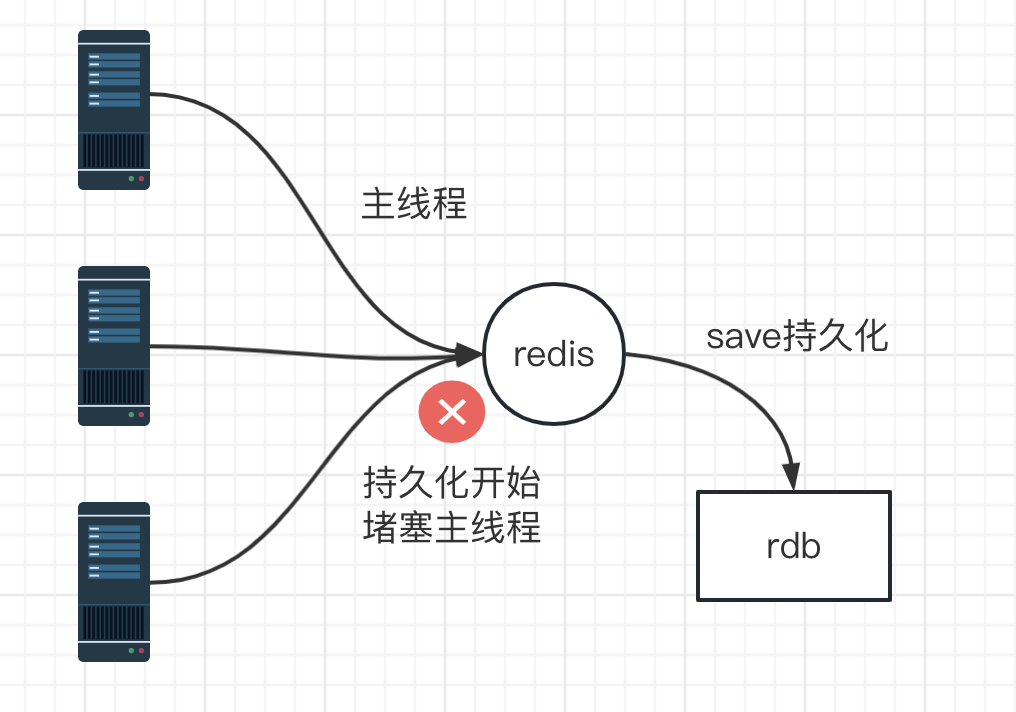
注意:redis单节点的内存建议小于10G,如果内存太大的话,在redis进行持久化和数据同步(主从)时,会给主节点造成很大的压力。
RDB快照(snapshot)
默认情况下,redis会根据策略将内存中的数据生成快照保存在名为 dump.rdb 的二进制文件存于磁盘中。
save 同步保存
save策略:
save 60 10000 // 60秒内有10000次操作,就会触发持久化
缺点:save持久化的模式是同步IO,在持久化的过程中会阻塞线程(主线程),在持久化没有完成之前,redis是无法处理客户端请求。
1 | // 读取redis的配置文件 |
bgsave的写时复制(COW)机制
redis借助操作系统提供的 写时复制技术(Copy-On-Write),在生成快照的时候依然可以正常处理客户端请求。
bgsave执行原理
- redis开始持久化时,会从主线程fork生成bgsave子线程,子线程可以共享主线程所有内存数据,bgsave子线程运行后会读取主线程的内存数据,并存入RBD文件中。
- 由于是子线程在进行持久化,所以不会阻塞到主线程,主线程可以正常处理客户端的读写命令。
- 由于主、子线程内存数据是共享的,如果开始持久化(或持久化没结束),主线程修改了数据,子线程会把最新数据更新到RDB。
save和bgsave对比
| 命令 | Save | bgSave |
|---|---|---|
| IO类型 | 同步 | 异步 |
| 是否阻塞redis其他命令 | 是 | 否 |
| 复杂度 | O(n) | O(n) |
| 优点 | 不会消耗额外内存 | 不阻塞客户端命令 |
| 缺点 | 阻塞客户端命令 | 需要fork子线程,会消耗内存 |
RDB缺点
RDB持久化根据策略触发,如果在还没触发策略之前,写入等操作没来得及保存,服务器宕机了,就会造成部分数据丢失。
如策略:save 300 10 // 300秒内有10次操作,就会触发持久化 ,我们在300秒内只写入了5个数据,没有达到持久化触发策略,此时如果服务器突然宕机、重启,这部分的数据就会丢失。
AOF(append-only file)
因为RDB在未触发策略之前,如果宕机的话,可能丢失大量数据的风险,为此redis在1.1版本后推出了AOF持久化机制。
AOF持久化:将修改的每一条指令记录进文件appendonly.aof中(先写入os cache,每隔一段时间fsync到磁盘) 。
fsync:将内存中修改的数据同步到磁盘文件。
开启AOF
1 | vim /www/server/redis/redis.conf |

AOF文件
- AOF一般保存于redis目录底下的appendonlydir目录中,以.aof结尾的文件
1 | SELECT |
这是一种resp协议格式数据,星号后面的数字代表命令有多少个参数,$号后面的数字代表这个参数有几个字符
注意,如果执行带过期时间的set命令,aof文件里记录的是并不是执行的原始命令,而是记录key过期的 时间戳
AOF持久化演示
当我们开启AOF后,在redis进行修改操作,就会追加写入到AOF文件中。
当redis重启后,redis会读取aof文件的数据达到重建加载数据库的目的。

配置持久化时间
我们可在redis配置文件中,配置redis数据多久执行一次持久化(fsync),推荐每秒fsync一次,性价比较高。
appendfsync always
- 每次有新命令追加到 AOF 文件时就执行一次 fsync ,非常慢,也非常安全。
appendfsync everysec(推荐)
- 每秒 fsync 一次,足够快,并且在故障时只会丢失 1 秒钟的数据。
appendfsync no
- 从不 fsync ,将数据交给操作系统来处理。更快,也更不安全的选择。
AOF重写
- 清空aof文件的记录,并将当前的内存数据 转化成RESP命令写入aof文件
AOF文件类似于操作历史记录,如果我们进行原子自增 incr count ,自增5次,那么aof文件也会记录5次incr count 的操作,redis在重启恢复数据时 也会执行5次 incr count 的操作,这明显是不合理的,为什么不直接set count 5 呢?
1 | 127.0.0.1:6379> incr count |
为此,我们就引出了redis的一个高级机制 AOF重写,AOF会根据AOF文件大小进行数据重写, 重写时会fork出子线程去执行(类似于 bgsave), 不会影响主线程的操作。
数据重写
- 根据aof文件进行推算,推算后的结果 重新写入aof文件
如上面的例子,执行了5次原子自增,数据重写后 AOF文件则变成(set count 5):
1 | *3 |
重写配置
1 | auto-aof-rewrite-percentage 100 //aof文件自上一次重写后文件大小增长了100%(64 * 2 -> 128)则再次触发重写 |
aof文件大小达到限制后就会自动进行重写,当然我们也可以在redis中手动重写,命令:bgrewriteaof
RDB与AOF对比
| 命令 | RDB | |
|---|---|---|
| 启动优先级 | 低 | 高 |
| 文件体积 | 小 | 大 |
| 重启恢复速度 | 重启后恢复数据快 | 重启后恢复数据慢 |
| 数据安全性 | 容易丢失数据 | 不容易丢失数据 |
在生产环境中,RDB和AOF可以同时开启,如果同时开启,redis启动时会优先选择aof文件进行恢复,因为aof文件优先级高。
混合持久化(aof的功能)
如果redis启动重建数据库使用RDB,很容易丢失大量数据,如果使用aof 恢复速度又很慢,尤其是redis数据量大的时候,启动需要很长的时间。
redis 4.0 为了解决该问题,带来了一个新的选项:混合持久化。
持久化原理
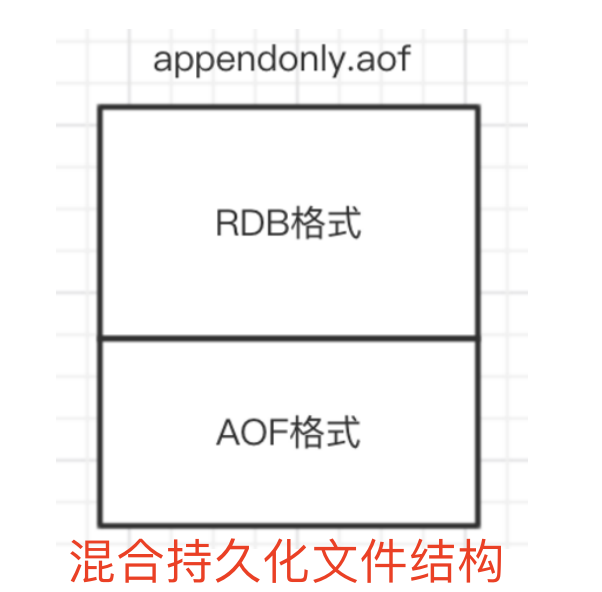
如果开启了混合持久化,aof在重写时就不在将 内存数据转化成RESP命令写入aof文件,而是将 重写时的内存数据打包成RDB快照,存入aof文件。如果重写后有新的修改操作,会追加到aof文件,和之前的二进制快照数据存在一起。
注意:混合持久化本质上基于aof,是aof的重写模块的升级版。
开启混合持久化
1 | vim /www/server/redis/redis.conf |
redis 7.0的混合持久化
redis 7.0相较于redis 4.0 在混合持久化上做了升级,4.0 会把快照和修改操作的指令都一起存在aof文件中,但是7.0把rdb快照单独存储在一个文件中,aof单独存于appendonly.aof文件,把他们2个区分开了。
redis 7.0的混合持久化实验
- 当我们重写aof时,会清空aof文件并将重写时当前内存数据做成rdb快照存于rdb文件中。
redis数据备份与恢复

备份:备份redis目录底下的rdb和aof文件即可。
恢复:把rdb和aof文件放到redis目录底下,然后重启redis服务,就可以把rdb和aof中的数据恢复到内存数据库。
关于备份策略需要注意的是,应当根据生产环境指定一个属于自己的备份策略,
如:写crontab定时调度脚本,每小时都copy一份rdb和aof的备份并同步到 远程文件服务器(仅仅保留最近48小时的备份 )
Info命令查看redis信息
Redis主从架构
为了缓解了单机的读请求压力,提升整个redis的读QPS,我们可以通过 一主多从的读写分离架构来实现,一台机器作为master主机,其他机器作为slave从机,从机会从主机同步数据。
为了确保数据一致性,主机(master)只负责事务性操作(增删改),从机(slave)只负责读操作。
配置主从架构
实验视频:https://xing-video.oss-cn-hangzhou.aliyuncs.com/redis%E4%B8%BB%E4%BB%8E%E6%9E%B6%E6%9E%84.mp4
1 | // 1、修改redis.conf |
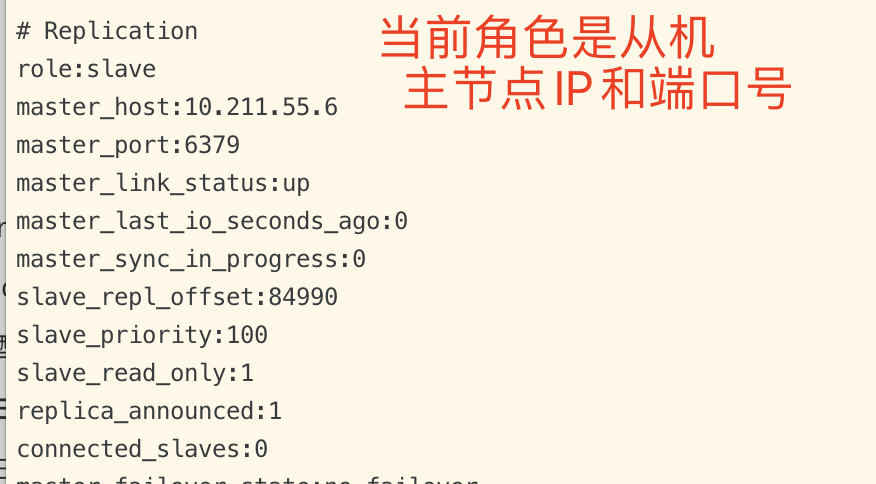
主从复制(全量复制)
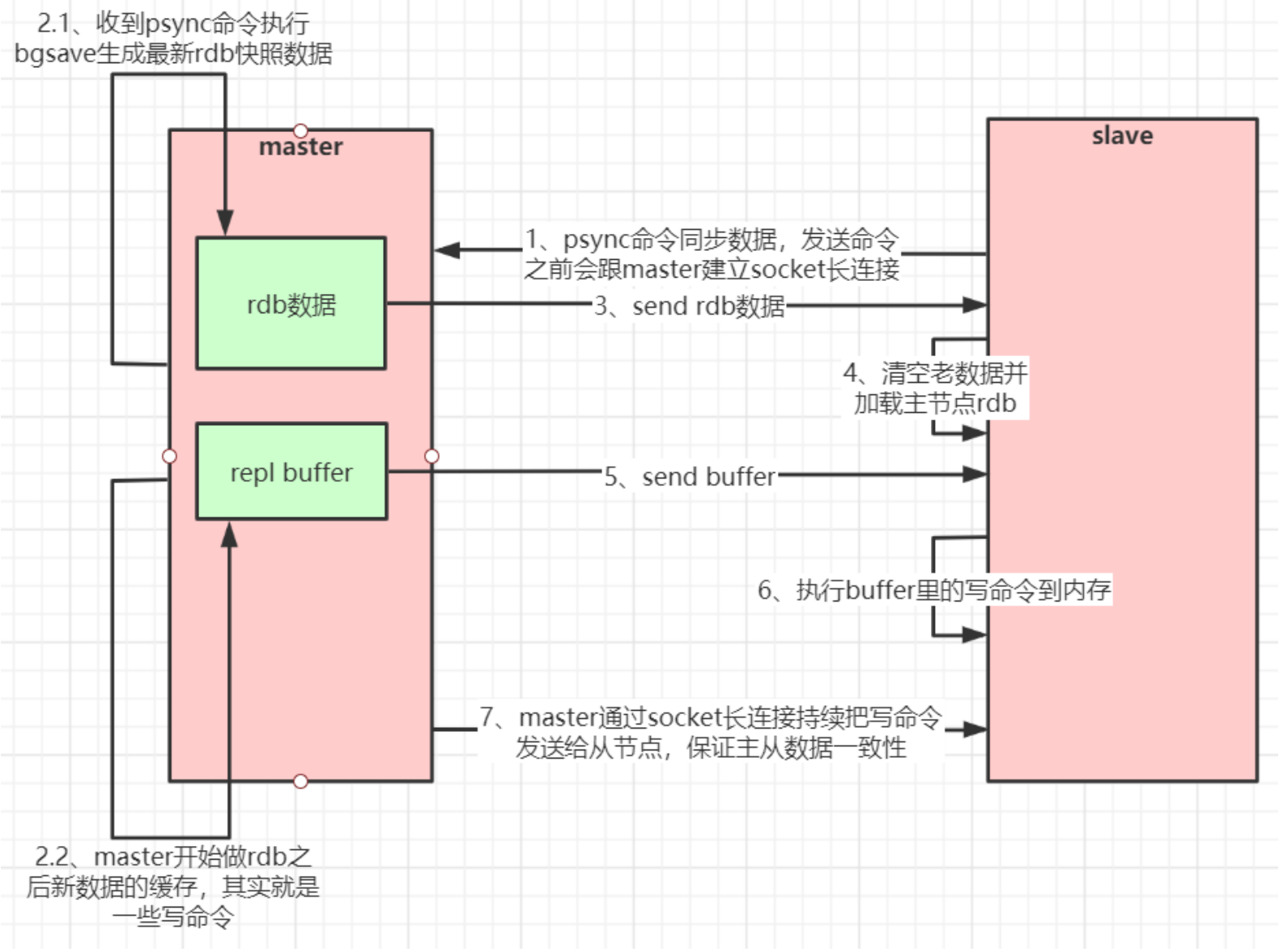
- 如果你为master配置了一个slave,不管这个slave是否是第一次连接上Master,它都会发送一个PSYNC 命令给master请求复制数据。
- master收到PSYNC命令后,会在后台进行数据持久化通过bgsave生成最新的rdb快照文件,持久化期间,master会继续接收客户端的请求,它会把这些可能修改数据集的请求缓存在内存(repl buffer)中。当持久化进行完毕以后,master会把这份rdb文件数据集发送给slave
- slave会把接收到的数据进行持久化生成rdb,然后再加载到内存中。然后master再将之前缓存在内存(repl buffer)中的命令发送给slave。
- slave收到repl buffer中的命令后,进行增量更新
注意:当master与slave之间的连接由于某些原因而断开时,slave能够自动重连Master,如果master收到了多个slave并发连接请求,它只会进行一次持久化,而不是一个连接一次,然后再把这一份持久化的数据发送 给多个并发连接的slave。
主从复制(部分复制,断点续传)
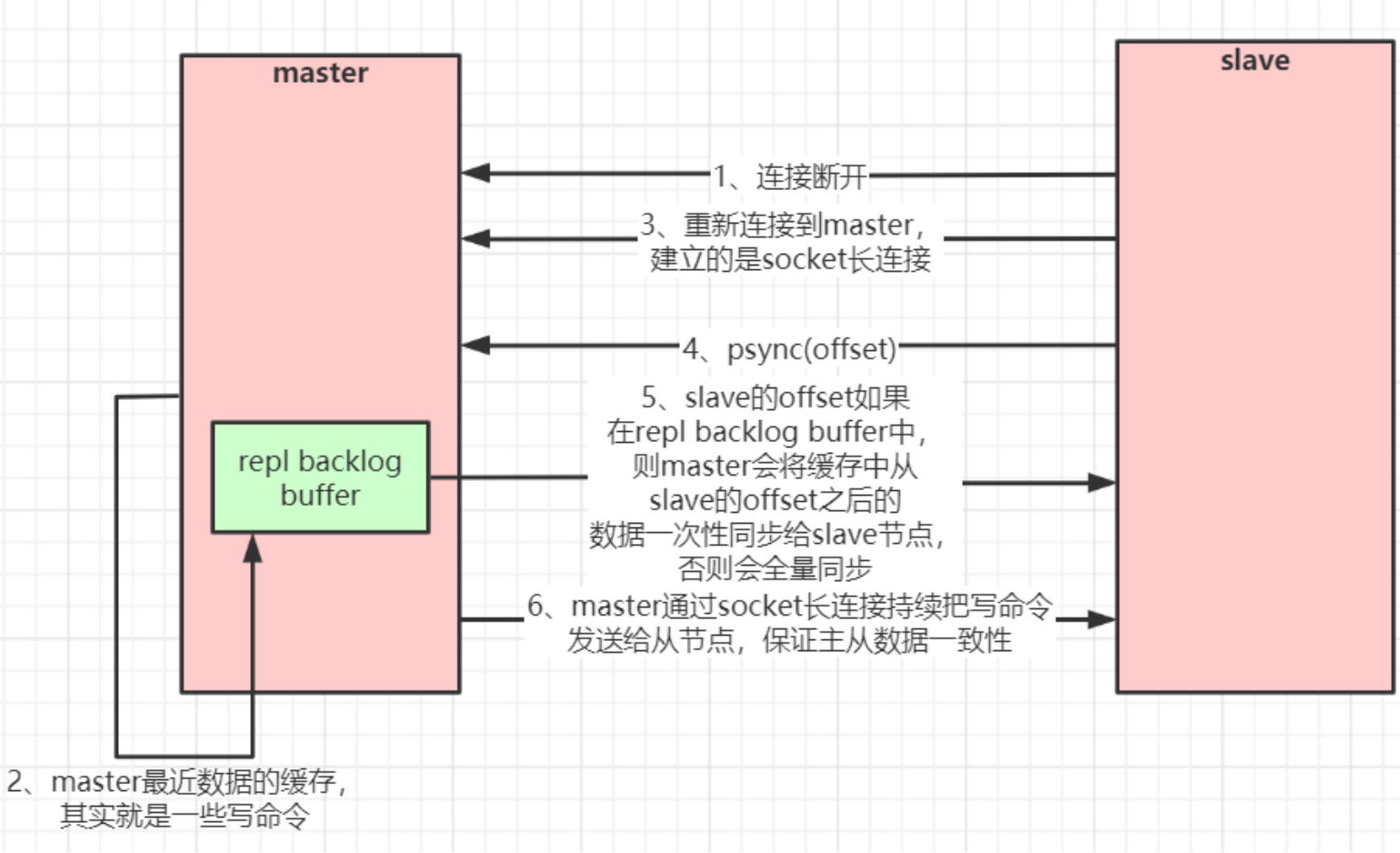
问:如果slave挂掉一段时间后再连上了master,slave中的数据肯定和master不一致。那么slave该如何同步master的数据呢?
- master发送给slave的数据,每条命令都会有一个offset偏移量,slave取出他最后一次同步的命令对应的偏移量,把偏移量发送给master
- master会拿这个偏移量到repl buffer(缓存区)去找,如果能找得到该偏移量对应的命令,就会从该命令之后的所有命令一次性同步给slave节点
- 因为repl buffer内存空间有限,只会保存1MB的命令,如果repl buffer找不到的话意味着slave宕机太久了,则会执行bgsave生成rdb快照后进行全量同步
- master通过socket持续把操作命令同步给从节点
repl buffer是先进先出的队列,默认为1MB,如果缓存不够会将最新写入的命令删除,会一直保持最新1MB左右大小的命令。
repl buffer只有在2种情况下会起到作用
- master在进行全量同步时,刚好有客户端发起新的修改命令进来,临时存储在 repl buffer,等待RDB全量同步完成后,master在把repl buffer的命令一次性同步给slave
- slave宕机后重连,slave的最后一条命令的偏移量可以在repl buffer中找到,才会使用到repl buffer进行增量同步(断点续传)
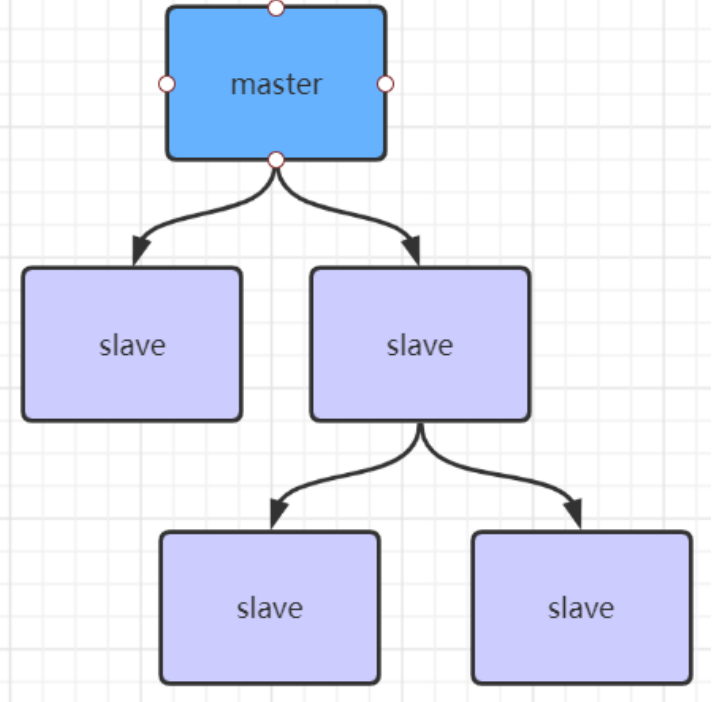
主从复制风暴
- 主底下有很多从节点,从节点同时去复制(同步)主节点的数据,导致主节点压力过大,就会造成主从复制风暴。
如果有很多从节点,为了缓解主从复制风暴(多个从节点同时复制主节点导致主节点压力过大),可以做如下架构,让部分从节点与从节点(与主节点同步)同步数据
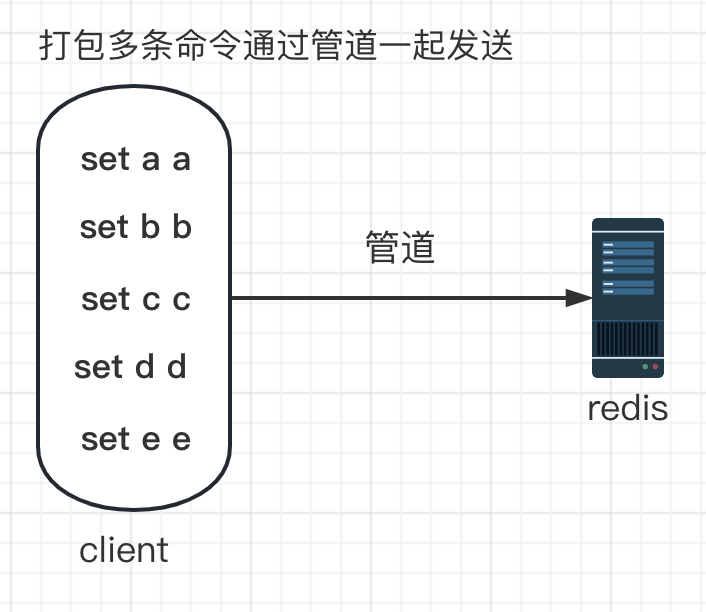
管道(Pipeline)
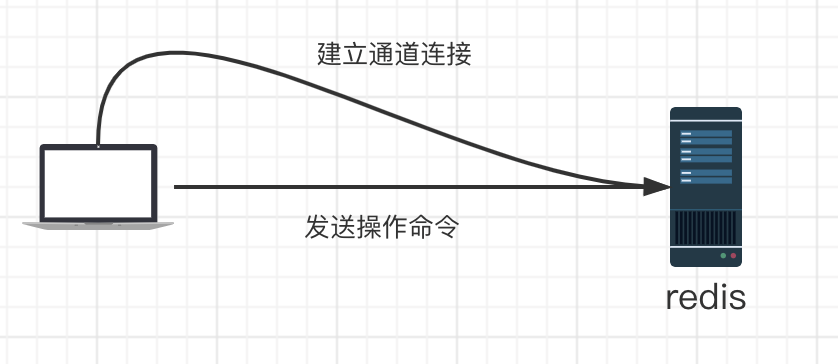
客户端连接redis服务器:
- 客户端根据redis进行tcp 三次握手建立通道连接
- 客户端发送操作命令给redis
- redis处理完全部的命令后,一次性返回客户端
- pipeline 中每条命令都会被执行,如果执行失败就会记录失败信息,然后跳过该命令 执行下一条命令
- redis处理完所有命令前会先缓存起所有命令的处理结果,等到处理完之后一次性返回给客户端
- 收到打包的命令越多,redis越消耗内存,并不是打包的命令越多越好
客户端建立通道连接和发送操作命令 需要耗费时间(网络开销),这个耗费的时间远比 redis服务器执行命令的时间要长。
如果我们需要一次性执行多条命令,可以通过管道一次性发送多条命令,发送完成后再一次性读取服务器响应,只消耗了一次网络开销。
优点:降低了传输多条命令的网络开销和连接redis服务器的开销。
Redis哨兵模式
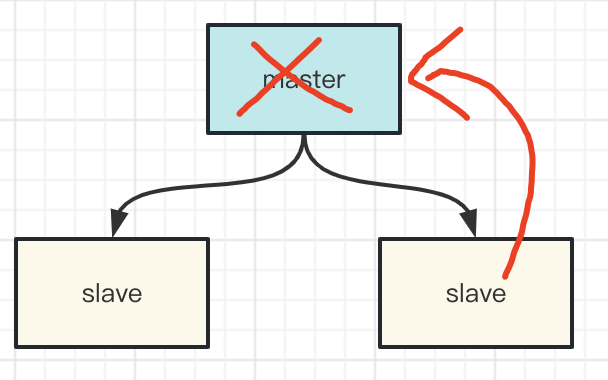
对于单纯的主从架构,如果master宕机,我们需要手动启用slave来替代master的工作,然后让其他的slave去同步新的master的数据。
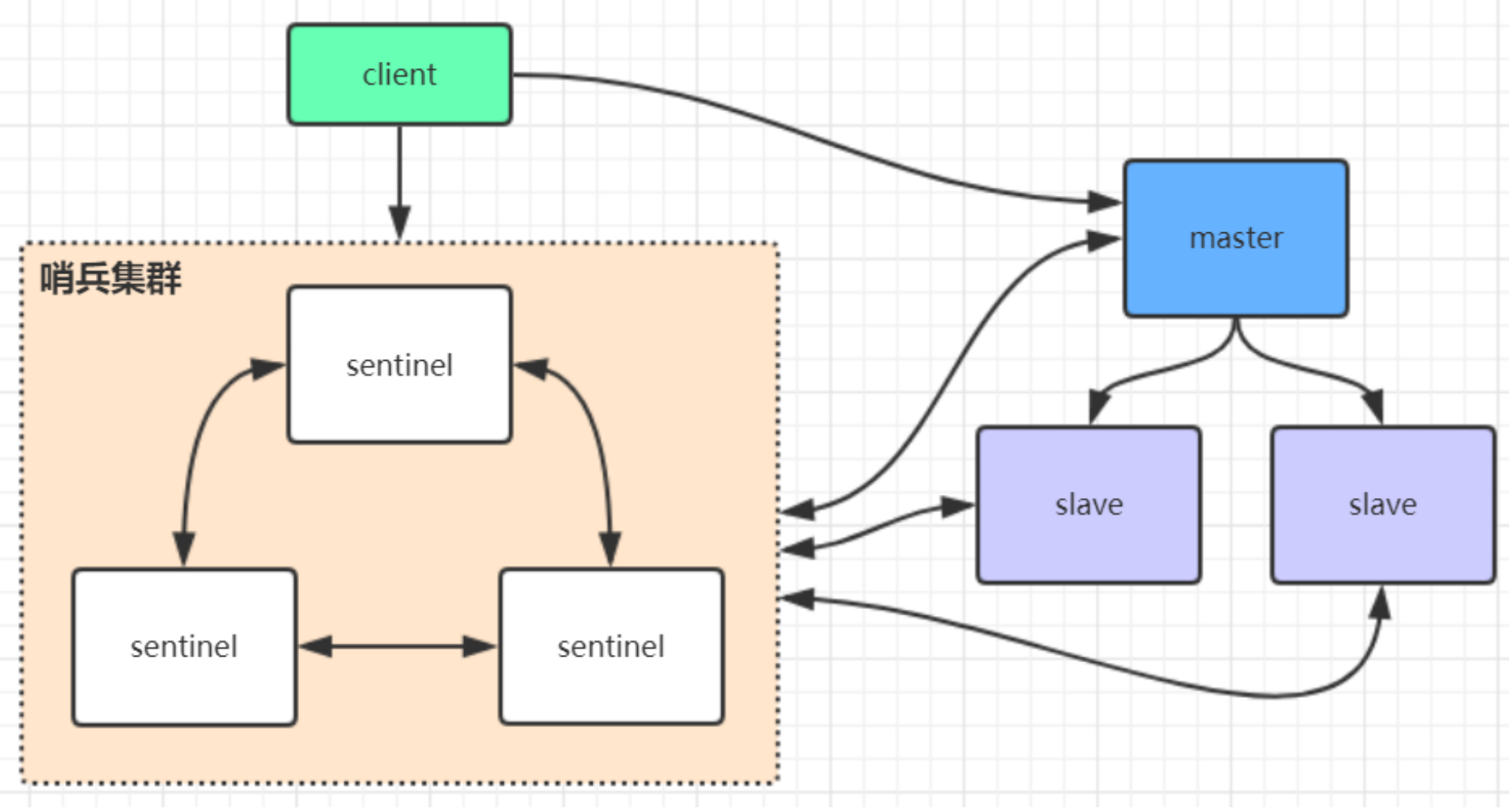
sentinel哨兵不提供读写服务,主要用来监控redis实例节点,当master宕机后,sentinel会自动从slave集群中选举出新的master
哨兵工作原理
哨兵模式搭建
1 | // 1、在redis源码目录复制sentinel.conf |
info信息
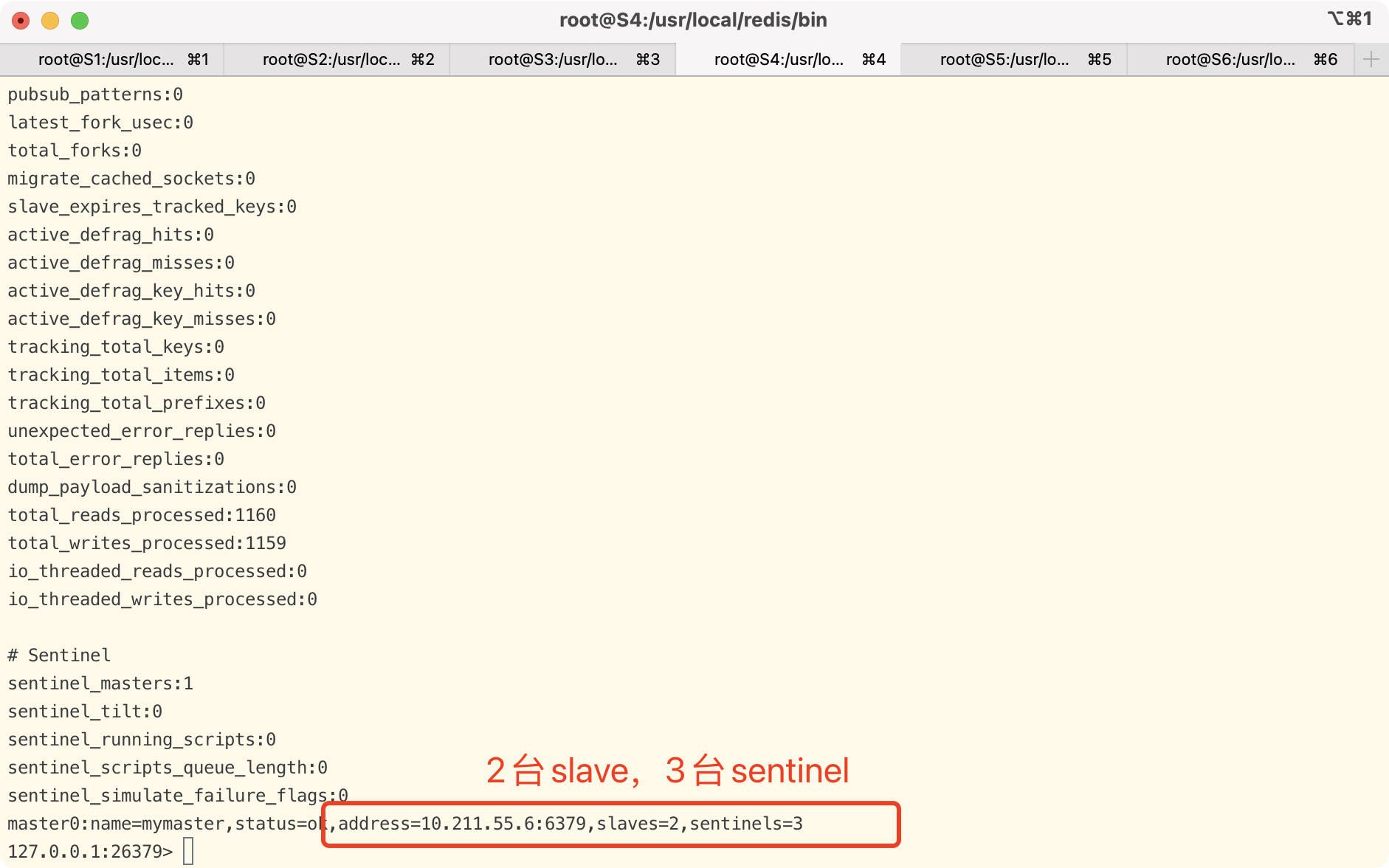
查看哨兵和slave从节点信息
当sentinel集群启动完毕后,会将哨兵集群的信息和slave从节点信息写入到sentinel.conf 中。
vim sentinel.conf
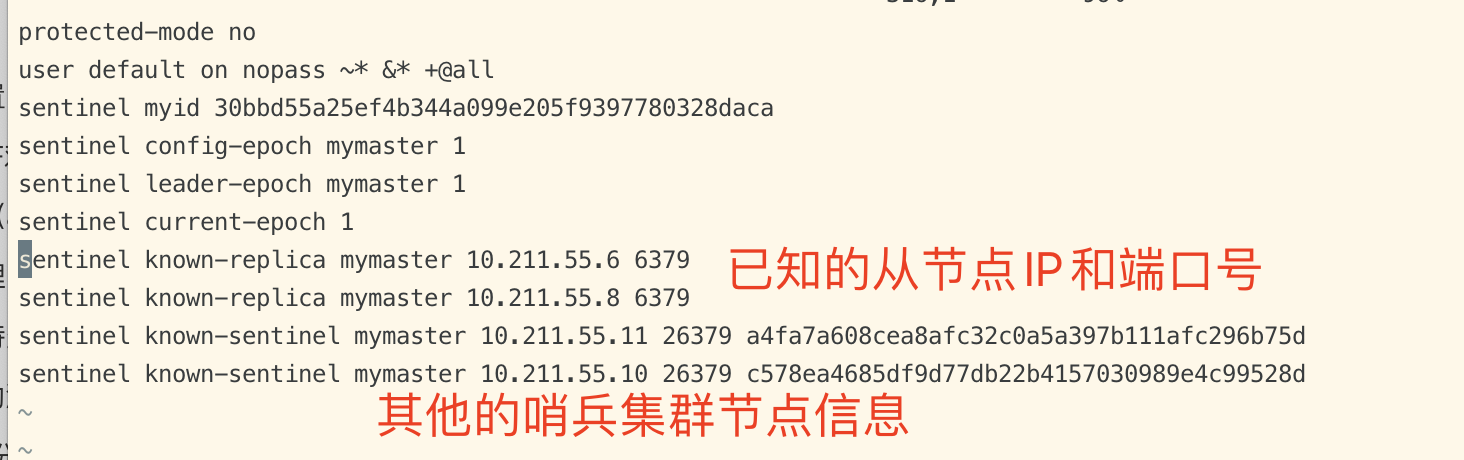
注意:这里写入的信息是slave从节点信息和哨兵集群的节点信息(不包含当前机器)。
如果当你master节点挂了,哨兵选举slave称为新的master节点后,这里的信息也会跟着变动,这里只会保留 最新的slave从节点信息。
哨兵选举实验
结论:
client连接上哨兵后第一次会获取到master主节点信息并会订阅哨兵的通知,当主节点挂掉后,哨兵会重新选举出新的master节点并通过订阅的方式推送client,告知最新的master信息,client收到后会动态切换master主节点信息。
为了演示哨兵选举过程,接下来我们在springboot中执行一段while循环写入redis的命令。然后把主节点给他kill掉,看看哨兵模式 是否正常在从机中选举出主机。
Pom.xml:
1 | <dependency> |
yaml:
1 | server: |
controller:
1 | @RestController |
1、访问controller,正常开始存储:

kill主节点
kill后,主节点已经挂掉了,while循环set到redis的方法会一直报错,连接失败。

3、sentinel检测到主节点挂掉,从slave中选举主节点,选举成功后 推送订阅消息给客户端,告知客户端新的主节点信息。
客户端收到新的主节点后,替换掉旧的主节点信息,继续正常的写入数据

StringRedisTemplate详解
spring 封装了 RedisTemplate 对象来进行对redis的各种操作,它支持所有的 redis 原生的 api。在 RedisTemplate中提供了几个常用的接口方法的使用,分别是:
1 | private ValueOperations<K, V> valueOps; |
RedisTemplate中定义了对5种数据结构操作
1 | redisTemplate.opsForValue();//操作字符串 |
StringRedisTemplate继承自RedisTemplate,也一样拥有上面这些操作,唯一不同的区别是保存key和value的区别。
- StringRedisTemplate默认采用的是String的序列化策略(推荐), 保存的key和value都是采用String类型保存的。
- 使用StringRedisTemplate来保存key和value的话,我们在redis客户端可以直接看到key和value的值
- RedisTemplate默认采用的是JDK的序列化策略, **保存的key和value都是采用JDK序列化保存的。 **
- 这也是为什么我们通过redis客户端去访问RedisTemplate保存的数据,显示的都是0x778\0x878之类的数据。
Redis客户端命令对应的RedisTemplate中的方法列表:
| String类型结构 | |
|---|---|
| Redis | RedisTemplate rt |
| set key value | rt.opsForValue().set(“key”,”value”) |
| get key | rt.opsForValue().get(“key”) |
| del key | rt.delete(“key”) |
| strlen key | rt.opsForValue().size(“key”) |
| getset key value | rt.opsForValue().getAndSet(“key”,”value”) |
| getrange key start end | rt.opsForValue().get(“key”,start,end) |
| append key value | rt.opsForValue().append(“key”,”value”) |
| Hash结构 | |
| hmset key field1 value1 field2 value2… | rt.opsForHash().putAll(“key”,map) //map是一个集合对象 |
| hset key field value | rt.opsForHash().put(“key”,”field”,”value”) |
| hexists key field | rt.opsForHash().hasKey(“key”,”field”) |
| hgetall key | rt.opsForHash().entries(“key”) //返回Map对象 |
| hvals key | rt.opsForHash().values(“key”) //返回List对象 |
| hkeys key | rt.opsForHash().keys(“key”) //返回List对象 |
| hmget key field1 field2… | rt.opsForHash().multiGet(“key”,keyList) |
| hsetnx key field value | rt.opsForHash().putIfAbsent(“key”,”field”,”value” |
| hdel key field1 field2 | rt.opsForHash().delete(“key”,”field1”,”field2”) |
| hget key field | rt.opsForHash().get(“key”,”field”) |
| List结构 | |
| lpush list node1 node2 node3… | rt.opsForList().leftPush(“list”,”node”) |
| rt.opsForList().leftPushAll(“list”,list) //list是集合对象 | |
| rpush list node1 node2 node3… | rt.opsForList().rightPush(“list”,”node”) |
| rt.opsForList().rightPushAll(“list”,list) //list是集合对象 | |
| lindex key index | rt.opsForList().index(“list”, index) |
| llen key | rt.opsForList().size(“key”) |
| lpop key | rt.opsForList().leftPop(“key”) |
| rpop key | rt.opsForList().rightPop(“key”) |
| lpushx list node | rt.opsForList().leftPushIfPresent(“list”,”node”) |
| rpushx list node | rt.opsForList().rightPushIfPresent(“list”,”node”) |
| lrange list start end | rt.opsForList().range(“list”,start,end) |
| lrem list count value | rt.opsForList().remove(“list”,count,”value”) |
| lset key index value | rt.opsForList().set(“list”,index,”value”) |
| Set结构 | |
| sadd key member1 member2… | rt.boundSetOps(“key”).add(“member1”,”member2”,…) |
| rt.opsForSet().add(“key”, set) //set是一个集合对象 | |
| scard key | rt.opsForSet().size(“key”) |
| sidff key1 key2 | rt.opsForSet().difference(“key1”,”key2”) //返回一个集合对象 |
| sinter key1 key2 | rt.opsForSet().intersect(“key1”,”key2”)//同上 |
| sunion key1 key2 | rt.opsForSet().union(“key1”,”key2”)//同上 |
| sdiffstore des key1 key2 | rt.opsForSet().differenceAndStore(“key1”,”key2”,”des”) |
| sinter des key1 key2 | rt.opsForSet().intersectAndStore(“key1”,”key2”,”des”) |
| sunionstore des key1 key2 | rt.opsForSet().unionAndStore(“key1”,”key2”,”des”) |
| sismember key member | rt.opsForSet().isMember(“key”,”member”) |
| smembers key | rt.opsForSet().members(“key”) |
| spop key | rt.opsForSet().pop(“key”) |
| srandmember key count | rt.opsForSet().randomMember(“key”,count) |
| srem key member1 member2… | rt.opsForSet().remove(“key”,”member1”,”member2”,…) |




