MySQL数据库优化详解
导读
1)数据库优化的好处
- 优化SQL查询效率
- 提高SQL的查询效率,提升用户使用体验,提高MySQL性能(减少磁盘IO,减少CPU占用)
- 解决慢查询导致连接超时无法正常返回和阻塞锁表问题
- 提高数据库稳定性
- 随着数据量越来越大,如果没有对其进行优化,SQL执行效率会越来越低
2)优化层面

优化趋势:越往上效果越低,成本越高;反之越往下,效果越好;
注意:
- 如果硬件和IOS系统一旦确定,单机MySQL就一定会存在性能上限
- IOPS
- 每秒处理 I/O 的请求次数,一般:每秒支持 读2000次,写600Q次
- QPS
- 每秒请求、查询次数,一般:每秒支持 3500-4500QPS
- TPS
- 每秒事务产生(增删改),一般:每秒支持 261次
- 我们只能在该上限之下进行一定的优化(SQL、索引),争取达到最大上限
- 可通过 系统架构 进行优化,提升MySQL的性能,不在受制于 单机MySQL性能限制
- 如 读写分类,主从复制,分库分表等
商业需求(业务开发需求)
- 不合理需求的开发 造成性能降低
- 对于不合理的需求,应当好好评估
- 无用功能堆积 导致系统过于复杂影响整体性能
系统架构
数据库中存放的数据仅适合 字符串
- 不适合的类型
- 多媒体文件,二进制文件
- 一般存放于 三方的存储服务器,如 阿里云、七牛云等
- 消息队列
- 一般使用第三方如MQ 消息队列
- 超大文本数据
对于一些变化较小并且经常访问的数据
我们存放于 Cache缓存(内存)或者Redis(内存)
系统配置数据
用户的基本数据
SQL及索引优化
数据库SQL优化分为:SQL优化和索引优化,我们通过这2个角度去优化SQL,可以有效的提高SQL的一个执行效率。
在优化的过程中,会通过慢日志查询找出慢SQL并使用Explain SQL执行计划来分析SQL的执行效率,并且针对性的进行优化。
- 合理设计并利用索引,优化SQL查询效率
- 一个表尽量使用2-5个联合索引覆盖80%的SQL查询
数据库表结构优化
- 根据数据库的范式(规范)设计表结构,表结构的好坏直接关系到SQL的复杂程度
- 适当的进行表拆分,不要过于拆分表结构,适当做冗余字段,很可能原本需要做join的查询只需要单表查询即可
系统配置优化
- 在Linux机器上可以进行配置优化,如TCP连接数,安全性等限制
硬件配置优化
- 数据库IO性能是最优先考虑的因素
- 数据库主机CPU处理能力是次考虑因素
- 数据库主机的网卡性能也可能会成为系统瓶颈
慢查询日志分析
慢查询日志是 MySQL 提供的日志记录,用来记录所有的慢 SQL 语句,通过分析 慢查询日志,我们可以精准的定位出 查询效率低下的SQL,然后针对性的进行SQL优化。
- 检查慢查询状态和日志路径
show variables like '%slow_query_log%'
- 开启慢查询日志
set global slow_query_log = on;
- 慢查询日志判断标准
- 默认查询时间大于10s的sql语句
show variables like 'long_query_time'- 修改 慢查询判断时间(单位是秒)
set global set long_query_time=1
- 开启所有SQL语句记录日志(所有语句,不论执行快慢,慎用,最好别用)
set global log_queries_not_using_indexes=on
- 解析日志

- Query_time ,SQL执行时间,越长则越慢
- Lock_time,在MySq服务器阶段等待表锁时间
- 在查询和写入的时候,会锁表
- Rows_sent,查询返回的行数
- Rows_examined,查询检查的行数,越长越耗费时间
- 这个参数可以理解是中间结果集,查询的行数很多,但是真正返回的行数很少,则该sql效率非常低
- Set timestamp,设置时间戳,没有实际意义
- 第五行,后面则是执行sql语句信息
1)慢查询日志分析工具
工具:mysqldumpslow
- 如果开启了慢查询日志,会生成大量数据,我们可以通过对日志的分析生成分析报表,通过报表进行优化。
- 查询所有日志信息
mysqldumpslow --verbose /var/lib/mysql/myshop02-slow.log- ![mysqldumpslow工具][image-11]
- 查询日志 - 排序
mysqldumpslow --s /var/lib/mysql/myshop02-slow.log- al :平均锁定赶时间
- ar:平均返回行数
- at:平均查询时间
- c:语句执行总次数
- l:总表锁定时间
- r:总发送行数
- t:总查询时间
- 按总语句执行次数排序
mysqldumpslow -s c /var/lib/mysql/myshop02-slow.log
- 按总查询时间排序(按括号里面的总时间排序,最长的在最前面)
mysqldumpslow -s t /var/lib/mysql/myshop02-slow.log
- 按平均查询时间排序,且找出前5条
mysqldumpslow -s at -t 5 /var/lib/mysql/myshop02-slow.log
2)pt-query-digest(重点)
用于分析mysql慢查询的第三方工具,可以分析binlog、General log、slowlog。
分析过程:
- 对查询的语句条件进行参数化,然后对参数化以后的查询进行分组统计,统计出各查询的执行时间、次数、占比等,我们在通过分析结果进行优化
安装pt-query-digest
- 下载地址:https://www.percona.com/downloads/percona-toolkit/LATEST/
- 安装命令:
yum localinstall -y percona-toolkit-3.5.0-2.el7.x86_64.rpm - 验证安装结果:
pt-query-digest --help
pt-query-digest 常用命令
pt-summary查看服务器信息- ![pt-query-digest][image-12]
- ![pt-query-digest][image-13]
pt-diskstats 查看磁盘开销使用信息
- 可以实时的查看磁盘的一个IO情况
pt-mysql-summary –user=root –password=7f43940e5949ad52 查看mysql数据库的详情信息,需要设置数据库账号和数据库密码
- ![查看数据库详细信息][image-14]
- ![查看数据库详细信息][image-15]
- ![查看数据库详细信息][image-16]
- ![查看数据库详细信息][image-17]
分析慢查询日志(重要)
pt-query-digest --limit=100% /www/server/data/mysql-slow.log–limit=100% 全部显示,不加的话只会显示部分的SQL条目
前提:必须开启慢查询日志记录,然后查询出慢查询日志的路径
![日志分析][image-18]
日志分析:
Overall: 1 total, 1 unique, 0 QPS, 0x concurrency
日志,总共有 1条慢查询,去掉重复后1条。
Time range: all events occurred at 2022-12-09T09:39:36
查询时间范围
Attribute total min max avg 95% stddev median
total 总时间,min 最小时间,max 最大时间,avg 平均时间,95% = 95%的请求大部分时间,stddev 标准值,median 中位值
s秒,ms毫秒,us微妙
Exec time 执行时间、Lock Time 锁表时间,Rows sent 返回用户的结果数量,Rows examine 扫描数据库的数量,Query size 查询次数
![image-1][image-19]
执行的SQL条目
![执行的SQL条目][image-20]
这里是每条SQL条目的执行详情,以及执行的速度,锁表速度,返回用户的数量,以及扫描数据库的数量,和本条SQL所使用的时间分布。
时间分布:有些类似于 枚举出 好几个时间范围,本SQL的执行时间 属于在哪个时间范围
![SQL查询时间范围][image-21]
Tables下面,不带#号 就是具体执行的SQL命令
查看MySQL的从库和同步状态
pt-slave-find --host=localhost --user=root --password=7f43940e5949ad52- ![主从状态][image-22]
查看MySQL死锁信息
pt-deadlock-logger --run-time=10 --interval=3 --create-dest-table --dest D=test,t=deadlocks u=root,p=7f43940e5949ad52- 一旦有死锁的话,通过该命令就可以查询到死锁记录。
从慢查询日志中分析索引的使用情况
pt-index-usage --user=root --password=7f43940e5949ad52 --host=localhost /www/server/data/mysql-slow.log- ![从慢查询日志分析索引][image-23]
查看mysql表和文件的IO开销(数据库高峰慎用)
pt-ioprofile
查找数据库大于1M的表
pt-find --user=root --password=7f43940e5949ad52 --tablesize +1M- ![查找数据库大于1M的表][image-24]
显示查询时间大于3秒的查询SQL
pt-kill --user=root --password=7f43940e5949ad52 --busy -time 3 -print
kill大于3秒的查询
pt-kill --user=root --password=7f43940e5949ad52 --busy -time 3 --kill
查询出三大类有问题的SQL
工具:pt-query-digest
查询次数多且每次查询占用时间较长的SQL
![查询结果][image-25]
- 可以通过该命令去查询他的一个SQL条目,执行的次数多,占比比较大的SQL就是我们需要优化的SQL。
- Response:执行SQL的返回时间,从上往下依次 代表了查询时间长和慢,单位是秒
- Calls 执行次数
IO大的SQL
核心:pt-query-digest分析中的Rows examine 扫描的行数越大,IO越大,意味着扫描的表行数越多
![IO大的SQL][image-26]
未命中索引的SQL
- pt-query-digest分析中的Rows examine 和Rows Send 的对比,如果两行数据相差较大,则该SQL的索引命中率不高,对于这种SQL,我们要重点关注。
Explain SQL执行计划
- 使用EXPLAIN关键字模拟执行SQL语句,返回执行计划的信息,我们可以通过分析执行计划判断是否存在优化空间。
1)Explain分析示例
数据库表:
1 | DROP TABLE IF EXISTS `actor`; |
2)Explain的列
id
- id越大,执行优先级越高,如果id相同则从上往下执行
select_type
simple
- 简单查询。查询不包含子查询和union
mysql> explain select * from actor where id = 1;- ![简单查询图示][image-27]
primary
- 复杂查询中最外层的 select(最后一个执行的select)
subquery
- 包含在 select 中的子查询(不在 from 子句中)
derived:
- 包含在 from 子句中的子查询。MySQL会将结果存放在一个临时表中,也称为派生表(derived的英文含义)
用一个例子来了解 primary、subquery、derived 类型:
mysql> set session optimizer_switch='derived_merge=off';#关闭mysql5.7新特性对衍生表的合并优化mysql> explain select (select 1 from actor where id = 1) from (select * from film where id = 1) der;- ![派生表图示][image-28]
- 注意:id为1的table
指向 ID为3的衍生表。
union:
table
表示explain这一行访问的表
当from存在子查询时,table 会显示
,表示当前的计划依赖derivenN的查询,必须先进行 derivenN的查询
type
关联类型(访问类型),表示MySQL查找数据行记录的大概范围,可以通过该参数判断出SQL的执行效率。
依次从最优到最差分别为:system > const > eq_ref > ref > range > index > ALL
正常情况:**SQL查询最少达到range级别,最好达到ref **
system
- 查询的表只有一条数据
const
- ![const][image-29]
- primary key (主键索引)或 unique key(唯一索引)的所有列与常数比较时,只匹配到了一行数据。
eq_ref
- 在关联表查询的时候,连接条件使用 primary key (主键索引)或 unique key(唯一索引),且只返回一行数据时。
- 注意:只可能在关联表查询的时候出现eq_ref。
- ![eq_ref][image-30]
ref
- 使用普通索引(二级索引),或者联合索引的部分前缀
- 简单select查询
mysql> explain select * from film where name = 'film11222';- ![简单查询][image-31]
- 关联表查询
mysql> explain select film_id from film left join film_actor on film.id = film_actor.film_id;- ![关联表查询][image-32]
range
- 使用索引进行范围查找,如:in(), between ,> ,<, >=
mysql> explain select * from actor where id > 1;- ![范围查询][image-33]
index(覆盖索引)
- 该方式不会从索引树根节点开始查找数据,而是直接 对二级索引的叶子节点遍历和扫描
- 虽然这种方式也走索引,但是因为需要遍历整个 二级索引的叶子节点,所以这种查询速度较慢,该方式也叫 覆盖索引。
- 效率比all高一点点,是因为index扫描的是二级索引叶子节点,二级索引比主键索引数据少。
- 覆盖索引案例:
mysql> explain select * from film;- ![覆盖索引][image-34]
- 优化方案:
- 增加一个查询条件,查询条件走索引即可。
mysql> explain select * from film where name = 'asdf';- ![image-1][image-35]
ALL
全表扫描,实际上直接扫描 主键索引(聚集索引)的所有叶子节点。
因为MySQL会用主键来组织整张聚集索引表,直接遍历聚集索引的叶子节点就可以找到数据。
主键索引底下有整行的数据,所以扫描起来效率比二级索引效率更低。
possible_keys
- 该计划可能走的索引字段
- 有时候会出现possible_keys有值,但是key为null的情况,是因为表里的数据不多,MySQL认为走索引还不如全表扫描快。
key
- 真正使用的索引字段,如果没有走索引则为null。
key_len
用到的索引 长度(索引字段类型长度,如 int 就是4 )
- 字符串,char(n)和varchar(n),5.0.3以后版本中,n均代表字符数,而不是字节数,如果是utf-8,一个数字
或字母占1个字节,一个汉字占3个字节
char(n):如果存汉字长度就是 3n 字节
varchar(n):如果存汉字则长度是 3n + 2 字节,加的2字节用来存储字符串长度,因为
varchar是变长字符串
- 数值类型
tinyint:1字节
smallint:2字节
int:4字节
bigint:8字节
- 时间类型
date:3字节timestamp:4字节
datetime:8字节
如果用到的是联合索引,按实际用到的索引的字段类型长度。
ref
- 显示在key列中所用到的索引字段,是常量或者是列。
- const(常量)
- 字段名(例,film.id)
rows
- 预计要读取并检测的行数
- 注意这个不是结果集里的行数,只是个大概 要读取的行数
Extra
该字段有几十种结果,下面只列出最常见的几种,不经常用的则不进行描述。
Using index 使用覆盖索引
mysql> explain select film_id from film_actor where film_id = 1;- ![Using index - 覆盖索引][image-36]
- 覆盖索引
- 执行计划的key列有使用到 二级索引,select 后面 全部的查询字段可以从这个索引直接获取数据,这种就叫 覆盖索引,Extra字段显示:Using index,覆盖索引并不是一种真正的索引,只是一种 查询的方式。
- 注意,是全部查询字段,如果有一个字段 不在索引条件,则还是会回表查询,那么这种效率肯定没有Using index高。
- ![Using index 覆盖索引][image-37]
- 回表查询:
- 先找到辅助索引后,通过辅助索引的data (存放的是主键索引),去主键索引树里面找到数据。
Using where
- 使用where条件,并且查询的条件没有走索引
mysql> explain select * from actor where name = 'test';- ![Using where][image-38]
Using index condition
- 查询的列(select 后面的字段)没有完全被索引覆盖,where条件又是个范围条件
mysql> explain select * from film_actor where film_id > 1;- ![Using index condition][image-39]
Using temporary
- MySQL在查询的时候需要通过临时表来处理数据。
- 去重示例:
- 对name字段进行去重时,如果不走索引,则会开辟临时表来进行去重。
mysql> explain select distinct name from actor;- ![Using temporary][image-40]
- 优化:为name字段添加索引
- film表的name是有添加索引的,所以此时直接通过二级索引树可以进行去重,不需要再开启临时表。
mysql> explain select distinct name from film;- ![Using temporary 优化][image-41]
Using filesort
- 使用外部排序,数据小时则通过内存开辟临时空间排序,数据大是会在磁盘完成排序。
- 优化:尽量把排序的条件 通过索引完成排序。
- 未走索引,通过外部完成排序
mysql> explain select * from actor order by name;- ![Using filesort 不走索引][image-42]
- 走索引,在索引书树完成排序
mysql> explain select * from film order by name;- ![Using filesort 走索引][image-43]
Select tables optimized away
- 使用某些聚合函数(比如 max、min)来访问存在索引的某个字段
mysql> explain select min(id) from film;- ![Select tables optimized away][image-44]
SQL命令优化细则
通过一些简单的案例,来更加深入的了解 索引的优化。
1 | CREATE TABLE `employees` ( |
注意:我们按照优化原则优化后,不代表一定会走索引,因为MySQL会有自己的一个cost 成本开销计算,判断是走索引还是全表扫描。
1)优先 优化高并发场景SQL
因为高并发的SQL优化的效果会明显高于 低并发的SQL
案例:
以下有2条SQL,A SQL每小时执行10W次,每次占用20个IO;B SQL每小时执行10次,每次占用2W次IO。
不论是A还是B,一小时下来总占用都是20W次IO,但是明显A 属于高并发SQL,优化IO更容易,A SQL只需要减少2个IO,那么高并发下就可以减少20000 IO。
明确优化目标
需结合实际情况分析,看优化该SQL需要优化到什么程度,做一个目标评估,合理高效的优化到我们预计的目标,看优化的成本和结果是否在承受范围。
2)联合索引优化原则
全值匹配
1 | EXPLAIN SELECT * FROM employees WHERE name= 'LiLei'; |
- 相比较上面三条SQL,第三条SQL 复合联合索引 全值匹配,优先级更高,查询效率更快。
最左前缀原则
如果使用了联合索引,则必须遵守 最左前缀原则,否则 索引会失效。
使用 联合索引 最左侧的索引,并且不可以跳过 中间的索引。
注意:这里的最左原则,并非是指 一定要按顺序 从左往右使用索引,而是SQL条件必须 存在 最左侧的索引。
符合最左前缀:
mysql> EXPLAIN SELECT * FROM employees WHERE name = 'Bill' and age = 31;- ![符合最左前缀][image-45]
mysql> EXPLAIN SELECT * FROM employees WHERE age = 22 AND position ='manager' and name= 'LiLei';- ![符合前缀][image-46]
不符合最左前缀:
mysql> EXPLAIN SELECT * FROM employees WHERE age = 30 AND position = 'dev';![不符合 最左前缀][image-47]
mysql> EXPLAIN SELECT * FROM employees WHERE position = 'manager';![不符合 最左前缀][image-48]
3)不在索引列上做任何操作(计算、函数、(自动or手动)类型转换)
- 如果在索引上做了操作,会导致索引失效而转向 全表扫描。
- 失效原因
- 当你做了计算、函数后,此时的数据是改变的,MySQL在去索引树中查找,会找不到索引,所以不走索引。
4)范围查询右边的列不走索引
- 复合索引也是有顺序的,但是当你 使用了范围查找(<、>),联合索引后面的字段就不会有序了,所以后面的字段不会走索引。
5)尽量使用 覆盖索引
覆盖索引并不是一种索引,而是 一种索引的覆盖方式,可以直接从 辅助索引中可以得到查询的记录,不需要回表到聚簇索引查询。
不要使用select * ,而是应该 只查询你要的数据,并且你查询的字段进行能走索引,如果select的列能走索引,就称为 覆盖索引。
- 除非你的业务确实需要select *,或者把长期不变并频繁访问的数据缓存到redis, 提升读取速度,才使用select *
6不要在索引上使用 !=、<、>、not in、not exists、is not null
- MySQL在使用 !=、<、>、not in、not exists、is not null 时,会导致索引失效从而转向全表扫描。
like以通配符开头(’%aaa’)不走索引
- 如果使用like的话,不可以以通配符开头,否则会导致 索引失效,从而转向全表扫描。
- 正确案例
mysql> EXPLAIN SELECT * FROM employees WHERE name like 'aaa%';- ![like 走索引案例][image-49]
- 错误案例
mysql> EXPLAIN SELECT * FROM employees WHERE name like '%aaa';- ![like 不走索引案例][image-50]
- 问题:如何让通配符开头(like’%字符串%’) 也可以走索引
- 使用覆盖索引
- select的字段都在索引列中,就称为 覆盖索引,虽然该方式 type只是index,但是也比all强
mysql> EXPLAIN SELECT name,age FROM employees WHERE name like '%aaa%';- ![like 通配符开头也走索引][image-51]
8)字符串必须加单引号
- where条件如果是字符串,则必须加单引号,否则会导致 索引失效。
- 正确案例
mysql> EXPLAIN SELECT * FROM employees WHERE name = '1000';- ![正确案例][image-52]
- 错误案例
mysql> EXPLAIN SELECT * FROM employees WHERE name = 1000;- ![错误案例][image-53]
9)慎用IN、OR
使用IN、OR 不一定会走索引,MySQL根据内部优化器判断cost开销来决定是否走索引。
- 如果是大数据量的话,IN是会走索引的,如果数据量少则不会走索引。
*OR改写成UNION
- OR不走索引,如果改成了UNION效果是一样的,并且UNION会走索引
- OR不走索引
mysql> explain select out_trade_no from sys_order where out_trade_no = '1' or is_settlement = 1 \G- ![OR不走索引][image-54]
- UNION会走索引
mysql> explain select out_trade_no from sys_order where out_trade_no = '1' union select out_trade_no from sys_order where is_settlement = 1 \G- ![UNION会走索引][image-55]
使用union all代替union
union 会在合并结果集时,开辟临时空间进行去重,如果你的union合并过程不需要进行去重,或者数据本身就不存在重复的情况,就可以直接用union all代替union
Union all 合并结果集时,不去重:
mysql> explain select out_trade_no from sys_order where out_trade_no = '1' union all select out_trade_no from sys_order where is_settlement = 1 \G- ![使用union all代替union][image-56]
Union 合并结果集时会自动去重:
mysql> explain select out_trade_no from sys_order where out_trade_no = '1' union select out_trade_no from sys_order where is_settlement = 1 \G- ![Union 合并结果集时会自动去重][image-57]
10)慎用 范围查询
- 使用范围查询的话,MySQL不一定会走索引,MySQL根据内部优化器判断是否走索引。
explain select * from employees where age >=1 and age <=2000;- ![慎用范围查询][image-58]
11)关联表查询不能超过3张表
如果当前的项目是互联网项目或者数据量较大,则必须保证 以下规则:
- 连表查询最多不可以超过3张(阿里开发铁律)
- 避免复杂的子查询
针对百万级数量或以上的数据库或高并发场景,尽量避免在MySQL中进行Join 关联表查询操作。
尤其是单表数据量大、高并发的场景,一旦join 关联表查询的话会导致锁定资源太多,性能会急剧下降
如果只是一个内部小型的项目,数据量不会太多,没有高并发的问题,且没有后期优化的问题,则可以忽略该问题
解决方案:
- 根据 索引 单表查询获取数据,然后在业务层代码实现数据整合。
分解关联查询的好处
- 让缓存的效率更高
- 减少锁的竞争
- 更容易做到高性能和可扩展
- 减少冗余记录的查询
12)永远用小结果集驱动大结果集
注意:连表查询仅适用于 join的表低于百万级别数据,如果超过的话,则要拆分成单表查询,否则会影响查询效率。
MySQL的连表查询实际上是 嵌套查询,它会用外层的一张表来for循环 查询内表,进行比对。
如果是多张表,则会for循环嵌套多张表。
此时涉及到了笛卡尔乘积的概念,外层嵌套的表数据越少,他for循环次数则越少,所以永远 都要用小结果集驱动大结果集。
案例:
- 外表10W行,内表10行则需要循环查询另外一张表10W次和内表比对。
- 外表10行,如果内表10W行,则只需要循环10次 和内表比对。
13)尽可能在索引中完成排序
- where 查询条件 如果涉及联合索引,需要遵守 最左前缀匹配原则。
- 排序和分组查询的话,如果要走联合索引的话,要确保 联合联合索引的where查询结果是有序的(不可以跳过中间的索引字段)。
- key列只显示where使用到的索引,排序使用索引情况要看Extra 列
具体详细内容,请看下面的章节 《Order by、Group by索引优化》。
14)合理设计并利用索引
在设计索引时候需要合理,需要明确知道在什么场景下使用单个索引和复合索引,避免索引失效。
MySQL索引优化
1)索引优化例子
联合索引范围查询
联合索引第一个字段用范围不会走索引
联合索引第一个字段使用范围查询(><等)的话,MySQL不会走索引,直接回表全表扫描,MySQL认为回表扫描效率更高
联合索引:KEY `idx_name_age_position` (`name`,`age`,`position`) USING BTREE
EXPLAIN SELECT * FROM employees WHERE name > 'LiLei' AND age = 22 AND position ='manager';
![联合索引第一个字段用范围不会走索引][image-63]
联合索引中间字段使用
如图所示,该SQL也可以走索引,但是联合索引只用到了 name和age, 因为age是范围查询,右边的字段(posi)不走索引
EXPLAIN SELECT * FROM employees WHERE name = 'LiLei' AND age < 22 AND position = 'manager';
![联合索引中间字段使用][image-64]
联合索引最后一个字段使用范围
联合索引最后一个字段使用了范围查询,后面没有在携带查询条件,则不会影响到索引,通过key_len可以发现3个索引都用上了。
EXPLAIN SELECT * FROM employees WHERE name = 'LiLei' AND age = 22 AND position > 'manager';
![联合索引最后一个字段使用范围][image-65]
让MySQL强制走索引
possible_keys:可能走的索引;key:真正使用的索引。
有时候我们会发现执行计划可能会走索引,但实际没走(key是空的)。
虽然rows 检测行数较多,但是MySQL根据算法判断 走全表扫描比走索引更快,所以就走了全表扫描。
EXPLAIN SELECT * FROM employees WHERE name > 'LiLei' AND age = 22 AND position ='manager';
![让MySQL强制走索引][image-66]
通过SQL强制性走索引
EXPLAIN SELECT * FROM employees force index(idx_name_age_position) WHERE name > 'LiLei' AND age = 22 AND position ='manager';
![通过SQL强制性走索引][image-67]
不建议强制干预MySQL
虽然我们上面通过命令强制走索引,rows 确实也只扫描了5w行,比走全表扫描更少。
但实际上:很多时候,全表扫描不一定会比索引慢,所以不要轻易的去干预MySQL的优化器选择。
干预和不干预效率验证:
先关闭MySQL 5.7及以下的查询缓存
1 | set global query_cache_size=0; |
- 不干预,让MySQL优化器自己选择
SELECT * FROM employees WHERE name > 'LiLei'- ![不干预,让MySQL优化器自己选择][image-68]
- 干预MySQL强制走索引
- 强制走索引的话,虽然rows只扫描5w行,比MySQL少了5w行,而且也走了索引key,但实际上效率并没有比全表扫描快。
SELECT * FROM employees force index(idx_name_age_position) WHERE name > 'LiLei';- ![干预MySQL强制走索引][image-69]
覆盖索引优化
- 尽量不要select * ,而是按需提取我们需要查询的列,如果提取的列都能被索引覆盖,则叫 覆盖索引。
EXPLAIN SELECT name,age,position FROM employees WHERE name > 'LiLei' AND age = 22 AND position > 'manager';
![覆盖索引优化][image-70]
数据量大时IN和OR会走索引
- 在表数据量大的时候,MySQL优化器在执行 IN 和 OR时,都会走索引,但是如果表数据量不多时,则会选择全表扫描。
- 这并不是绝对的,具体看MySQL优化器cost开销算法决定。
Like CC% 一般都会走索引(索引下推)
EXPLAIN SELECT * FROM employees WHERE name like 'LiLei%' AND age = 22 AND position ='manager';
![Like 索引下推图示][image-71]
Like cc% 或 Like cc%cc%,只要like开头不是%的,一般情况都会走索引,如上图所示,key_len是140,说明整个联合索引都走了索引,这是因为涉及到了一个新的概念:索引下推。
索引下推
MySQL索引下推是在5.6推出的新功能,目的是为了更好的优化MySQL索引查询效率,目前仅作用于(Like ‘kk%aa%’,Like ‘aa%’),对范围查询不起作用。
对于联合索引(name,age,position),按照最左前缀原则,只会走name的索引,因为查询完name后的数据,age 和position是无序的,无法很好的利用索引。
MySQL5.6之前版本 查询执行流程:
在5.6之前查询,会先去二级索引树查询 like ‘LiLei% ,然后拿到这些索引对应的主键去聚簇索引树中查询相应记录,最后在统一比较age和position是否符合。
MySQL 5.7 查询执行流程:
5.6加入了索引下推,可以在二级索引中遍历 联合索引第一个字段时,同时对所有包含索引的查询字段 进行比较,过滤掉不符合条件的数据后再去聚簇索引中回表查询,有效减少回表的次数。
为什么范围查找不会进行索引下推
范围查找的结果集普遍过大,所以MySQL默认不进行索引下推。
2)MySQL选择索引原则
- 在执行SQL时,MySQL会根据优化器进行cost开销判断,决定是否走索引还是全表扫描。
示例一:全表扫描:
mysql> EXPLAIN select * from employees where name > 'a';
![全表扫描][image-72]
示例二:走索引
mysql> EXPLAIN select * from employees where name > 'zzz' ;
![走索引][image-73]
对于上面2种 name > a 和 name > zzz的执行结果,相同的SQL、条件,只是查询内容不同,一个走索引,一个不走索引,因为MySQL会根据优化器判断是否走索引还是全表扫描。
我们可以通过 trace工具 来分析MySQL优化器是如何选择,注意:trace只能用于临时分析,为避免影响性能,分析完后立即关闭。
Trace分析工具
1 | set session optimizer_trace="enabled=on",end_markers_in_json=on; -- 开启trace工具 |
![Trace分析工具][image-74]
通过Trace列可以获取到我们刚才查询SQL的一个分析数据。
分析数据:
1 | { |
join_preparation 第一阶段 SQL格式化
- 格式化我们的SQL,翻译成MySQL能识别的SQL
join_optimization 第二阶段优化
进行很多优化操作
如 把联合索引 左边第一个字段写到 where 后面去,MySQL会通过优化器进行排序,使左侧第一个在联合索引最前面。
这里就不一一举例,明白这个优化器做了什么就行。
rows_estimation 预估表访问成本
1 | "rows_estimation": [ //预估表的访问成本 |
potential_range_indexes 可能使用的索引,这里主键索引usable 为false,说明不走主键索引,反而走了二级索引
MySQL Cost开销成本比较
全表扫描:全表扫描table表(employees) ,预计扫描行 rows 96599,cost 开销9724
分析索引开销(analyzing_range_alternatives):
- index 就是索引字段(idx_name_age_position)
- ranges 索引使用范围
- index_only 是否使用覆盖索引
- rows 索引扫描行,48249
- cost 索引使用成本,16887
- chosen 是否使用该索引
注意:决定MySQL使用哪个索引的条件,是Cost 开销成本,而并非 Rows 扫描行数。
综上所述,该SQL(select * from employees where name > ‘a’ order by position; )全表扫描cost低于索引的,所以走了全表扫描。
3)Count(*) 优化查询
为什么需要对count(*)进行优化
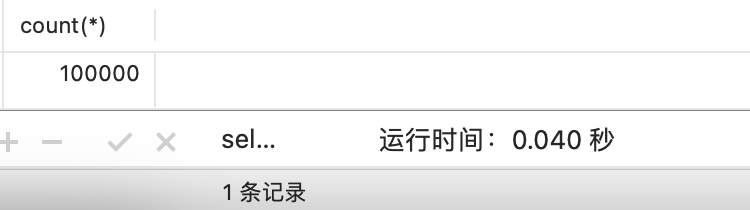
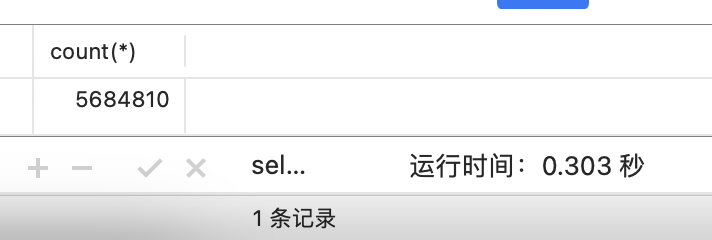
- 如果是在大数据量的情况下,如百万级和千万级的表,select count (*) 也是很耗费时间成本的。
- 10W数据的表 count(*)
- 50W的数据表 count(*)
1 | -- 临时关闭mysql查询缓存,为了查看sql多次执行的真实时间 |
上面4条SQL执行计划是一样的,说明执行效率差不多。
count 的字段有索引:count(*) > count(1) > count(字段) > count(主键ID)
- 字段有索引的话,MySQL会优先选择 二级索引来查找,因为二级索引数据相对 聚簇索引更少,检索性能更高。
count 的字段没索引:count(*) > count(1) > count(主键ID) > count(字段)
count(1)和count(*)执行过程:
- MySQL查询时不会取值,而是 计数器加1,效率很高。
优化方式
1、show table status
- 该命令可以直观的看到表里的大致数据信息,但行数 rows 不是很精准,如果你的业务不需要那么精准的统计的话,这个可以尝试。
- ![show table status][image-75]
2、额外写一张表用来做计数器
- 在插入和删除的时候,维护一张表单独做计数器。
4)Order by、Group by索引优化
注意事项:
- where 查询条件 如果涉及联合索引,需要遵守 最左前缀匹配原则。
- 排序和分组查询的话,如果要走联合索引的话,要确保 联合联合索引的where查询结果是有序的(不可以跳过中间的索引字段)。
- key列只显示where使用到的索引,排序使用索引情况要看Extra 列
索引优化案例
Case 1
EXPLAIN select * from employees where name = 'LiLei' and POSITION = 'dev' order by age;
![Case 1][image-76]
查询条件:联合索引只用了name索引,通过key_len = 74也可看出。
age 索引是用在了排序上,key列只显示where使用到的索引,排序使用索引情况要看Extra 列,显示:using filesort 代表没走索引。
为什么age能走索引:
因为where 条件走name的联合索引,where出来的结果已经是排好序的了,所以age可以直接走索引进行匹配。
Case 2
EXPLAIN select * from employees where name = 'LiLei' order by POSITION;
![Case 2][image-77]
查询条件:联合索引只用了name索引,通过key_len = 74也可看出。
为什么position不走索引:
因为这里的position,跳过了age,联合索引已经断开了,所以Extra显示:using filesort,走了全表扫描。
如果跳过了age,那name即便排好序了,少了age就不会走索引。
Case 3
EXPLAIN select * from employees where name = 'LiLei' order by age,POSITION;
![Case 3][image-78]
查询条件:联合索引只用了name索引,通过key_len = 74也可看出。
为什么排序 age,position会走索引:
因为查询的时候name已经排好序了,并且age在position前面,所以排序的时候走索引。
Case 4
EXPLAIN select * from employees where name = 'LiLei' order by POSITION,age;
![Case 4][image-79]
查询条件:联合索引只用了name索引,通过key_len = 74也可看出。
为什么position,age 顺序颠倒后排序就不走索引:
联合索引:KEY idx_name_age_position (name,age,position) USING BTREE
在where 查询条件中,如果顺序是颠倒的是没问题,因为MySQL优化器会进行词法格式化(优化)后执行。
如果是排序的话,顺序一定不能颠倒,颠倒了就不会走索引。
Case 5
EXPLAIN select * from employees where name = 'LiLei' and age = 1 order by POSITION;
![Case 5-1][image-80]
查询条件:联合索引用了name和age,key_len 78 ,age是int类型,占了4个字节。
为什么这里age会走索引:
因为这里的查询条件,复合最左前缀匹配原则,没有断开,如果换成下面的方式则会出问题:
EXPLAIN select * from employees where name = 'LiLei' and POSITION = 'dev' order by age;
![Case 5-2][image-81]
查询:只用到了name,因为查询的时候已经跳过了age。
排序:查询name字段的时候,查询结果已经排好序,order by的时候可以通过排好序的查询结果直接匹配 age数据。
Case 6
EXPLAIN select * from employees where name = 'LiLei' order by age asc,position desc;
![Case 6][image-82]
如果同时存在2个order by,还一个升序一个降序,排序肯定是乱的,所以无法走索引。
Case 7
EXPLAIN select * from employees where name in('LiLei','ZhangSan') order by age,position;
![Case 7][image-83]
使用in的话,走不走索引要具体看MySQL的cost 开销判断,如果MySQL认为走全表扫描开销更小,则会走全表扫描,同理反之。
因为使用了name作为查询索引,排序的时候也可以正常排序,如果没有走索引的话,排序就会 使用 文件排序 filesort。
Case 8
之前的章节有提到,不要在索引上使用范围查询(<、>),否则会导致索引失效从而转向全表扫描。
EXPLAIN select * from employees where name > 'a' order by name;
![Case 8 索引失效][image-84]
因为MySQL认为在索引树上进行范围查询,cost 开销更大,所以从而走了全表扫描。
解决方案
使用覆盖索引进行优化,不要使用select * ,而是提取我们需要的字段(索引)。
EXPLAIN select name,age from employees where name > 'a' order by name;
![Case 8-2 索引优化][image-85]
这里需要注意,这里key表示已经走了索引,走的是name,但是Extra 有Using where,Extra不一定百分百准确,仅作为参考。
##
Order by优化总结
- MySQL支持2种方式排序 Using index和filesort
- Using index(效率高)
- 通过走索引完成排序
- filesort(效率低)
- 在内存中创建临时空间完成排序,如果结果集过大的话还会创建临时文件写入磁盘中进行排序
- 什么情况下 order by 会通过索引完成排序
- order by子句的排序字段,使用了索引,如果是 联合索引则必须遵循 索引创建的顺序的最左前缀原则
- 注意:如果只有order by,没有where的话,则select 的查询内容必须 覆盖索引,否则不会使用索引完成排序
EXPLAIN select name from employees order by name,age,position;- ![覆盖排序图示][image-86]
- 不要使用select * ,而是应该 只查询你要的数据,并且你查询的字段进行能走索引
- 既有where 又有order by :where 的字段和order by的字段 加起来(组合起来),可以遵循 索引创建的顺序的最左前缀原则
- 例:
EXPLAIN select * from employees where name = 'LiLei' order by age,position;- ![image-1][image-87]
- 不论是Order By还是Group By 尽量都在索引上完成操作,必须严格遵循 索引创建的顺序的最左前缀原则(联合索引)
- 如果不在索引上完成操作,会走 filesort 文件排序,效率相对索引排序比较低
- 能使用覆盖索引,尽量使用覆盖索引
- select 查询条件,能走覆盖索引,尽量走覆盖索引,可以减少回表的次数,慎用select *
- group by 与order by很相似,本质:先排序后分组,group by也要同上所述,遵循 索引创建的顺序的最左前缀原则
- 如果group by我们不想要排序,只想要分组,我们可以这样写:order by null ,让group by禁止排序
- where 优先级高于 having,能使用where就别使用having
- where和having的区别
- where只能跟着from后,having只能跟着group by后。
- where是判断数据从磁盘读入内存的时候
- having是判断分组统计之前的所有条件
- having子句中可以使用字段别名,而where不能使用
- having能够使用统计函数,但是where不能使用
Using filesort文件排序原理
filesort分为2种排序方式:
- 单路排序
- 一次性取出满足查询条件的所有字段,放在sort buffer (临时内存空间)中进行排序。
- 特点:排序速度快,但是占用大量的内存空间
- 用trace工具分析,sort_mode信息里会显示< sort_key, additional_fields >或者< sort_key, packed_additional_fields >
- 双路排序(回表排序)
- 根据相应的查询条件取出 排序的字段和主键ID,在sort buffer中进行排序,排序后在通过主键ID去聚簇索引中回表取出其他字段。
- 特点:排序速度慢,因为还需要回表查询,但是占用内存空间少
- 用trace工具分析,sort_mode信息里会显示< sort_key, rowid >
MySQL通过比较参数 max_length_for_sort_data(默认1024字节,1KB) 的大小和需要查询的字段总大小来判断使用哪种排序模式。
如果 字段的总长度小于max_length_for_sort_data ,那么使用 单路排序模式;
如果 字段的总长度大于max_length_for_sort_data ,那么使用 双路排序模式。
该参数是可以修改的,但不建议修改,MySQL的系统参数都是经过成千上万次调优的,如果随意修改可能造成性能急剧下降。
Trace 分析排序方式
1 | // 开启trace分析工具 |
num_initial_chunks_spilled_to_disk:
- MySQL在启动时会分配一个内存空间(sort baffer),当我们进行排序的时候如果不走索引则会把数据提取到sort buffer进行排序,如果buffer溢出了,就会先把需要排序的数据写入到磁盘中,在从磁盘提取需要的排序数据放入内存进行排序,这个过程也叫 落盘。
- 这个值如果为0代表全部使用的sort_buffer内存排序,否则使用的 磁盘文件排序,后面是数字代表用了多少个临时文件。
sort_mode:
- <fixed_sort_key, packed_additional_fields> 单路排序
- < sort_key, rowid > 双路排序
单路排序详细过程:
从索引name找到第一个满足 name = ‘test’ 条件的主键 id
根据主键 id 取出整行,取出所有字段的值,存入 sort_buffer 中
从索引name找到下一个满足 name = ‘test’ 条件的主键 id
重复步骤 2、3 直到不满足 name = ‘test’
对 sort_buffer 中的数据按照字段 position 进行排序
返回结果给客户端
双路排序详细过程:
- 从索引 name 找到第一个满足 name = ‘test’ 的主键id
- 根据主键 id 取出整行,把排序字段 position 和主键 id 这两个字段放到 sort buffer 中
- 从索引 name 取下一个满足 name = ‘test’ 记录的主键 id
- 重复 3、4 直到不满足 name = ‘test’
- 对 sort_buffer 中的字段 position 和主键 id 按照字段 position 进行排序
- 遍历排序好的 id 和字段 position,按照 id 的值回到原表中取出 所有字段的值返回给客户端
高性能索引设计原则
代码先写,索引后优化
错误做法
大部分人建完表后,会预估哪些字段可能会用到索引(频繁使用),马上设置索引,这是不对的。
正确做法
先等主体业务功能代码开发完毕,在把涉及到业务功能的SQL提取出来分析之后,在考虑建立什么样的索引。
尽量使用 联合索引 覆盖查询条件
尽量少创建 单值索引,多创建联合索引
为什么不建议创建单值索引?
- MySQL一般情况下在一条SQL里只会走一个索引(单值索引或联合索引),如果查询条件较多,单值索引无法覆盖到所有条件,除了单值索引外,其他的查询条件明显是走不了索引的。
- 特殊情况:特殊情况的话,会进行索引合并,具体可以看我博客 《MySQL索引合并详解》
- MySQL一般情况下在一条SQL里只会走一个索引(单值索引或联合索引),如果查询条件较多,单值索引无法覆盖到所有条件,除了单值索引外,其他的查询条件明显是走不了索引的。
尽量让每一个联合索引能够覆盖到SQL语句的where、order by、group by字段,还要确保SQL满足联合索引 最左前缀原则。
不要在 **小基数字段上 ** 建立索引
- 小基数字段
- 比如有一张表共计1000w行记录,性别字段 不是男(1)就是女(2),那么该字段的基数就2 。
- 计算方式:直接进行distinct 去重,看看有多少数据是不重复的
- 为什么不建议在 小基数上做索引
- 在小基数字段上建立索引,查询效果还不如直接全表扫描,因为在索引树中小基数字段,无法快速的进行二分(折半)查找
- 基数:COUNT(DISTINCT name)/COUNT(*) 可求出当前列的 重复基数
- 如果基数越小 查询效率越低,重复的数据太多,基数越大 查询效率更快。
长字符串字段可以采用 前缀索引
- 在设计数据库时,应当合理使用 字段类型,减少磁盘空间的占用。
- 如 varchar(255) 这种字段建立索引,索引树的索引会比较大,除了占用磁盘空间,查询索引树时的效率也会受一定影响。
- 优化方案 - 前缀索引
- 如 提取该这段的前20位字符建立索引,如:index(name(20),age,position)
- 此时name查询,会去索引树中根据name的前20个字符去搜索,定位到前20字符匹配的数据后,后再去聚簇索引提取完整的数据进行匹配。
- 注意:如果采用 前缀索引的方式,因为name只包含了前20位,order by、group by 排序是无法正常走索引。
where与order by 索引设计冲突时,优先where
- 如果发生冲突了,要优先考虑where,因为where过滤后结果集就少很多,排序的效率快。
根据慢查询SQL做相对应的优化
- 通过监听、观察慢查询SQL语句,对其进行单独的索引优化。
较频繁的作为查询条件的字段应当创建索引
更新频繁的字段,且查询次数较少不适合创建索引
索引字段如果更新非常频繁,需要维护 索引树结构,会产生磁盘IO。
如果更新频繁,且查询频繁,牺牲性能情况下也可以建立索引。
在MySQL中,对于不同的字段选择正确的数据类型 尤为重要,合理的选择数据类型,可以提升MySQL的执行效率。
- 根据业务需求,合理并正确的选择列对应的数据类型,如:开关状态,能用TINYINT则不用INT。
- 好处
- 提升查询速度,类型占用越小,相对的在索引树的查询就越快
- 数据类型越小,占用的存储空间越少,一个叶子节点能存放的索引就更多
只为用于 查询,排序,分组的字段 建立索引,select 后面的查询内容 一般不建立索引
- select * from order where id = 1 order by name desc group by age
- id ,name,age 可建立索引
- select * from order where id = 1 order by name desc group by age
不要频繁的修改主键ID(Update)
- 如果频繁的修改主键ID,B+Tree的索引树需要重新排序优化,导致性能下降
冗余索引 和重复索引 会影响性能,酌情考虑是否删除
- 冗余索引
- (name,age) 和(name) ;左边2个索引,明显单值索引 name有些多余了,直接使用联合索引就可以实现,建议 删除
- 长时间未使用的索引
- 长时间未使用的索引建议删除,可以减少数据库的存储空间,查询速度也能提升
- 冗余索引
针对百万级数量或以上的数据库或高并发场景,拒绝在MySQL中进行Join操作,推荐分别根据索引 单表查询获取数据,然后在业务层代码实现数据整合。
- 尤其是单表数据量大、高并发的场景,一旦join的话会导致锁定资源太多,性能会急剧下降
索引设计实战
![索引设计实战图示][image-88]
范围查询的索引 要放在 联合索引最后一个字段。
性别、爱好等 小基数的字段,可以使用IN 来查询,IN也是范围查询的一种,但是IN是可以正常走索引的,也不影响后面的字段。
一张表建议只建立2-4个联合索引,尽量覆盖大部分场景。
- 尽量利用1-2个复杂的联合索引覆盖80%的查询,然后在使用1-2个辅助索引覆盖其他查询,充分利用索引,才能保障查询性能。
索引并不是越多越好,索引建立的太多,虽然能覆盖多个场景,查询效率快,但是插入数据、修改数据、删除数据会比较慢。
5)分页查询优化
mysql> select * from employees limit 10000,10;
在生产环境中很多场景都会用到分页查询,如上面这条SQL,看似只查询了10条,实际上是查询了10010条(10000+10),然后把 10000之前数据的删除,只保留10000开始的10条记录。
因此,如果是要查询一张数据量较大的表,分页数量靠后的话,执行效率很低。
自增且连续的主键排序分页优化
- 该方式条件较为苛刻,必须保证 主键是自增,并且 没有任何排序order by,且中间是没有删除过任何数据的情况。
优化前:
select * from employees limit 99000,5;
- ![优化前执行计划][image-89]
优化后:
select * from employees where id > 99000 limit 5;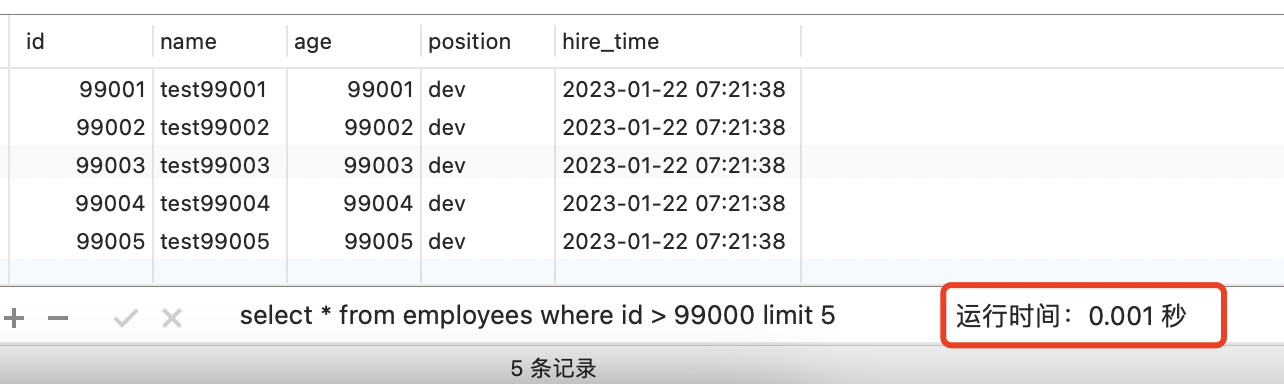
![优化后的执行计划][image-90]
优化后的SQL会走索引,扫描行数减少,执行效率更高。
前提:主键是自增的,且没有排序(或 排序是按照 主键升序,从小到大),中间没有删除过任何数据,但是这种情况较为苛刻,一般用不上,这里只是略微介绍。
非主键字段排序的分页优化
select * from employees ORDER BY name desc limit 90000,5;
![待优化SQL][image-91]
Explain:
explain select * from employees ORDER BY name desc limit 90000,5;
![待优化SQL执行计划][image-92]
排序的时候走文件排序 filesort,不走索引 name。
- MySQL觉得扫描整个索引的cost成本比全表扫描cost成本更高,优化器选择 全表扫描。
优化方法
思路:先让排序和Limit 分页先查出主键ID,在通过内连接进行 主键ID关联,根据主键查询对应的数据。
![优化步骤][image-93]
select * from employees e inner join (select id from employees order by name limit 90000,5) ed on e.id = ed.id;
![优化后SQL][image-94]
Explain:
explain select * from employees e inner join (select id from employees order by name limit 90000,5) ed on e.id = ed.id;
![优化后执行计划][image-95]
排序走了索引,内连接也走了索引,得出的结果集非常少,只有5条,执行时间也少了很多。
6)MySQL数据类型
在MySQL中,对于不同的字段选择正确的数据类型 尤为重要,合理的选择数据类型,可以提升MySQL的执行效率。
选择数据类型前 要明确知道:
- 该字段属于什么类型
- 数字
- 小数点精度,取值范围,是int还是double还是decimal
- 字符串
- 取值范围,是否定长,有没有符号
- 时间
- 是需要存储日期还是时间,如果是日期则选择 DATE,如果是时间则选择 DATETIME,不建议选择 TIMESTAMP
- 二进制
数值类型

- 明确只要只需要1个字节,且取值范围在 -128 , 127之间,可以使用 TINYINT
- 如:性别,男 1 女 2 不男不女 3 ,开关,1 开, 0 关闭 等
- 如果明确 整型的数据没有负数,创建表时候可以选择 无符号,这样取值范围可以扩大一倍。
- 涉及到小数点和金钱计算,则使用DECIMAL,慎用DOUBLE和FLOAT,这两个会存在精度丢失的问题
- 使用DECIMAL注意设置 数值长度和小数点长度
- 使用INT、TINYINT时,不要设置 长度范围
- 如:INT(11) , 不要设置这个,这个是 显示宽度,不是INT的取值长度,只有使用到**零填充(ZEROFILL)时才会用到。**
- 例:INT(5),还设置了 零填充,查询结果是5,MySQL在输出的时候会自动往前面填充0,结果:00005
时间类型
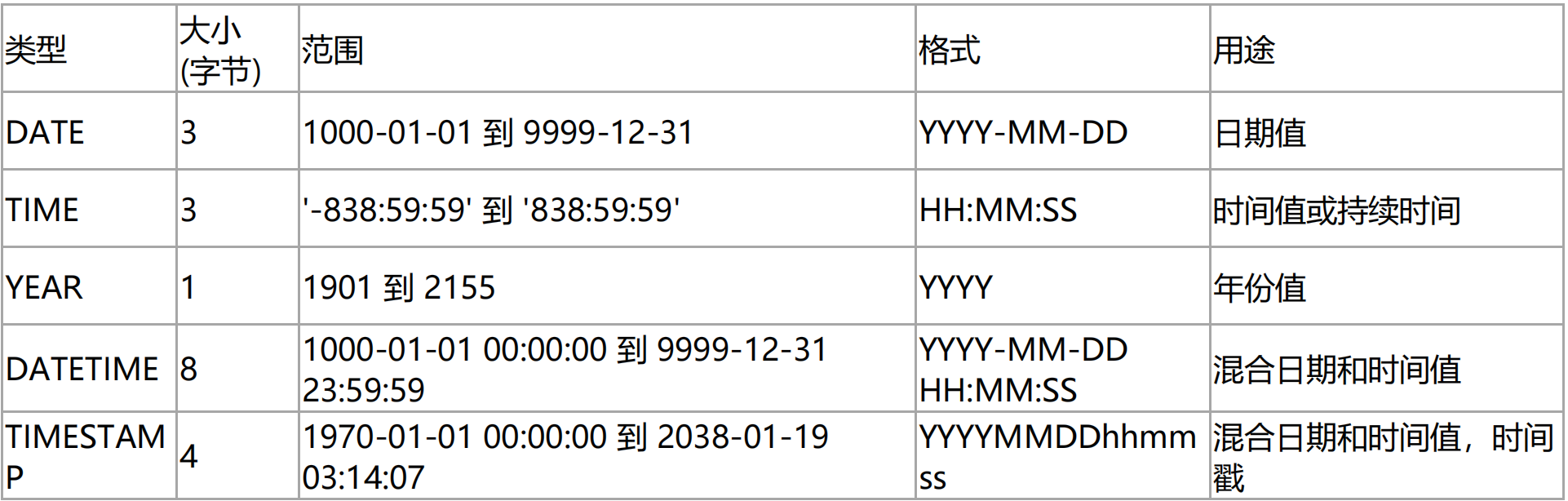
尽量使用 DATE、DATETIME 来存储 日期(DATE,yyyy-mm-dd)和时间(DATETIME,yyyy-mm-dd hh:ss:mm)
- 慎用TIMESTAM,虽说TIMESTAM占用空间少,但是TIMESTAM智能存储到2038年,万一你的项目做大了呢,到时候再来优化就很麻烦了
- 一个表至少得有3个字段,id,创建时间(gmt_create),更新时间(gmt_modified)
- 创建时间:可以用 CURRENT_TIMESTAMP作为默认值(5.6以下版本不支持),在插入数据时会维护创建时间
- 更新时间:修改数据时候自动更新 更新时间字段
切记不可使用 字符串、整数来存储Unix时间戳,在通过时间戳转换成 时间,早期都是这样做的,这种做法无法使用MySQL自带的时间函数


字符串
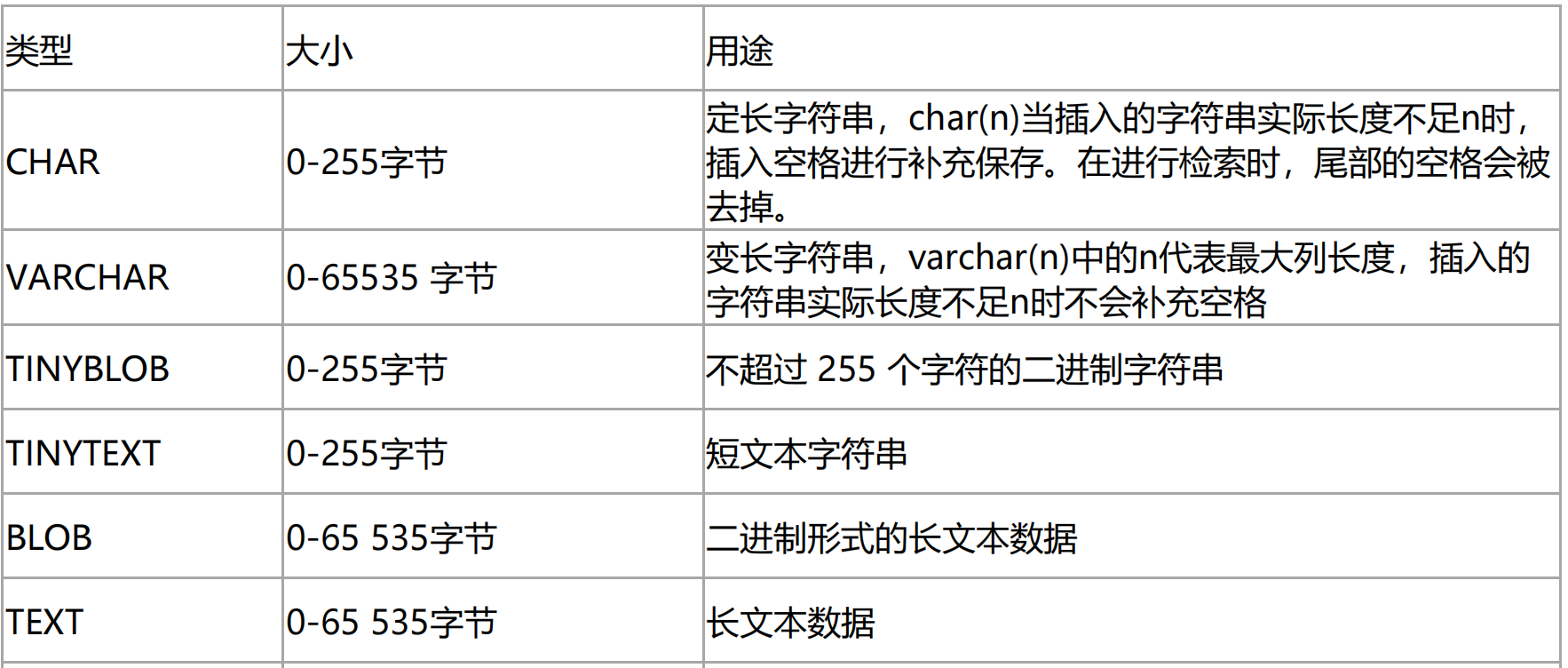
定长和变长的区别:
定长(CHAR)
- 假设CHAR(5),如果你插入的字符串长度不足5,例如1 ,那么他会自动在尾部 用空格补齐,如:1_____(这里我用_代替空格,怕你们看不见,实际上是空格),但是在查询的时候,会自动去除尾部空格,条件:1 依旧能查到。
变长(VARCHAR)
- 假设VARCHAR(5),如果插入的字符串是1,他不会补齐空格。
优化意见:
- 慎用TEXT长文本数据,如果要用的话,请斟酌一下长文本数据量,如果数据量过大,为避免查询效率降低,就得重新建表关联
- 创建一个新的数据表,把TEXT数据存储进去,用ID 关联起来,这样TEXT长数据就不会堆积在同一个聚簇索引上,能提升查询效率
- 为避免 计算精度以及准确性,需要计算的数字,不要存储到字符串。
Join 关联查询优化
为了更好的演示如何优化Join,我们需要创建2张表进行关联查验的演示
1 | CREATE TABLE `t1` ( |
1)MySQL关联查询概念
通过驱动表的结果集为 循环基础数据,一次一行循环从结果集中取到关联字段,根据关联字段到 被驱动表中取出满足条件的行,然后合并结果集。
Left join 左连接
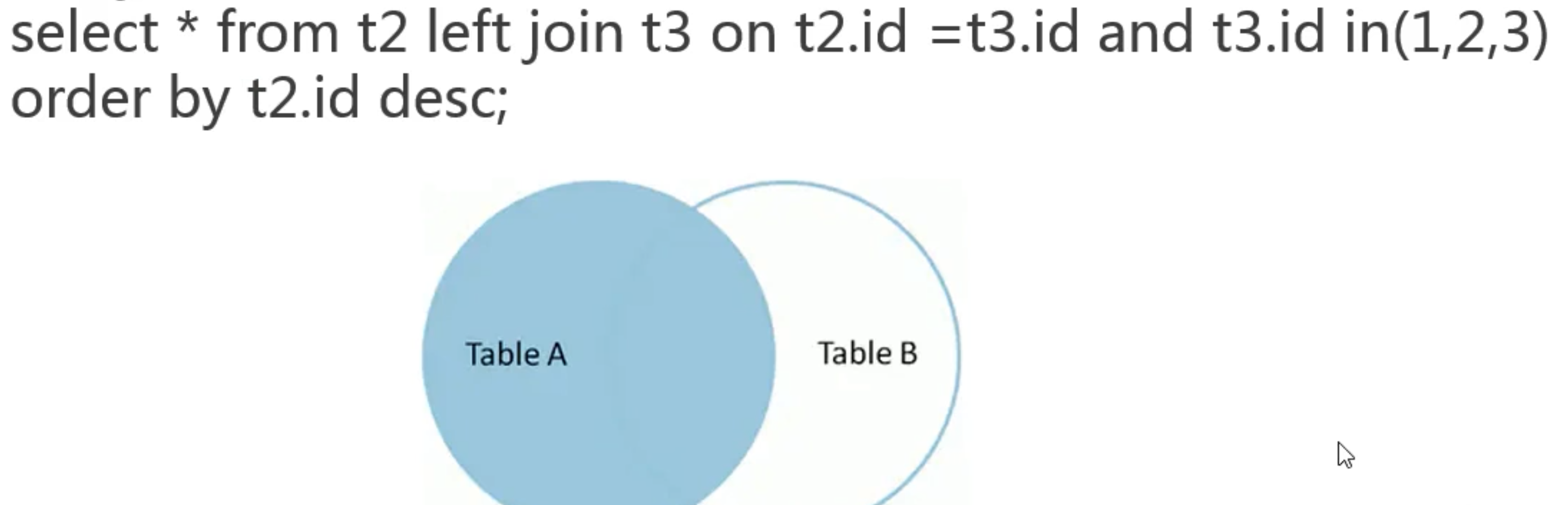
以左边的表作为驱动表,显示出左边的表(驱动表)所有数据,不属于驱动表的字段为NULL 填充。
Right join 右连接
以右边的表作为驱动表,显示出右边的表(驱动表)所有数据,不属于驱动表的字段为NULL 填充。
Inner join 内连接
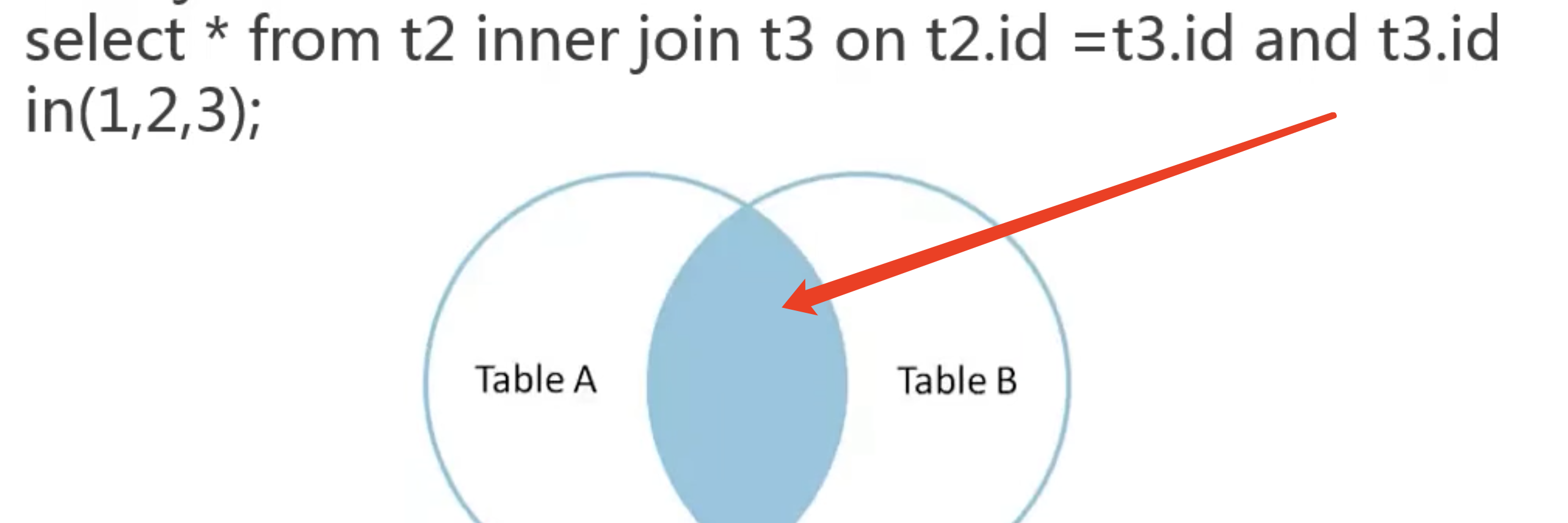
MySQL自己决定用哪个表作为驱动表(结果集少),然后取2个表相同的字段作为结果集。
2)Join算法
MySQL常见的算法有2种:
- Nested-Loop Join 算法(嵌套循环算法)
- Block Nested-Loop Join 算法(基于块的嵌套循环算法)
循环嵌套连接算法 Nested-Loop Join(NLJ)
注意:想使用循环嵌套算法, 被驱动表关联字段必须有索引,如果关联字段没有索引,MySQL就会执行 基于块的嵌套循环连接算法。
用一句话概括关联查询
通过驱动表的结果集为 循环基础数据,一次一行循环从结果集中取到关联字段,根据关联字段到 被驱动表中取出满足条件的行,然后合并结果集。
EXPLAIN select * from t1 inner join t2 on t1.a= t2.a;
![循环嵌套连接算法][image-96]
- 驱动表和被驱动表的规则
- 使用Left join,左边的表则为驱动表,右边的表为 被驱动表。
- 使用Right join,右边的表则为驱动表,左边的表为 被驱动表。
- 使用join、inner join,MySQL会根据2张表哪个结果集较少,就作为驱动表。
如图所示,关联字段是2张表的主键ID,驱动表是t2,被驱动表是t1,因为t2数据量少只有100条,该执行计划实际扫描行数是200行,因为 驱动表只有100条,他会循环100次,每次循环的时候会拿关联字段 a去与 被驱动表 直接在索引树中查询,不需要 回驱动表中全表扫描。
SQL执行流程:
从表 t2 中读取一行数据(如果t2表有查询过滤条件的,会从过滤结果里取出一行数据);
从第 1 步的数据中,取出关联字段 a,到表 t1 中查找;
取出表 t1 中满足条件的行,跟 t2 中获取到的结果合并,作为结果返回给客户端;
重复上面 3 步。
上述的SQL 会扫描t2表全部数据(100行),根据t2的关联字段a,到t1表中扫描对应行数据,因为都是主键ID 具备索引,所以每行只会在t1的索引树中扫描一次,共计100行。整个过程 扫了200行。
上面所述,被驱动表的关联字段必须有索引,如果关联字段没有索引,MySQL就会执行 基于块的嵌套循环连接算法。
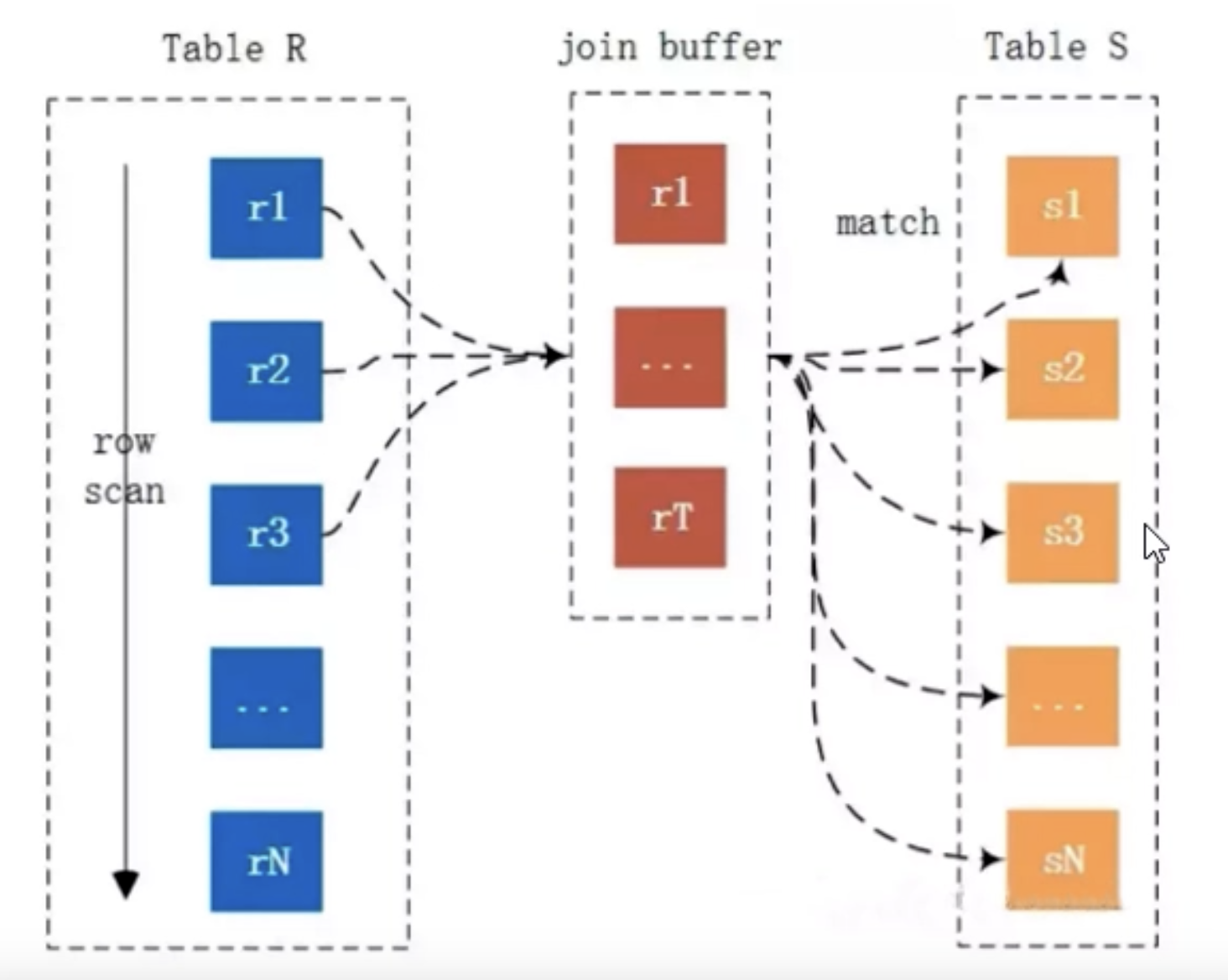
基于块的嵌套循环连接算法(Block Nested-Loop Join)
把驱动表的结果集 存入 join buffer中,然后 遍历扫描驱动表,把驱动表的每一行数据拿出来 与 join buffer进行 逐行数据对比。
案例
EXPLAIN select * from t1 inner join t2 on t1.b= t2.b;
![案例1][image-97]
注意Extra,显示 Using join buffer ,就代表使用的是基于块的循环嵌套连接。
执行流程:
- 扫描驱动表后 取出结果集(有where条件和排序的话,取过滤条件后的结果集),存入join buffer中
- 遍历扫描 t1表,把t1表的每一行数据拿出来与join buffer中的结果集进行 数据比对
- 返回满足join 条件的结果集
由于join buffer是无序的,被驱动表每次在扫描join buffer时,都需要从上到下进行比对,最坏的情况是比对100次。
此时 t1表 有1W条数据,join buffer有100条,所以t1 * join buffer ,在内存中一共需要判断 100W次(笛卡尔乘积)。
join_buffer 内存问题
在MySQL中的join_buffer_size参数默认是256KB,如果驱动表的数据太大,一次性装不下的话,MySQL会进行分段存放。
举个例子:
此时t1作为驱动表,有1W行数据,如果join buffer只能存放8K条,则会先存入8000条 先与 被驱动表进行比较,比较结束后 清空buffer,在拿驱动表剩下的2K条存入buffer,再次与被驱动表进行比较,以此类推。
被驱动表的关联字段没索引问题
如果被驱动表的关联字段没有索引,那么MySQL就会选择 BNL 算法(基于块的循环嵌套连接)。
那为什么会选择BNL而不选择 Nested-Loop Join 呢?
EXPLAIN select * from t1 inner join t2 on t1.b= t2.b;
这条SQL如果在没有索引的情况下使用NLJ,*基于笛卡尔乘积算法,需要扫描磁盘100W次(t1t2)**,非常浪费磁盘IO,查询效率很低。
而BNL会把驱动表的结果集存放到内存中(join buffer),即便在内存中进行100W次比较,但是内存的查询效率也是比磁盘快的。
综上所述:
如果被驱动表的关联字段没有索引,MySQL会选择 BNL算法,如果有索引,MySQL会选择NLJ,NLJ走索引树的查询效率比BNL快。
Join优化总结
- 被驱动表的关联字段尽量 走索引,这样就可以使用 NLJ算法
- 遵循 小表驱动大表原则
- 小表定义
- 关联的表做完过滤后(有过滤就先过滤)总数据量 小的那个表 就是小表。
- Join关联表别超过3张(阿里优化铁律)
##
3)in和exsits 优化
in
原则:小结果集驱动大结果集。
当B表结果集小于A表时,可以使用IN的方式,让小表驱动大表。
in 会先执行 子查询中的内容,在通过子查询的结果集 去驱动 A表。
1 | select * from A where id in (select id from B) |
exsits
当A表结果集小于B表时,此时不可以在用IN了,可以用exsits。
1 | select * from A where exists (select 1 from B where B.id = A.id) |
此时会拿 select * from A的结果集,循环遍历 exists 结果集。
- exists 只会返回true和false。
- 慎用exists,exists可以使用join来平替,效率没有join高。
SQL索引案例
复合索引:index(a,b,c)
where a = 3
- 走索引,字段 a
where a = 3 and b = 5
- 走索引,字段 a,b
where a = 3 and b = 5 and c = 4
- 走索引,字段 a,b,c
where b = 3
- 没走索引,索引是复合索引,这里没有满足 最左前缀原则,最左的索引是a
where b = 3 and c = 4
- 没走索引,索引是复合索引,这里没有满足 最左前缀原则,最左的索引是a
where c = 4
- 没走索引,索引是复合索引,这里没有满足 最左前缀原则,最左的索引是a和b
where a = 3 and c = 5
- 没走索引,没有中间的索引字段导致复合索引失效
where a = 3 and b > 4 and c = 5
- 没走索引,范围查询(b>4)右边的字段不走索引
where a = 3 and b like ‘kk%’ and c = 4
- 走索引,这里的like通配符在后面,这样是可以正常走索引的
where a = 3 and b like ‘%kk’ and c = 4
- 没走索引,like通配符在前面,导致索引失效(不完全正确,看是否查询的列是否都走覆盖索引,如果是的话这里会走索引)
where a = 3 and b like ‘%kk%’ and c = 4
- 没走索引,like通配符在前面,导致索引失效,(不完全正确,看是否查询的列是否都走覆盖索引,如果是的话这里会走索引)
where a = 3 and b like ‘k%kk%’ and c = 4
走索引,这里有个注意的细节就是like的字段
- b like ‘k%kk%’ ,%通配符之前k字,在MySQL底层的查询器会进行优化转义,是可以正常走索引的,这个很细节
[]: https://image.javaxing.com/document/image-23310112203903416.png
[image-2]: https://image.javaxing.com/document/image-33113201114420.png
[image-3]: https://image.javaxing.com/document/image-23314130737114.png
[image-4]: https://image.javaxing.com/document/image-23114175148129.png
[image-5]: https://image.javaxing.com/document/image-233112211831540.png
[image-6]: https://image.javaxing.com/document/image-20230113140536198.png
[image-7]: https://image.javaxing.com/document/image-20230113194152318.png
[image-8]: https://image.javaxing.com/document/image-20230114123258928.png
[image-9]: https://image.javaxing.com/document/b84fe18e1826f37de612efcdfc834dc5.png
[image-10]: https://image.javaxing.com/document/77b4bfdb49030f1cbcc681fd6cff5ab6.png
[image-11]: https://image.javaxing.com/document/image-111012264736664.png
[image-12]: https://image.javaxing.com/document/image-22121219155836287.png
[image-13]: https://image.javaxing.com/document/image-32131219155931923.png
[image-14]: https://image.javaxing.com/document/image-311219161621525.png
[image-15]: https://image.javaxing.com/document/image-33121219162049481.png
[image-16]: https://image.javaxing.com/document/image-321911162031333.png
[image-17]: https://image.javaxing.com/document/image-444221219162108064.png
[image-18]: https://image.javaxing.com/document/image-3441219165700171.png
[image-19]: https://image.javaxing.com/document/image-911219174921322.png
[image-20]: https://image.javaxing.com/document/image-4411219180514043.png
[image-21]: https://image.javaxing.com/document/image-4411219181918341.png
[image-22]: https://image.javaxing.com/document/image-299811219184927038.png
[image-23]: https://image.javaxing.com/document/image-88811220111937589.png
[image-24]: https://image.javaxing.com/document/image-2211220113654078.png
[image-25]: https://image.javaxing.com/document/image-1121220121924390.png
[image-26]: https://image.javaxing.com/document/image-99121220122553923.png
[image-27]: https://image.javaxing.com/document/image-331114151128346.png
[image-28]: https://image.javaxing.com/document/image-1130114145450418.png
[image-29]: https://image.javaxing.com/document/image-33114155027132.png
[image-30]: https://image.javaxing.com/document/image-331114165702509.png
[image-31]: https://image.javaxing.com/document/image-99810114170357306.png
[image-32]: https://image.javaxing.com/document/image-441114170527627.png
[image-33]: https://image.javaxing.com/document/image-9787810114170849103.png
[image-34]: https://image.javaxing.com/document/image-20230114175148129.png
[image-35]: https://image.javaxing.com/document/image-3011314181641345.png
[image-36]: https://image.javaxing.com/document/image-9910115153639281.png
[image-37]: https://image.javaxing.com/document/image-44115154259643.png
[image-38]: https://image.javaxing.com/document/image-488115155720991.png
[image-39]: https://image.javaxing.com/document/image-3315160029398.png
[image-40]: https://image.javaxing.com/document/image-4990115160943828.png
[image-41]: https://image.javaxing.com/document/image-33115161057408.png
[image-42]: https://image.javaxing.com/document/image-120115161856260.png
[image-43]: https://image.javaxing.com/document/image-233115161922667.png
[image-44]: https://image.javaxing.com/document/image-2215162258406.png
[image-45]: https://image.javaxing.com/document/image-23021115214017903.png
[image-46]: https://image.javaxing.com/document/image-2333214336252.png
[image-47]: https://image.javaxing.com/document/image-33315214033832.png
[image-48]: https://image.javaxing.com/document/image-33315214048543.png
[image-49]: https://image.javaxing.com/document/image-11817211616275.png
[image-50]: https://image.javaxing.com/document/image-11123123123.png
[image-51]: https://image.javaxing.com/document/image-244118173305835.png
[image-52]: https://image.javaxing.com/document/image-49918173814120.png
[image-53]: https://image.javaxing.com/document/image-33118173857076.png
[image-54]: https://image.javaxing.com/document/image-330132400709.png
[image-55]: https://image.javaxing.com/document/image-2111110132311484.png
[image-56]: https://image.javaxing.com/document/image-23310155410153.png
[image-57]: https://image.javaxing.com/document/image-31555168354.png
[image-58]: https://image.javaxing.com/document/image-444118180938002.png
[image-59]: https://image.javaxing.com/document/image-88120181539569.png
[image-60]: https://image.javaxing.com/document/image-449121165001688.png
[image-61]: https://image.javaxing.com/document/image-2991121170345789.png
[image-62]: https://image.javaxing.com/document/image-988122112118536.png
[image-63]: https://image.javaxing.com/document/image-33188122143240681.png
[image-64]: https://image.javaxing.com/document/image-3388122143835659.png
[image-65]: https://image.javaxing.com/document/image-33188122143642313.png
[image-66]: https://image.javaxing.com/document/image-31880122144925633.png
[image-67]: https://image.javaxing.com/document/image-33122145512171.png
[image-68]: https://image.javaxing.com/document/image-203330122152318919.png
[image-69]: https://image.javaxing.com/document/image-2111122152357501.png
[image-70]: https://image.javaxing.com/document/image-28812153420540.png
[image-71]: https://image.javaxing.com/document/image-4491122155314394.png
[image-72]: https://image.javaxing.com/document/image-29878178781.png
[image-73]: https://image.javaxing.com/document/image-2878183103456906.png
[image-74]: https://image.javaxing.com/document/image-1278123104431894.png
[image-75]: https://image.javaxing.com/document/image-338781125190928371.png
[image-76]: https://image.javaxing.com/document/image-233113150503841.png
[image-77]: https://image.javaxing.com/document/image-2011123150536680.png
[image-78]: https://image.javaxing.com/document/image-23315104314926.png
[image-79]: https://image.javaxing.com/document/image-2035235741316.png
[image-80]: https://image.javaxing.com/document/image-23333175640577.png
[image-81]: https://image.javaxing.com/document/image-191881815947641.png
[image-82]: https://image.javaxing.com/document/image-998989717731.png
[image-83]: https://image.javaxing.com/document/image-2333131324773.png
[image-84]: https://image.javaxing.com/document/image-244123181753207.png
[image-85]: https://image.javaxing.com/document/image-444123182211535.png
[image-86]: https://image.javaxing.com/document/image-3313185933631.png
[image-87]: https://image.javaxing.com/document/image-244185949513.png
[image-88]: https://image.javaxing.com/document/%E6%9C%AA%E5%91%BD%E5%90%8D%E6%96%87%E4%BB%B6.png
[image-89]: https://image.javaxing.com/document/image-4410124220437345.png
[image-90]: https://image.javaxing.com/document/image-244124220450050.png
[image-91]: https://image.javaxing.com/document/image-2441134421478.png
[image-92]: https://image.javaxing.com/document/image-3334318998.png
[image-93]: https://image.javaxing.com/document/image-44440230125135511348.png
[image-94]: https://image.javaxing.com/document/image-41182235133305.png
[image-95]: https://image.javaxing.com/document/image-233520661319.png
[image-96]: https://image.javaxing.com/document/image-233143136198.png
[image-97]: https://image.javaxing.com/document/image-23315155010029.png




